

شبکه عصبی بازگشتی (RNNs) دستهای از شبکههای عصبی هستند که برای پردازش دادههای متوالی از طریق حفظ اطلاعات مراحل قبلی طراحی شدهاند. آنها بهویژه برای وظایفی که در آنها زمینه (context) و ترتیب اهمیت دارند، مؤثر هستند.
- طراحی شده برای دادههای متوالی و زمانی
- حفظ حافظهای از ورودیهای گذشته
- کاربرد گسترده در پردازش زبان طبیعی (NLP)، پیشبینی و وظایف مربوط به گفتار
تصور کنید در حال خواندن یک جمله هستید و سعی میکنید کلمه بعدی را پیشبینی کنید؛ شما فقط به کلمه فعلی تکیه نمیکنید، بلکه کلماتی را که پیش از آن آمدهاند نیز به خاطر میآورید. RNNها به روشی مشابه با «بهخاطر سپردن» اطلاعات گذشته عمل میکنند، یعنی تمام کلمات قبلی را برای انتخاب محتملترین کلمه بعدی در نظر میگیرند. این حافظه از مراحل قبلی به شبکه کمک میکند تا زمینه را درک کرده و پیشبینیهای بهتری انجام دهد.
در این مطلب از بخش آموزش هوش مصنوعی، به بررسی نحوه عملکرد شبکههای عصبی بازگشتی (RNN)، جایگاه آنها در پردازش دادههای متوالی و پیشنیازهای درک این معماری میپردازیم.
چرا شبکه عصبی بازگشتی (RNN) برای هوش مصنوعی حیاتی هستند؟
شبکههای عصبی بازگشتی یا RNNها مانند حافظه کوتاهمدت برای کامپیوترها عمل میکنند. برخلاف شبکههای معمولی که هر ورودی را به صورت مستقل و جداگانه پردازش میکنند، این مدلها به یاد میآورند که در مراحل قبلی چه اتفاقی افتاده است؛ درست مثل شما که هنگام خواندن این جمله، کلمات ابتدایی را فراموش نمیکنید تا بتوانید معنای کل مطلب را درک کنید.
این توانایی «بهخاطر سپردن» باعث شده تا RNNها در دنیای امروز کاربردهای شگفتانگیزی در هوش مصنوعی و پردازش زبان طبیعی داشته باشند. از ترجمه همزمان زبانها و پیشنهاد کلمات در کیبورد گوشی گرفته تا تشخیص صدای شما در دستیارهای هوشمند و پیشبینی نوسانات بازار سهام، همگی به لطف این ساختار هوشمندانه انجام میشوند که مفهوم زمان و ترتیب را به خوبی درک میکند.
اجزای کلیدی RNNها
بهطور کلی دو جزء اصلی در RNNها وجود دارد که در ادامه به بررسی آنها میپردازیم.
۱. نورونهای بازگشتی
واحد پردازشی اصلی در RNN، یک واحد بازگشتی (Recurrent Unit) است. آنها یک وضعیت پنهان (hidden state) را نگه میدارند که اطلاعات مربوط به ورودیهای قبلی در یک توالی را حفظ میکند. واحدهای بازگشتی میتوانند با بازگرداندن وضعیت پنهان خود، اطلاعات مراحل قبلی را «به خاطر بسپارند» که این امر به آنها اجازه میدهد وابستگیهای موجود در طول زمان را استخراج کنند.
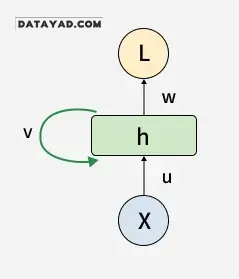
۲. باز کردن شبکه RNN
باز کردن (Unfolding) یا Unrolling در RNN فرآیند گسترش ساختار بازگشتی در طول گامهای زمانی است. در طول فرآیند باز کردن، هر گام از توالی بهصورت یک لایه مجزا در یک سری نمایش داده میشود که نشاندهنده چگونگی جریان اطلاعات در هر گام زمانی است.
این باز کردن شبکه، پسانتشار در زمان (BPTT) را امکانپذیر میکند؛ یک فرآیند یادگیری که در آن خطاها در طول گامهای زمانی منتشر میشوند تا وزنهای شبکه تنظیم شوند و توانایی RNN برای یادگیری وابستگیها در دادههای توالیمحور بهبود یابد.
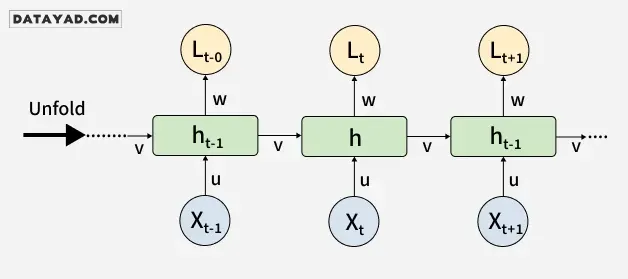
معماری شبکه عصبی بازگشتی
RNNها در ساختارهای ورودی و خروجی با سایر معماریهای یادگیری عمیق شباهتهایی دارند، اما در نحوه جریان اطلاعات از ورودی به خروجی تفاوت قابلتوجهی دارند. برخلاف شبکههای عصبی عمیق سنتی که در آنها هر لایه متراکم (dense layer) دارای ماتریسهای وزن متمایزی است، RNNها از وزنهای مشترک در طول گامهای زمانی استفاده میکنند که به آنها اجازه میدهد اطلاعات را در طول توالیها به خاطر بسپارند.
در RNNها وضعیت پنهان Hi برای هر ورودی Xi محاسبه میشود تا وابستگیهای توالی حفظ شود. محاسبات از این فرمولهای اصلی پیروی میکنند:
۱. محاسبه وضعیت پنهان:
![]()
در اینجا:
- h نشاندهنده وضعیت پنهان فعلی است.
- σ نشاندهنده تابع فعالسازی tanh است.
- U و W ماتریسهای وزن هستند.
- B بایاس (bias) است.
۲. محاسبه خروجی:
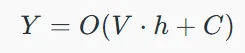
خروجی Y از طریق اعمال یک تابع فعالسازی O بر روی وضعیت پنهان وزندهی شده محاسبه میشود که در آن V و C نشاندهنده وزنها و بایاس هستند.
۳. تابع کلی:
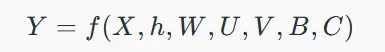
این تابع کل عملیات RNN را تعریف میکند که در آن ماتریس وضعیت S شامل هر المان si است که نشاندهنده وضعیت شبکه در هر گام زمانی i میباشد.
نحوه عملکرد شبکه عصبی بازگشتی
در هر گام زمانی، RNNها واحدها را با یک تابع فعالسازی ثابت پردازش میکنند. این واحدها دارای یک وضعیت پنهان داخلی هستند که به عنوان حافظه عمل کرده و اطلاعات گامهای زمانی قبلی را حفظ میکند. این حافظه به شبکه اجازه میدهد تا دانش گذشته را ذخیره کرده و بر اساس ورودیهای جدید سازگار شود.
بهروزرسانی وضعیت پنهان در RNNها
وضعیت پنهان فعلی ht به وضعیت قبلی ht−1 و ورودی فعلی xt بستگی دارد و با استفاده از روابط زیر محاسبه میشود:
۱. بهروزرسانی وضعیت:
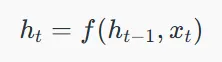
که در آن:
- ht وضعیت فعلی است
- ht−1 وضعیت قبلی است
- xt ورودی در گام زمانی فعلی است
۲. اعمال تابع فعالسازی:
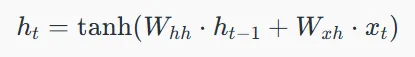
در اینجا، Whh ماتریس وزن برای نورون بازگشتی و Wxh ماتریس وزن برای نورون ورودی است.
۳. محاسبه خروجی:
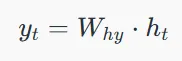
که در آن yt خروجی و Why وزن در لایه خروجی است.
این پارامترها با استفاده از پسانتشار بهروزرسانی میشوند. با این حال، از آنجایی که RNN روی دادههای توالیمحور کار میکند، در اینجا از یک نسخه بهروزرسانیشده از پسانتشار استفاده میکنیم که به عنوان پسانتشار در زمان (backpropagation through time) شناخته میشود.
پسانتشار در زمان (BPTT) در RNNها
از آنجایی که RNNها دادههای توالیمحور را پردازش میکنند، از پسانتشار در زمان (BPTT) برای بهروزرسانی پارامترهای شبکه استفاده میشود. تابع زیان L(θ) به وضعیت پنهان نهایی h3 بستگی دارد و هر وضعیت پنهان به وضعیتهای قبلی متکی است که یک زنجیره وابستگی متوالی را تشکیل میدهند:
h3 به h2، h2 به h1، …، h1 به h0 وابسته است.
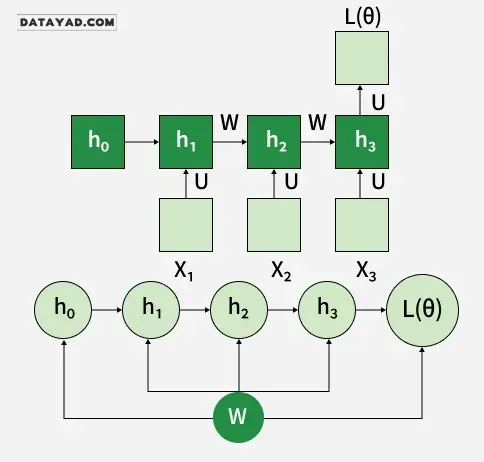
در BPTT، گرادیانها در طول هر گام زمانی به عقب منتشر میشوند. این کار برای بهروزرسانی پارامترهای شبکه بر اساس وابستگیهای زمانی ضروری است.
۱. محاسبه سادهسازیشده گرادیان:
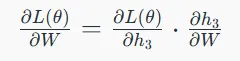
۲. مدیریت وابستگیها در لایهها: هر وضعیت پنهان بر اساس وابستگیهای خود بهروزرسانی میشود:
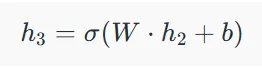
سپس گرادیان برای هر وضعیت با در نظر گرفتن وابستگیها به وضعیتهای پنهان قبلی محاسبه میشود.
۳. محاسبه گرادیان با بخشهای صریح و ضمنی: گرادیان به بخشهای صریح و ضمنی تقسیم میشود تا مجموع مسیرهای غیرمستقیم از هر وضعیت پنهان به وزنها را محاسبه کند.
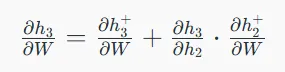
۴. عبارت نهایی گرادیان: مشتق نهایی تابع زیان نسبت به ماتریس وزن W محاسبه میشود:
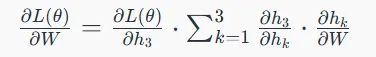
این فرآیند تکرار شونده، ماهیت اصلی پسانتشار در زمان است.
انواع شبکه عصبی بازگشتی
بر اساس تعداد ورودیها و خروجیها در شبکه، چهار نوع RNN وجود دارد:
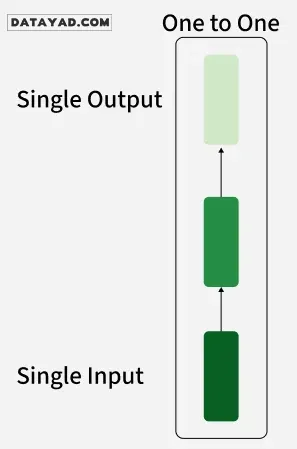
۱. RNN یکبهیک (One-to-One)
این سادهترین نوع معماری شبکه عصبی است که در آن یک ورودی واحد و یک خروجی واحد وجود دارد. این مدل برای وظایف طبقهبندی ساده مانند طبقهبندی باینری که در آن دادههای توالیمحور دخالتی ندارند، استفاده میشود.
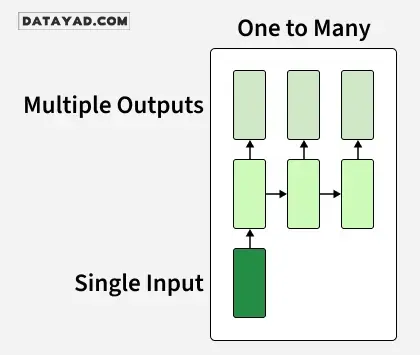
۲. RNN یکبهچند (One-to-Many)
در یک RNN یکبهچند، شبکه یک ورودی واحد را برای تولید چندین خروجی در طول زمان پردازش میکند. این نوع در وظایفی مفید است که در آن یک ورودی، توالیای از پیشبینیها (خروجیها) را ایجاد میکند. برای مثال، در شرحنویسی تصویر، یک تصویر واحد میتواند به عنوان ورودی برای تولید توالیای از کلمات به عنوان شرح استفاده شود.
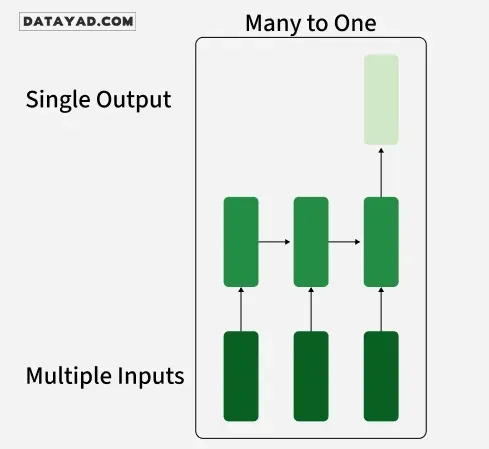
۳. RNN چندبهیک (Many-to-One)
RNN چندبهیک توالیای از ورودیها را دریافت کرده و یک خروجی واحد تولید میکند. این نوع زمانی مفید است که برای انجام یک پیشبینی، به بافتار کلی توالی ورودی نیاز باشد. در تحلیل احساسات، مدل توالیای از کلمات (مانند یک جمله) را دریافت کرده و یک خروجی واحد مانند مثبت، منفی یا خنثی تولید میکند.
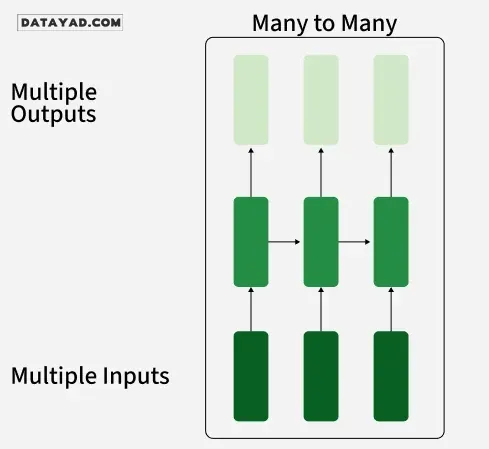
۴. RNN چندبهچند (Many-to-Many)
نوع RNN چندبهچند توالیای از ورودیها را پردازش کرده و توالیای از خروجیها را تولید میکند. در وظیفه ترجمه زبان، توالیای از کلمات در یک زبان به عنوان ورودی داده میشود و توالی متناظر در زبانی دیگر به عنوان خروجی تولید میشود.
انواع مختلف شبکه عصبی بازگشتی (RNNs)
چندین نوع مختلف از RNNها وجود دارد که هر کدام برای رفع چالشهای خاص یا بهینهسازی برای وظایف معینی طراحی شدهاند:
۱. RNN ساده (Vanilla RNN)
این سادهترین شکل RNN است که از یک لایه پنهان واحد تشکیل شده و در آن وزنها در طول گامهای زمانی به اشتراک گذاشته میشوند. RNNهای ساده برای یادگیری وابستگیهای کوتاهمدت مناسب هستند، اما با مشکل محو شدن گرادیان محدود میشوند که مانع از یادگیری توالیهای طولانی میشود.
۲. RNNهای دوطرفه (Bidirectional RNNs)
RNNهای دوطرفه ورودیها را در هر دو جهت رفت و برگشت (forward و backward) پردازش میکنند و بافتار (context) گذشته و آینده را برای هر گام زمانی استخراج میکنند. این معماری برای وظایفی که در آنها کل توالی در دسترس است، مانند تشخیص موجودیتهای نامگذاریشده و پاسخگویی به سوالات، ایدهآل است.
۳. شبکههای حافظه طولانی کوتاهمدت (LSTMs)
شبکههای حافظه طولانی کوتاهمدت (LSTMs) یک مکانیسم حافظه را برای غلبه بر مشکل محو شدن گرادیان معرفی میکنند. هر سلول LSTM دارای سه دروازه است:
- دروازه ورودی (Input Gate): کنترل میکند که چه مقدار اطلاعات جدید باید به وضعیت سلول اضافه شود.
- دروازه فراموشی (Forget Gate): تصمیم میگیرد که کدام اطلاعات گذشته باید دور ریخته شود.
- دروازه خروجی (Output Gate): تنظیم میکند که چه اطلاعاتی باید در گام فعلی خروجی داده شود. این حافظه انتخابی، LSTMs را قادر میسازد تا وابستگیهای طولانیمدت را مدیریت کنند و آنها را برای وظایفی که در آنها بافتار اولیه حیاتی است، ایدهآل میسازد.
۴. واحدهای بازگشتی دروازهای (GRUs)
واحدهای بازگشتی دروازهای (GRUs) با ترکیب دروازههای ورودی و فراموشی در یک دروازه بهروزرسانی واحد و سادهسازی مکانیسم خروجی، مدل LSTMs را سادهتر میکنند. این طراحی از نظر محاسباتی کارآمد است، اغلب عملکردی مشابه LSTMs دارد و در وظایفی که سادگی و آموزش سریعتر مزیت محسوب میشود، مفید است.
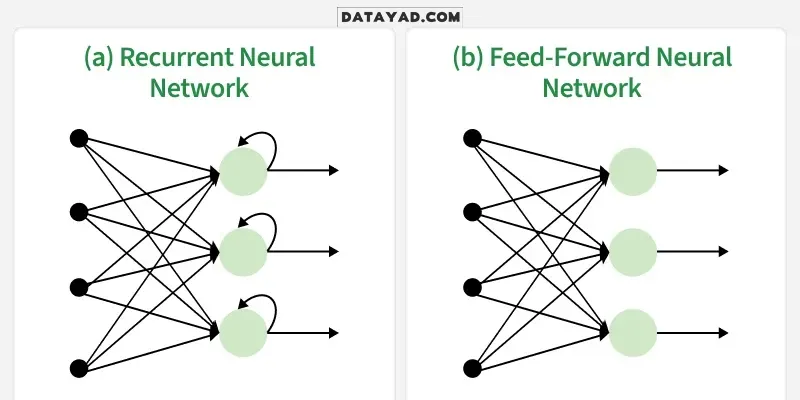
RNN در مقابل شبکههای عصبی Feedforward
شبکههای عصبی Feedforward
- دادهها را در یک جهت واحد، از ورودی به خروجی پردازش میکنند.
- اطلاعات ورودیهای قبلی را ذخیره نمیکنند.
- برای وظایفی با دادههای مستقل، مانند طبقهبندی تصویر مناسب هستند.
- به دلیل عدم وجود حافظه، در پردازش دادههای توالیمحور عملکرد ضعیفی دارند.
شبکههای عصبی بازگشتی (RNNs)
- شامل حلقههای بازخوردی هستند که اطلاعات را از گامهای قبلی منتقل میکنند.
- حافظهای از ورودیهای گذشته را از طریق وضعیتهای پنهان (hidden states) حفظ میکنند.
- برای دادههای توالیمحور و وابسته به زمان طراحی شدهاند.
- برای وظایفی که بافتار (context) در آنها اهمیت دارد، مانند تحلیل متن و سریهای زمانی، مؤثر هستند.
پیادهسازی یک تولیدکننده متن با استفاده از شبکه عصبی بازگشتی (RNN)
در این بخش، ما با استفاده از شبکه عصبی بازگشتی (RNN) در TensorFlow و Keras، یک تولیدکننده متن مبتنی بر کاراکتر میسازیم. ما یک RNN را پیادهسازی میکنیم که الگوها را از یک توالی متنی یاد میگیرد تا متن جدید را به صورت کاراکتر به کاراکتر تولید کند.
۱. وارد کردن کتابخانههای مورد نیاز
ما با وارد کردن کتابخانههای ضروری برای مدیریت دادهها و ساخت شبکه عصبی شروع میکنیم.
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import SimpleRNN, Dense
۲. تعریف متن ورودی و آمادهسازی مجموعه کاراکترها
ما متن ورودی را تعریف کرده و کاراکترهای منحصربهفرد در متن را که برای مدلمان کدگذاری خواهیم کرد، شناسایی میکنیم.
text = "This is DataYad a software training institute"
chars = sorted(list(set(text)))
char_to_index = {char: i for i, char in enumerate(chars)}
index_to_char = {i: char for i, char in enumerate(chars)}
۳. ایجاد توالیها و برچسبها
برای آموزش RNN، ما به توالیهایی با طول ثابت (seq_length) و کاراکتر بعد از هر توالی به عنوان برچسب نیاز داریم.
seq_length = 3
sequences = []
labels = []
for i in range(len(text) - seq_length):
seq = text[i:i + seq_length]
label = text[i + seq_length]
sequences.append([char_to_index[char] for char in seq])
labels.append(char_to_index[label])
X = np.array(sequences)
y = np.array(labels)
۴. تبدیل توالیها و برچسبها به کدگذاری وان-هات (One-Hot Encoding)
برای آموزش، ما X و y را به تنسورهای کدگذاریشده وان-هات تبدیل میکنیم.
X_one_hot = tf.one_hot(X, len(chars)) y_one_hot = tf.one_hot(y, len(chars))
۵. ساخت مدل RNN
ما یک مدل RNN ساده با یک لایه پنهان شامل ۵۰ واحد و یک لایه خروجی Dense با فعالساز softmax میسازیم.
model = Sequential() model.add(SimpleRNN(50, input_shape=(seq_length, len(chars)), activation='relu')) model.add(Dense(len(chars), activation='softmax'))
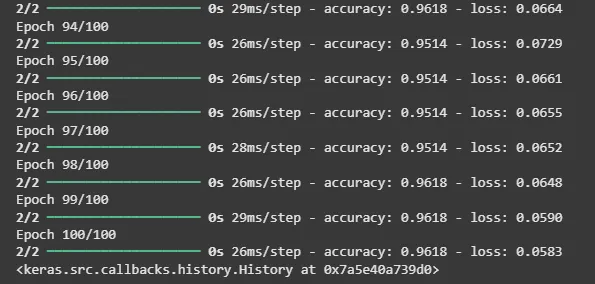
۶. کامپایل و آموزش مدل
ما مدل را با استفاده از تابع زیان categorical_crossentropy کامپایل کرده و آن را برای ۱۰۰ دوره (epoch) آموزش میدهیم.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_one_hot, y_one_hot, epochs=100)
خروجی:
۷. تولید متن جدید با استفاده از مدل آموزشدیده
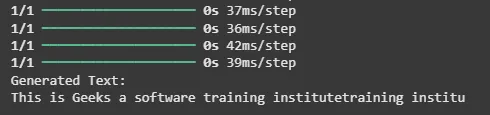
پس از آموزش، ما از یک توالی اولیه برای تولید متن جدید به صورت کاراکتر به کاراکتر استفاده میکنیم.
start_seq = "This is G"
generated_text = start_seq
for i in range(50):
x = np.array([[char_to_index[char] for char in generated_text[-seq_length:]]])
x_one_hot = tf.one_hot(x, len(chars))
prediction = model.predict(x_one_hot)
next_index = np.argmax(prediction)
next_char = index_to_char[next_index]
generated_text += next_char
print("Generated Text:")
print(generated_text)
خروجی:
مزایا شبکه عصبی بازگشتی
- حافظه توالیمحور: RNNها اطلاعات ورودیهای قبلی را حفظ میکنند که آنها را برای پیشبینیهای سری زمانی، جایی که دادههای گذشته حیاتی هستند، ایدهآل میسازد.
- همسایگیهای پیکسلی بهبودیافته: RNNها میتوانند با لایههای کانولوشنی ترکیب شوند تا همسایگیهای پیکسلی گستردهتری را ثبت کنند و عملکرد در پردازش دادههای تصویری و ویدئویی را بهبود بخشند.
محدودیتهای شبکه عصبی بازگشتی
در حالی که RNNها در مدیریت دادههای متوالی عالی عمل میکنند، با دو چالش اصلی در آموزش مواجه هستند، یعنی مشکل محوشدگی گرادیان و انفجار گرادیان:
- محوشدگی گرادیان (Vanishing Gradient): در طول پسانتشار، با عبور گرادیانها از هر گام زمانی، مقدار آنها کاهش مییابد که منجر به بهروزرسانیهای حداقلی در وزنها میشود. این مسئله توانایی RNN را در یادگیری وابستگیهای طولانیمدت، که برای کارهایی مانند ترجمه زبان حیاتی است، محدود میکند.
- انفجار گرادیان (Exploding Gradient): گاهی اوقات گرادیانها بهطور غیرقابلکنترلی رشد میکنند و باعث بهروزرسانیهای بیش از حد بزرگ در وزنها میشوند که ثبات آموزش را از بین میبرد.
کاربردهای RNN ها
- پیشبینی سریهای زمانی: RNNها در وظایف پیشبینی، مانند پیشبینی بازار سهام و پیشبینی وضعیت آبوهوا عالی عمل میکنند.
- پردازش زبان طبیعی (NLP): RNNها در وظایف NLP مانند مدلسازی زبان، تحلیل احساسات و ترجمه ماشینی نقشی اساسی دارند.
- تشخیص گفتار: RNNها الگوهای زمانی را در دادههای گفتاری ثبت میکنند و به تبدیل گفتار به متن و دیگر کاربردهای مرتبط با صدا کمک میکنند.
- پردازش تصویر و ویدئو: RNNها زمانی که با لایههای کانولوشنی ترکیب شوند، به تحلیل توالیهای ویدئویی، حالات چهره و تشخیص حرکات (Gesture Recognition) کمک میکنند.
سوالات متداول در مورد شبکه عصبی بازگشتی
تفاوت اصلی RNN با شبکههای عصبی معمولی چیست؟
تفاوت اصلی در وجود «حافظه» است؛ RNNها اطلاعات مراحل قبلی را برای پردازش مرحله فعلی نگه میدارند، در حالی که شبکههای معمولی هر داده را بدون توجه به ترتیب آن و به صورت مستقل پردازش میکنند.
مشکل محوشدگی گرادیان در RNN به چه معناست؟
این مشکل زمانی رخ میدهد که شبکه در توالیهای طولانی، اطلاعات دورتر را فراموش میکند، زیرا سیگنالهای یادگیری (گرادیانها) در طول مسیر بازگشت به عقب، به مرور کوچک شده و عملاً به صفر میرسند.
آیا مدلهای LSTM و GRU هم نوعی RNN هستند؟
بله، این دو مدل در واقع نسخههای بهبودیافته و پیشرفتهتر RNN ساده هستند که با استفاده از مکانیزم دروازهها (Gates)، مشکل حافظه کوتاهمدت و مدیریت دادههای طولانی را حل کردهاند.
چرا از RNN در پردازش متن (NLP) استفاده میشود؟
در زبان، ترتیب کلمات معنا را میسازد. RNNها به دلیل ساختار بازگشتی، قادرند ترتیب و بافتار جملات را درک کنند که برای کارهایی مثل ترجمه و تحلیل لحن ضروری است.
مسیر تخصص در پیاده سازی شبکه های عصبی
درک شبکههای عصبی بازگشتی (RNN) و قدرت آنها در پردازش دادههای متوالی، تنها آغاز مسیر شما برای تسلط بر دنیای پیچیده هوش مصنوعی است. همانطور که در این مقاله مشاهده کردید، پیادهسازی این مدلها نیازمند دانش عمیق در برنامهنویسی پایتون، ریاضیات پایه و مفاهیم پیشرفته یادگیری عمیق است تا بتوانید از چالشهایی مانند محوشدگی گرادیان عبور کرده و پروژههایی واقعی در سطح استانداردهای بازار کار خلق کنید.
اگر تصمیم دارید فراتر از تئوری بروید و به یک متخصص همهفنحریف در حوزههای هوش مصنوعی، پردازش زبان طبیعی و بینایی کامپیوتر تبدیل شوید، دوره جامع هوش مصنوعی شما را از صفر مطلق تا اجرای پیشرفتهترین پروژههای هوش مصنوعی همراهی میکند. این فرصتی برای یادگیری جامع و ساختن رزومهای قدرتمند جهت ورود به بازار کار تخصصی AI است.
- تسلط بر پایتون تخصصی، تحلیل داده، ریاضیات و آمار-احتمال، یادگیری ماشین و یادگیری عمیق برای پیادهسازی مدلهای هوشمند
- آموزش پروژهمحور پردازش زبان طبیعی و مدل های بزرگ زبانی و همچنین آموزش پردازش تصویر و بینایی کامپیوتر با رویکرد ورود به دنیای حرفهای و کسب درآمد



















