

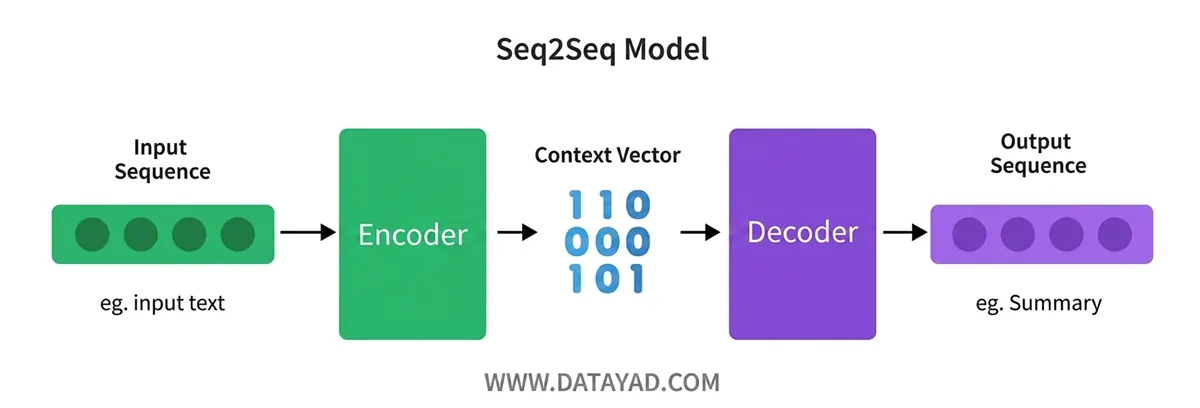
مدلهای توالی به توالی (Seq2Seq) شبکههای عصبی قدرتمندی بر پایه معماری انکودر-دیکودر (Encoder-Decoder) هستند که با هدف تبدیل یک توالی از دادهها به توالی دیگر طراحی شدهاند. یکی از بارزترین ویژگیهای این مدلها، توانایی مدیریت و پردازش توالیهای ورودی و خروجی با طولهای متغیر و متفاوت است؛ به طوری که مدل میتواند یک توالی ورودی را دریافت و تحلیل کرده و سپس توالی خروجی متناظر آن را تولید کند.
در این مطلب از بخش آموزش هوش مصنوعی به بررسی دقیقتر این مدلها میپردازیم که کاربردهای گسترده و حیاتی در حوزههایی نظیر پردازش زبان طبیعی (NLP)، ترجمه ماشینی، تشخیص گفتار و پیشبینی سریهای زمانی دارند.
هم ورودی و هم خروجی به عنوان توالیهایی با طولهای متغیر در نظر گرفته میشوند و مدل از دو بخش تشکیل شده است:
۱. انکودر (Encoder):
- توالی ورودی را توکن به توکن پردازش میکند.
- کل توالی را به یک بردار بافت (context vector) با طول ثابت (یا مجموعهای از حالتهای پنهان) کدگذاری میکند که اطلاعات مهم ورودی را خلاصه میکند.
۲. دیکودر (Decoder):
- بردار بافت را به عنوان ورودی دریافت میکند.
- توالی خروجی را هر بار یک توکن تولید میکند و هر توکن را بر اساس بردار بافت و توکنهای قبلاً تولید شده پیشبینی میکند.
این مدل انکودر-دیکودر معمولاً در وظایفی استفاده میشود که نیاز به نگاشت توالیهایی با طولهای متغیر وجود دارد، مانند تبدیل یک جمله از یک زبان به زبان دیگر یا پیشبینی توالی رویدادهای آینده بر اساس دادههای گذشته، یعنی پیشبینی سریهای زمانی.
چرا مدلهای Seq2Seq در هوش مصنوعی مدرن حیاتی هستند؟
مدلهای Seq2Seq در واقع مانند یک مترجم هوشمند عمل میکنند که میتوانند ساختارهای پیچیده زبان انسانی یا دادههای زمانی را درک کنند. این مدلها به جای نگاه کردن به کلمات به صورت جداگانه، کل مفهوم یک توالی را درک کرده و آن را به شکلی جدید بازسازی میکنند، که این امر باعث میشود در وظایفی مانند ترجمه گوگل یا چتباتهای هوش مصنوعی بسیار دقیق عمل کنند.
به زبان ساده، این معماری با استفاده از دو بخش مجزا، ابتدا ورودی را به یک «ایده کلی» تبدیل کرده و سپس از آن ایده، خروجی مورد نظر را استخراج میکند. این انعطافپذیری در مدیریت طولهای متفاوت ورودی و خروجی، انقلابی در پردازش زبان طبیعی و تحلیل دادههای متوالی ایجاد کرده است. اگر در مورد مفاهیم هوش مصنوعی سوالاتی در ذهن دارید حتما مقاله هوش مصنوعی چیست؟ را مطالعه بفرمایید.
مدل Seq2Seq با استفاده از RNNها
در سادهترین مدل Seq2Seq، از RNNها در هر دو بخش انکودر و دیکودر برای پردازش دادههای توالیمحور استفاده میشود. برای یک توالی ورودی داده شده (x1, x2, …, xT)، یک RNN توالیای از خروجیها (y1, y2, …, yT) را از طریق محاسبات تکرارشونده بر اساس معادله زیر تولید میکند:
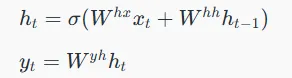
در اینجا
- ht نشاندهنده حالت پنهان در گام زمانی t است.
- xt نشاندهنده ورودی در گام زمانی t است.
- Whx و Wyh نشاندهنده ماتریسهای وزن هستند.
- ht−1 نشاندهنده حالت پنهان از گام زمانی قبلی (t-1) است.
- σ نشاندهنده تابع فعالساز است (معمولاً tanh برای حالتهای پنهان RNN).
- yt نشاندهنده خروجی در گام زمانی t است.
محدودیتهای RNNهای ساده:
- RNNهای ساده به دلیل مشکل محو شدن گرادیان (vanishing gradient)، با وابستگیهای طولانیمدت دست و پنجه نرم میکنند.
- برای غلبه بر این مشکل، انواع پیشرفته RNN مانند LSTM یا GRU در مدلهای Seq2Seq استفاده میشوند. این معماریها در ثبت وابستگیهای دوربرد عملکرد بهتری دارند.
مدل Seq2Seq چگونه کار میکند؟
یک مدل (Seq2Seq) از دو مرحله اصلی تشکیل شده است: Encoding توالی ورودی و Decoding آن به یک توالی خروجی.
۱. Encoding توالی ورودی
- انکودر، توالی ورودی را توکن به توکن پردازش کرده و در هر گام، وضعیت داخلی (internal state) خود را بهروزرسانی میکند.
- پس از پردازش کل توالی، انکودر یک بردار بافت (context vector) تولید میکند؛ یعنی یک نمایش با طول ثابت که اطلاعات مهم ورودی را خلاصه میکند.
۲. Decoding توالی خروجی
دیکودر بردار بافت را دریافت کرده و توالی خروجی را هر بار یک توکن تولید میکند. برای مثال، در ترجمه ماشینی:
- ورودی: “I am learning”
- خروجی: “Je suis apprenant”
هر توکن بر اساس بردار بافت و توکنهای تولید شده قبلی پیشبینی میشود.
۳. اجبار معلم (Teacher Forcing)
در طول آموزش، معمولاً از تکنیک «اجبار معلم» (Teacher Forcing) استفاده میشود. در این روش، به جای اینکه پیشبینی قبلیِ خودِ دیکودر به عنوان ورودی بعدی به آن داده شود، توکن هدف واقعی از دادههای آموزشی ارائه میشود.
مزایا:
- تسریع فرآیند آموزش
- کاهش انتشار خطا
تکنیک Teacher forcing فقط در طول آموزش استفاده میشود و در زمان استنتاج (inference)، جایی که مدل به پیشبینیهای قبلی خود متکی است، کاربردی ندارد.
پیادهسازی گامبهگام Seq2Seq
گام ۱: وارد کردن کتابخانهها
ما کتابخانه pytorch را وارد خواهیم کرد.
import torch import torch.nn as nn import torch.nn.functional as F
گام ۲: انکودر (Encoder)
ما موارد زیر را تعریف خواهیم کرد:
- هر توکن ورودی به یک بردار متراکم (امبدینگ) تبدیل میشود.
- واحد GRU توالی را توکن به توکن پردازش کرده و حالت پنهان خود را بهروزرسانی میکند.
- آخرین حالت پنهان به عنوان بردار بافت (context vector) بازگردانده میشود که خلاصهای از توالی ورودی است.
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hidden_dim)
def forward(self, src):
embedded = self.embedding(src)
outputs, hidden = self.rnn(embedded)
return hidden
گام ۳: دیکودر (Decoder)
ما دیکودر را تعریف خواهیم کرد:
- توکن ورودی فعلی را دریافت کرده و آن را به یک امبدینگ تبدیل میکند.
- GRU از حالت پنهان قبلی (یا در ابتدا از بردار بافت) برای محاسبه حالت پنهان جدید استفاده میکند.
- خروجی از یک لایه خطی عبور میکند تا احتمالات توکن پیشبینیشده بهدست آید.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden):
input = input.unsqueeze(0)
embedded = self.embedding(input)
output, hidden = self.rnn(embedded, hidden)
prediction = self.fc(output.squeeze(0))
return prediction, hidden
گام ۴: مدل Seq2Seq با اجبار معلم (Teacher Forcing)
اندازه بچ و اندازه واژگان (Batch size & vocab size): از ورودی و دیکودر استخراج میشوند.
کدگذاری (Encoding): توالی ورودی ← انکودر ← بردار بافت (پنهان).
توکن شروع: مقداردهی اولیه دیکودر با توکن ۰.
حلقه روی max_len:
- دیکودر توکن بعدی را پیشبینی میکند.
- top1 ← توکنی با بیشترین احتمال.
- افزودن top1 به خروجیها.
اجبار معلم (Teacher forcing): گاهی اوقات به جای پیشبینی، توکن هدف واقعی به عنوان ورودی داده میشود.
بازگرداندن پیشبینیها: توالی بههمپیوسته از شناسههای توکن (token IDs).
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg=None, max_len=10, teacher_forcing_ratio=0.5):
batch_size = src.shape[1]
trg_vocab_size = self.decoder.fc.out_features
outputs = []
hidden = self.encoder(src)
input = torch.zeros(batch_size, dtype=torch.long).to(self.device)
for t in range(max_len):
output, hidden = self.decoder(input, hidden)
top1 = output.argmax(1)
outputs.append(top1.unsqueeze(0))
if trg is not None and t < trg.shape[0] and torch.rand(1).item() < teacher_forcing_ratio:
input = trg[t]
else:
input = top1
outputs = torch.cat(outputs, dim=0)
return outputs
گام ۵: مثال استفاده همراه با خروجیها
تست با مثال،
- src: شناسههای توکن ورودی تصادفی.
- trg: شناسههای توکن هدف تصادفی (استفاده شده برای اجبار معلم).
- outputs: شناسههای توکن پیشبینیشده برای هر توالی.
- .T: ترانهاده (transpose) برای نمایش توالیهای بچ به صورت سطر.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
VOCAB_SIZE = 10
EMB_DIM = 8
HID_DIM = 16
SEQ_LEN = 5
BATCH_SIZE = 2
enc = Encoder(VOCAB_SIZE, EMB_DIM, HID_DIM)
dec = Decoder(VOCAB_SIZE, EMB_DIM, HID_DIM)
model = Seq2Seq(enc, dec, device).to(device)
src = torch.randint(1, VOCAB_SIZE, (SEQ_LEN, BATCH_SIZE)).to(device)
trg = torch.randint(1, VOCAB_SIZE, (SEQ_LEN, BATCH_SIZE)).to(device)
outputs = model(src, trg, max_len=SEQ_LEN, teacher_forcing_ratio=0.7)
print("Source sequence (input tokens):")
print(src.T)
print("\nTarget sequence (true tokens):")
print(trg.T)
print("\nPredicted sequence (model output tokens):")
print(outputs.T)
خروجی:

کاربردهای مدل Seq2Seq
- ترجمه ماشینی: متن را بین زبانهایی مانند انگلیسی به فرانسوی تبدیل میکند.
- خلاصهسازی متن: خلاصههای کوتاهی از اسناد یا مقالات خبری تولید میکند.
- تشخیص گفتار: زبان گفتاری را به متن تبدیل میکند.
- شرحنویسی تصویر: با ترکیب ویژگیهای بصری و تولید توالی، برای تصاویر شرح (کپشن) ایجاد میکند.
- پیشبینی سریهای زمانی: توالیهای آینده را بر اساس دادههای زمانی گذشته پیشبینی میکند.
مزایای مدل Seq2Seq
- انعطافپذیری: وظایفی مانند ترجمه، خلاصهسازی و شرحنویسی را با توالیهایی با طول متغیر مدیریت میکند.
- مدیریت دادههای متوالی: برای دادههای متوالی مانند زبان طبیعی، گفتار و سریهای زمانی ایدهآل است.
- آگاهی از بافت (Context Awareness): ساختار انکودر-دیکودر بافت ورودی را به شکلی موثر ثبت میکند.
- مکانیزم توجه (Attention Mechanism): بر بخشهای مهم ورودی تمرکز میکند و عملکرد را برای توالیهای طولانی بهبود میبخشد.
معایب مدل Seq2Seq
- از نظر محاسباتی هزینهبر: به منابع قابل توجهی برای آموزش و بهینهسازی نیاز دارد.
- تفسیرپذیری محدود: درک فرآیند تصمیمگیری مدل دشوار است.
- بیشبرازش (Overfitting): بدون ریگولاریزاسیون (Regularization) مناسب، مستعد بیشبرازش است.
- مدیریت کلمات کمیاب: در مواجهه با کلمات کمیابی که در طول آموزش دیده نشدهاند، با مشکل مواجه میشود.
سوالات متداول
بردار بافت (Context Vector) در مدل Seq2Seq چیست؟
بردار بافت یک نمایش عددی فشرده و با طول ثابت است که انکودر از کل توالی ورودی تولید میکند. این بردار حاوی تمام اطلاعات کلیدی ورودی است که دیکودر برای تولید خروجی صحیح به آن نیاز دارد.
چرا در مدلهای Seq2Seq از LSTM یا GRU به جای RNN ساده استفاده میشود؟
RNNهای ساده با مشکل محو شدن گرادیان مواجه هستند و نمیتوانند وابستگیهای طولانیمدت را در توالیهای بلند حفظ کنند. LSTM و GRU با استفاده از مکانیزمهای دروازهبان، اطلاعات مهم را در طول زمان حفظ کرده و عملکرد بسیار بهتری دارند.
تکنیک Teacher Forcing چه کاربردی دارد؟
این تکنیک در طول فرآیند آموزش استفاده میشود و به جای استفاده از پیشبینیهای احتمالی اشتباه مدل، خروجی واقعی (Target) را به عنوان ورودی بعدی به دیکودر میدهد تا سرعت آموزش افزایش و خطاها کاهش یابند.
آیا طول ورودی و خروجی در مدل Seq2Seq باید برابر باشد؟
خیر، یکی از بزرگترین مزایای معماری انکودر-دیکودر در Seq2Seq این است که میتواند توالیهایی با طولهای کاملاً متفاوت را مدیریت کند، مانند ترجمه یک جمله کوتاه انگلیسی به یک جمله بلندتر فارسی.
مسیر تخصص در مدل زبانی و پردازش زبان طبیعی
درک مدلهای Seq2Seq و معماری انکودر-دیکودر، زیربنای اصلی بسیاری از دستاوردهای اخیر در هوش مصنوعی است. اما برای اینکه بتوانید از این مفاهیم پایه عبور کرده و به قدرت واقعی مدلهای مدرن دست پیدا کنید، باید بر فناوریهای پیشرفتهتری همچون ترنسفورمرها و مدلهای زبانی بزرگ مسلط شوید که امروزه قلب تپنده چتباتها و سیستمهای ترجمه پیشرفته هستند.
ما در دوره جامع LLM و NLP فضایی را فراهم کردهایم تا شما به جای درگیر شدن در تئوریهای محض، بتوانید پروژههایی واقعی و کاربردی مثل سیستمهای RAG و دستیارهای هوشمند فارسی را از صفر تا صد پیادهسازی کنید و به یک متخصص تراز اول در بازار کار امروز تبدیل شوید.
- آموزش تخصصی پیادهسازی سیستمهای پرسش و پاسخ (RAG) و خلاصهسازی هوشمند متون فارسی و انگلیسی.
- یادگیری گامبهگام Fine-Tuning مدلهای زبانی بزرگ برای ساخت چتباتهای پیشرفته و پروژههای هوش مصنوعی مولد.




















