

در عصر حاضر،هوش مصنوعی (AI) موتور محرک بسیاری از فناوریهای روزمره است. از دستیارهای دیجیتال و تشخیص تقلب گرفته تا اتومبیلهای خودران. در قلب این پیشرفتها، مفهومی به نام یادگیری عمیق (Deep Learning) قرار دارد. یادگیری عمیق نه تنها عملکرد کامپیوترها را در حل مسائل پیچیده متحول کرده، بلکه توانایی ماشینها در درک دادههایی مانند تصویر، متن و صدا را به شکل چشمگیری افزایش داده است.
در این مقاله جامع، به این سؤال اساسی پاسخ میدهیم که یادگیری عمیق چیست، چه تفاوتی با یادگیری ماشین سنتی دارد و این مدلهای قدرتمند چگونه کار میکنند. درک این مفاهیم پیشرفته، بخشی از مسیر آموزش هوش مصنوعی در مجموعه دیتایاد است که به شما کمک میکند وظایفی را که بهطور معمول نیازمند هوش انسانی هستند، بهصورت خودکار انجام دهید.
یادگیری عمیق (deep learning) چیست؟
یادگیری عمیق زیرشاخهای از یادگیری ماشین (Machine Learning) است که عملکرد آن از ساختار و عملکرد مغز انسان الهام گرفته شده است. این متدولوژی به کامپیوترها این امکان را میدهد که دادهها را با استفاده از شبکه های عصبی مصنوعی (Artificial Neural Networks) که از لایههای پردازشی متعدد و عمیق تشکیل شدهاند، پردازش و تحلیل کنند.
مدلهای یادگیری عمیق میتوانند الگوهای پیچیده را در حجم عظیم دادههای بدون ساختار (مانند تصاویر، متون و اصوات) به صورت خودکار تشخیص دهند و درکی عمیق و پیشبینیهایی دقیق را در حوزههای مختلف محقق سازند. ظهور داده های عظیم (Big Data) و توسعه سختافزارهای قدرتمند (مانند GPUها) در سالهای اخیر، امکان آموزش این مدلهای پیچیده را فراهم کرده و آنها را به ستون اصلی انقلاب هوش مصنوعی بدل ساخته است.
واژه “عمیق” در این اصطلاح، به وجود لایههای پنهان متعدد (Hidden Layers) در معماری شبکه عصبی دلالت دارد. برخلاف شبکههای عصبی ساده، در یادگیری عمیق، هرچه تعداد این لایهها بیشتر باشد، شبکه عمیقتر است و توانایی بیشتری در یادگیری انتزاعیترین ویژگیها (مانند تشخیص خطوط، اشکال و سپس چهره در یک تصویر) پیدا میکند. این ویژگی، نیاز به استخراج دستی ویژگیها (Feature Engineering) را که در روشهای سنتی رایج بود، به شدت کاهش میدهد.
مزایا و معایب یادگیری عمیق
پس از آشنایی با تعریف کلی یادگیری عمیق یا دیپ لرنینگ، حال زمان آن است که با نقاط قوت و محدودیتهای آن آشنا شویم. بهطور کلی، این فناوری بهدلیل توانایی در پردازش حجم عظیم دادههای پیچیده و استخراج خودکار الگوها، مزایای چشمگیری نسبت به روشهای سنتی دارد.
مزایای کلیدی (نقاط قوت)
- استخراج خودکار ویژگیها: نیاز به دخالت دستی انسان برای مهندسی ویژگی (Feature Engineering) را از بین میبرد. مدل بهصورت خودکار، مهمترین ویژگیها را در لایههای مختلف یاد میگیرد.
- دقت بالا و عملکرد بهتر: دستیابی به بالاترین سطح دقت و عملکرد در وظایف پیچیدهای مانند بینایی کامپیوتر (Computer vision) و پردازش زبانهای طبیعی (NLP)
- انعطافپذیری داده: قابلیت کار با انواع دادههای بدون ساختار (Unstructured Data) شامل متن، تصویر، صدا و ویدئو بهطور همزمان.
- مقیاسپذیری: عملکرد آن بهطور مستقیم با افزایش حجم دادهها بهبود مییابد. هرچه داده آموزشی بیشتر باشد، کیفیت مدل بهطور تصاعدی بالاتر میرود.
معایب و چالشها (محدودیتها)
- نیاز شدید به داده: برای دستیابی به عملکرد بهینه، به حجم بسیار عظیمی از دادههای برچسبدار (Labeled Data) نیاز دارد که تأمین آنها اغلب پرهزینه و زمانبر است.
- هزینه محاسباتی بالا: آموزش مدلهای عمیق نیازمند سختافزارهای قدرتمند مانند GPU یا TPU و استفاده از منابع رایانش ابری با هزینه بالا است.
- مشکل تفسیرپذیری (Explainability): مدلهای عمیق اغلب شبیه به “جعبه سیاه” عمل میکنند. مسیر تصمیمگیری آنها شفاف نیست و درک اینکه چرا یک پیشبینی خاص انجام شده، دشوار است (به ویژه در حوزههای حساس مانند پزشکی).
- ریسک بیشبرازش (Overfitting): در صورت کمبود داده یا تنظیم نامناسب پارامترها، مدل ممکن است دادههای آموزشی را حفظ کرده و در مواجهه با دادههای جدید، عملکرد ضعیفی داشته باشد.
با توجه به این محدودیتها، هرچند یادگیری عمیق ابزاری فوقالعاده قدرتمند است، اما همیشه بهترین انتخاب نیست و برای مسائل سادهتر یا پروژههایی با حجم داده کم، روشهای سنتی یادگیری ماشین اغلب کارآمدتر و کم هزینه تر هستند. اگر شما با تفاوت یادگیری ماشین و یادگیری عمیق آشنا باشید، میتوانید بر حسب پروژه، انتخاب مناسبی داشته باشید.

کاربردهای یادگیری عمیق در صنایع و فناوریها
قابلیتهای منحصربهفرد یادگیری عمیق برای پردازش حجم عظیم دادههای پیچیده و بدون ساختار، این فناوری را به یک ابزار حیاتی در صنایع گوناگون تبدیل کرده است. از تشخیص بیماریها در پزشکی و پیشبینی ریسک اعتباری در امور مالی گرفته تا هدایت اتومبیل های خودران، ردپای Deep Learning بهوضوح دیده میشود.
ما میتوانیم کاربردهای گسترده این متدولوژی را در چهار دستهبندی فناوری کلیدی خلاصه کنیم:
دستهبندیهای اصلی کاربردها
۱. بینایی کامپیوتر (Computer Vision)
تعریف: توانایی کامپیوتر در درک، تجزیه و تحلیل تصاویر و ویدئوها به روشی مشابه فهم انسان.
- مثالها: تشخیص چهره، بازرسی خودکار کیفیت قطعات در خط تولید، تحلیل تصاویر ماهوارهای، و تشخیص عابران پیاده در خودروهای خودران.
۲. پردازش زبان طبیعی (Natural Language Processing – NLP)
تعریف: توانایی کامپیوتر در درک، تفسیر، تولید و خلاصهسازی زبانهای انسانی (متن و گفتار).
- مثالها: توسعه مدلهای زبان بزرگ (LLM) مانند GPT، ترجمه ماشینی، خلاصهسازی خودکار اسناد، و تحلیل احساسات کاربران در شبکههای اجتماعی.
۳. بازشناسی گفتار (Speech Recognition)
تعریف: تبدیل گفتار انسانی به متن مکتوب، با وجود تنوع زیاد در لحن، لهجه و زیر و بمی صدا.
- مثالها: دستیارهای صوتی هوشمند (مانند الکسا یا سیری)، سیستمهای ترانویسی خودکار (صوت به متن) برای تماسها و ویدئوها، و سامانههای پاسخگویی خودکار در مراکز تماس.
۴. سیستمهای توصیه گر (Recommendation Engines)
تعریف: استفاده از مدلهای عمیق برای تحلیل رفتار و ترجیحات گذشته کاربران و پیشنهاد محتوا یا محصولات جدید.
- مثالها: پیشنهاد فیلم و موسیقی در پلتفرمهای استریمینگ (مانند نتفلیکس)، پیشنهاد محصول به مشتریان در سایتهای تجارت الکترونیک، و پیشنهاد دوستان جدید در شبکههای اجتماعی.
زبانهای برنامهنویسی برای یادگیری عمیق
پس از شناخت مفاهیم و کاربردهای یادگیری عمیق، قدم بعدی انتخاب ابزارهای مناسب برای پیادهسازی مدلها است. اگرچه میتوان از چندین زبان برنامهنویسی استفاده کرد، اما یک زبان بهعنوان استاندارد طلایی این حوزه شناخته میشود:
پایتون (Python): زبان استاندارد Deep Learning
زبان پایتون بدون شک رایجترین و محبوبترین زبان برنامهنویسی برای یادگیری عمیق، یادگیری ماشین و علم داده (Data Science) است و دلیل این برتری صرفاً به سادگی نحو (Syntax) آن محدود نمیشود:
- اکوسیستم بینظیر فریمورکها: پایتون از قویترین و گستردهترین مجموعه کتابخانههای مخصوص Deep Learning پشتیبانی میکند که توسط غولهای فناوری پشتیبانی میشوند:
- TensorFlow: که توسط گوگل توسعه داده شده و برای تولید در مقیاس بزرگ (Production) بسیار محبوب است.
- PyTorch: که توسط متا (فیسبوک) توسعه داده شده و بهویژه در محیطهای تحقیقاتی و مدلسازی سریع، استاندارد است.
- جامعه توسعهدهندگان فعال: وجود یک جامعه بزرگ به معنای دسترسی آسان به مستندات، آموزشها و امکانات رفع اشکال گسترده است.
- سادگی مدیریت داده: ادغام آسان پایتون با ابزارهای تحلیل و مدیریت داده مانند Pandas و NumPy، فرآیند آمادهسازی دادهها را تسهیل میکند.
سایر گزینهها
گرچه پایتون انتخاب اول است، اما در برخی موارد از زبانهای دیگر نیز استفاده میشود:
- R: این زبان عمدتاً در تحلیلهای آماری قوی است، اما اکوسیستم یادگیری عمیق آن در مقایسه با پایتون کوچکتر است.
- Julia: یک زبان با کارایی بالا در محاسبات علمی که در تلاش است محدودیتهای سرعت پایتون را برطرف کند، اما هنوز به اندازه آن فراگیر نشده است.
- C++: معمولاً این زبان برای بخشهای عملیاتی (Deployment) و بهینهسازی مدلهای آموزشدیده استفاده میشود، نه برای توسعه و آموزش اولیه.
نتیجهگیری: اگر قصد شروع به کار و توسعه در این حوزه را دارید، پایتون بهدلیل اکوسیستم غنی، بهترین و مطمئنترین انتخاب برای شروع مسیر یادگیری عمیق است.

ساختار و نحوه عملکرد شبکههای عصبی عمیق
عملکرد یادگیری عمیق بر پایه ساختاری به نام شبکههای عصبی مصنوعی (Artificial Neural Networks – ANNs) بنا شده است. این شبکهها تلاشی هستند برای تقلید از نحوه یادگیری و پردازش اطلاعات در مغز انسان.
ساختار شبکه عصبی عمیق
یک شبکه عصبی عمیق از میلیونها نورون مصنوعی تشکیل شده است که در سه نوع لایه اصلی سازماندهی شدهاند:
- لایه ورودی (Input Layer): دادههای اولیه (مثلاً پیکسلهای یک تصویر یا کلمات یک جمله) وارد مدل میشوند.
- لایههای پنهان (Hidden Layers): این لایهها، که تعدادشان در مدلهای عمیق زیاد است، در واقع مغز متفکر شبکه هستند. وظیفه آنها استخراج خودکار ویژگیهای انتزاعیتر و پیچیدهتر از خروجی لایه قبلی است.
- لایه خروجی (Output Layer): نتیجه نهایی پردازش، که پیشبینی یا طبقهبندی مدل را مشخص میکند (مثلاً تشخیص میدهد که تصویر مربوط به “سگ” است).
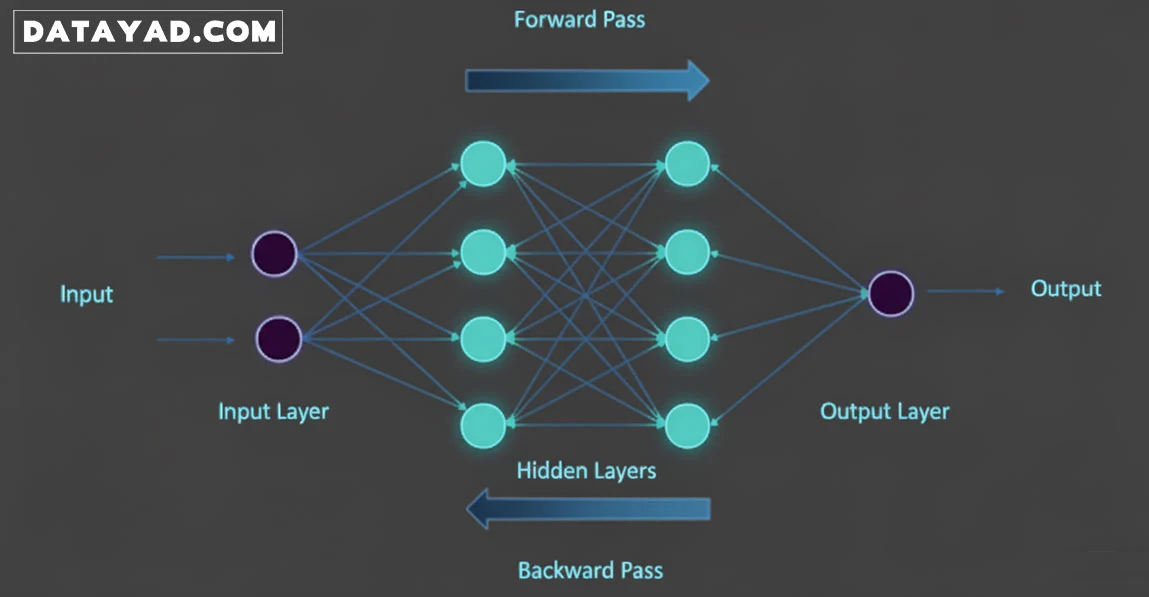
فرآیند یادگیری: تنظیم وزنها
یادگیری عمیق یک فرآیند تکراری و مداوم است که در آن، مدل با دیدن حجم زیادی از دادهها، خود را بهبود میبخشد:
- پیش انتشار (Feedforward): دادهها از لایه ورودی شروع به حرکت میکنند، از طریق تمام لایههای پنهان عبور میکنند و یک پیشبینی در لایه خروجی تولید میشود.
- محاسبه خطا: مدل، پیشبینی خود را با پاسخ صحیح واقعی مقایسه میکند و میزان خطای شبکه عصبی را محاسبه مینماید.
- پس انتشار (Backpropagation): مهمترین مکانیسم یادگیری اینجاست. شبکه، خطا را از لایه خروجی به لایههای قبلی باز میگرداند. هدف از این کار، تنظیم خودکار وزنها و بایاسها در اتصال بین نورونها است تا در تکرار بعدی، میزان خطا کاهش یافته و دقت مدل افزایش یابد.
این چرخه بارها تکرار میشود تا شبکه، الگوها را عمیقاً یاد بگیرد و به بالاترین سطح دقت برسد.

نسبت یادگیری عمیق با یادگیری ماشین چیست؟
برای درک بهتر یادگیری عمیق (DL)، باید جایگاه آن را در اکوسیستم بزرگتر یادگیری ماشین (ML) مشخص کنیم. به بیان ساده، یادگیری ماشین چتر مفهومی است و یادگیری عمیق یک زیرشاخه تخصصی و پیشرفته از آن محسوب میشود.
ML چتر مفهومی، DL زیرمجموعه آن
- یادگیری ماشین (ML): یک روش در هوش مصنوعی (AI) است که به سیستمها اجازه میدهد با استفاده از دادهها و بدون برنامهنویسی صریح، یاد بگیرند و عملکرد خود را بهبود بخشند. این دسته شامل الگوریتمهایی مانند رگرسیون خطی، درخت تصمیم و ماشین بردار پشتیبان (SVM) است.
- یادگیری عمیق (DL): نوعی پیشرفته از ML است که بهطور خاص از شبکههای عصبی با لایههای متعدد (عمیق) برای تحلیل داده و تصمیمگیری استفاده میکند.
به بیان دیگر، تمام مدلهای یادگیری عمیق، مدل یادگیری ماشین محسوب میشوند، اما عکس این قضیه صادق نیست.
تفاوت کلیدی: مهندسی ویژگی (Feature Engineering)
مهمترین تفاوت فنی که DL را از ML سنتی متمایز میکند، نحوه برخورد با استخراج ویژگیها است:
| ویژگی | یادگیری ماشین سنتی (ML) | یادگیری عمیق (DL) |
| استخراج ویژگی | دستی و نیازمند متخصص: انسان باید بهصورت دستی ویژگیهای مهم را از دادهها استخراج و انتخاب کند. |
خودکار: مدل بهصورت خودکار و در حین فرآیند آموزش (از طریق لایههای پنهان)، ویژگیهای مهم و مرتبط را استخراج و یاد میگیرد.
|
| عملکرد با حجم داده | با افزایش حجم داده، عملکرد به سرعت به یک حد اشباع میرسد. |
با افزایش حجم داده، عملکرد بهطور چشمگیری بهبود مییابد.
|
این توانایی در استخراج خودکار ویژگیهاست که یادگیری عمیق را برای کار با دادههای بدون ساختار (تصاویر، متون، صدا) تا این اندازه قدرتمند و کارآمد ساخته است.
اگر میخواهید این موضوع را بهطور کاملتر و عمیقتر بررسی کنید، مقاله «تفاوت یادگیری عمیق و یادگیری ماشین» را مطالعه کنید.
مزایای کلیدی یادگیری عمیق نسبت به یادگیری ماشین چیست؟
مزایای یادگیری عمیق (Deep Learning) به طور مستقیم از معماری لایهای و قابلیت استخراج خودکار ویژگیها ناشی میشود که آن را برای حل مسائل بزرگ و پیچیده، کارآمدتر از یادگیری ماشین (Machine Learning) سنتی میسازد.
در زیر، مهمترین مزایای DL نسبت به روشهای سنتی ML آورده شده است:
مزایای اصلی یادگیری عمیق (Deep Learning)
- پردازش بهینه دادههای بدون ساختار: مدلهای دیپ لرنینگ میتوانند به طور مستقیم و بدون نیاز به پیش پردازش های سنگین و مهندسی ویژگی دستی، با انواع دادههای بدون ساختار (تصاویر، صدا، متن) کار کنند و الگوهای پیچیده را در آنها بیابند. این امر پردازش دادههایی که برای ماشین لرنینگ سنتی چالشبرانگیز است را ممکن میسازد.
- مقیاسپذیری و بهبود عملکرد با افزایش داده: برخلاف مدل های ماشین لرنینگ سنتی که با افزایش حجم دادهها به یک سقف عملکردی میرسند، عملکرد مدلهای دیپ لرنینگ به طور تصاعدی با افزایش میزان دادههای آموزشی بهبود مییابد. (داده بیشتر = عملکرد قویتر).
- حذف نیاز به مهندسی ویژگی دستی: مدل های عمیق قابلیت این را دارند که خودشان ویژگیهای مرتبط با مسئله را از دادهها یاد بگیرند. این امر زمان و تلاش مورد نیاز برای توسعه مدل را به شدت کاهش داده و وابستگی به تخصص انسان در استخراج ویژگیها را از بین میبرد.
- کشف الگوها و روابط پنهان: شبکههای عمیق قادرند مجموعهای بسیار بزرگ از دادهها را عمیقتر تحلیل کنند و به درک و بینشی جدید دست یابند که ممکن است برای انسان غیرقابل کشف باشد (مانند روابط غیرخطی بسیار پیچیده).
- دقت برتر در وظایف پیچیده: به دلیل توانایی در یادگیری سلسله مراتبی ویژگیها (از ساده به پیچیده)، یادگیری عمیق در وظایفی مانند بینایی کامپیوتر و پردازش زبان طبیعی به دقتهای فوقالعاده بالایی دست یافته است که با یادگیری ماشین سنتی قابل دستیابی نبود.
چالشها و موانع کلیدی در مسیر یادگیری عمیق
با وجود قدرت و کارایی بینظیر یادگیری عمیق (DL)، پیادهسازی و استفاده از آن با موانع و چالشهای متعددی همراه است که باید مورد توجه قرار گیرند. شناخت این محدودیتها برای انتخاب درست مدل و مدیریت پروژه حیاتی است.
مهمترین چالشهای دیپ لرنینگ
- نیاز به حجم عظیم داده (Data Hunger): شبکههای عصبی عمیق برای آموزش مؤثر و جلوگیری از بیشبرازش، به حجم بسیار زیادی از دادههای برچسبدار (Labeled Data) نیاز دارند. در بسیاری از حوزهها، جمعآوری، تمیزکاری و برچسبگذاری چنین حجمی از دادهها یک چالش عملیاتی، زمانبر و پرهزینه است.
- هزینه محاسباتی سنگین (Computational Cost): آموزش مدلهای عمیق (به ویژه مدلهای بزرگ زبانی) نیازمند منابع پردازشی بسیار قدرتمند است. استفاده از پردازندههای گرافیکی (GPU) یا TPUها و سرویسهای رایانش ابری برای آموزش این مدلها، هزینههای بالایی را به پروژه تحمیل میکند.
- مشکل جعبه سیاه (Black Box Problem): مدلهای یادگیری عمیق در تصمیمگیریهای خود فاقد شفافیت هستند. درک اینکه چرا مدل یک خروجی خاص را تولید کرده یا کدام ورودیها تأثیر بیشتری داشتهاند (قابلیت تفسیرپذیری)، بسیار دشوار است. این امر در حوزههای حساس مانند پزشکی یا امور مالی، یک چالش اخلاقی و نظارتی جدی محسوب میشود.
- وقتگیر بودن آموزش و تنظیم مدل: مدلهای دیپ لرنینگ دارای پارامترهای بسیار زیادی (Hyperparameters) هستند که تنظیم دستی آنها برای دستیابی به عملکرد بهینه، فرآیندی طولانی، تکراری و اغلب مبتنی بر آزمون و خطا است.
- ریسک بیشبرازش (Overfitting): اگر دادههای آموزشی کافی نباشد یا تنظیمات پارامترها نامناسب باشد، مدل ممکن است بهجای یادگیری الگوهای کلی، صرفاً دادههای آموزشی را حفظ کند و در نتیجه، در مواجهه با دادههای جدید، عملکرد ضعیفی از خود نشان دهد.

آینده یادگیری عمیق (Deep Learning)
با توجه به پیشرفتهای شگرفی که یادگیری عمیق (Deep Learning) در یک دهه اخیر داشته است، مسیر آینده این فناوری نیز سرشار از نوآوری و تحولات گسترده خواهد بود. آینده یادگیری عمیق در تلاش برای غلبه بر چالشهای فعلی (مانند هزینه و مشکل جعبه سیاه) و گسترش دامنه کاربرد آن خلاصه میشود.
روندهای اصلی که آینده Deep Learning را شکل میدهند:
- هوش مصنوعی مولد (Generative AI) و مدلهای عظیم: تمرکز اصلی همچنان بر روی توسعه و بهینهسازی مدلهای بزرگ زبانی (LLM) و مدلهای مولد (مانند ابزارهای تبدیل متن به تصویر/ویدئو) خواهد بود. انتظار میرود این مدلها به طور فزایندهای دقیقتر، چندوجهی (Multimodal) (ترکیب تصویر، متن و صدا) و قادر به استدلال پیچیده شوند.
- یادگیری عمیق با قابلیت تفسیر (Explainable AI – XAI): برای استفاده ایمن و مسئولانه از DL در حوزههای حساس (مانند پزشکی یا امور مالی)، نیاز به شفافیت تصمیمگیری مدلها حیاتی است. تلاشهای آینده بر توسعه تکنیکهایی متمرکز خواهد بود که مدلها را از وضعیت “جعبه سیاه” خارج کرده و دلایل منطقی پشت پیشبینیهای آنها را مشخص کند.
- کاهش هزینهها و “هوش مصنوعی سبز”: با توجه به هزینه بالای آموزش مدلهای بزرگ، آینده DL به سمت افزایش بهرهوری و پایداری (Sustainability) حرکت خواهد کرد. تکنیکهایی مانند آموزش با دادههای کمتر و بهینهسازیهای سختافزاری برای کاهش نیاز به منابع محاسباتی گرانقیمت رایجتر میشوند.
- اجرای مدلها در لبه (Edge AI) و یادگیری فدرال: بهجای ارسال دادهها به ابر (Cloud) برای پردازش، مدلهای عمیق بهطور فزایندهای به سمت اجرا روی خود دستگاهها (تلفن همراه، دوربین، سنسورهای صنعتی) حرکت خواهند کرد. یادگیری فدرال (Federated Learning) نیز به سازمانها این امکان را میدهد تا مدلها را بر روی دادههای غیرمتمرکز و محلی آموزش دهند، بدون اینکه حریم خصوصی کاربران به خطر بیفتد.
سوالات متداول درباره یادگیری عمیق
در اینجا به برخی از پرتکرارترین سؤالاتی که معمولاً در مورد یادگیری عمیق مطرح میشود، به صورت مختصر پاسخ دادهایم تا درک جامعتری از این حوزه به دست آورید:
تفاوت هوش مصنوعی (AI)، یادگیری ماشین (ML) و یادگیری عمیق (DL) چیست؟
این مفاهیم یک رابطه سلسله مراتبی دارند:
- هوش مصنوعی (AI): ساخت ماشینهایی که مانند انسان فکر کنند.
- یادگیری ماشین (ML): آموزش ماشین با دادهها (یکی از روشهای دستیابی به AI).
- یادگیری عمیق (DL): زیرشاخه تخصصی ML که از شبکههای عصبی عمیق برای انجام وظایف پیچیده استفاده میکند. هر DL، یک ML است، اما هر ML، یک DL نیست.
یادگیری عمیق چه زمانی بر یادگیری ماشین سنتی ترجیح داده میشود؟
بهطور کلی در شرایط زیر مدل های دیپ لرنینگ ترجیح داده میشود:
- وقتی حجم دادههای برچسب دار بسیار زیاد باشد.
- وقتی با دادههای بدون ساختار (تصویر، ویدئو، متن) سروکار داریم، زیرا DL نیازی به مهندسی ویژگی دستی ندارد.
- وقتی هدف، دستیابی به بالاترین سطح دقت در وظایف پیچیده مانند بینایی کامپیوتر یا ترجمه ماشینی باشد.
برای یادگیری و پیادهسازی مدلهای عمیق از چه زبانها و فریمورکهایی استفاده میشود؟
زبان استاندارد این حوزه پایتون است. فریمورکهای اصلی نیز TensorFlow (توسعهیافته توسط گوگل) و PyTorch (توسعهیافته توسط متا/فیسبوک) هستند که ابزارهای لازم برای ساخت شبکههای عصبی را فراهم میکنند.
آیا یادگیری عمیق میتواند بدون نظارت (Unsupervised) انجام شود؟
بله. گرچه بخش اعظم پیشرفتها مربوط به یادگیری تحت نظارت (Supervised Learning) است، مدلهایی مانند خودرمزگذارها (Autoencoders) و برخی روشهای یادگیری خود-نظارتی (Self-Supervised Learning) وجود دارند که بدون نیاز به برچسبگذاری انسانی، میتوانند ویژگیها و ساختار پنهان دادهها را بیاموزند.
گامهای بعدی: شروع یادگیری با دیتایاد
اکنون که درک کاملی از مفاهیم، کاربردها و مزایای یادگیری عمیق به دست آوردهاید، زمان آن رسیده است که دانش تئوری را به مهارتهای عملی تبدیل کنید. برای کسب اطلاعات بیشتر در این زمنیه دارید میتوانید دوره deep learning دیتایاد را به صورت رایگان مشاهده کنید. همچنین دوره دیتا ساینس با پایتون دیتایاد گزینه بسیار مناسب برای افرادی است که به دنبال یک آموزش جامع، بدون پیش نیاز و از صفر تا موارد پیشرفته در هوش منصوعی و علم داده هستند.




















