

یادگیری ماشین به عنوان قلب تپنده هوش مصنوعی مدرن، نیازمند پایههای مستحکمی است که بدون آنها درک الگوریتمهای پیچیده عملاً غیرممکن خواهد بود. این حوزه علمی ترکیبی از تفکر منطقی برنامهنویسی و استدلالهای دقیق ریاضی است که به سیستمها اجازه میدهد بدون برنامهریزی صریح، از الگوهای موجود در دادهها بیاموزند و پیشبینی کنند. بنابراین بررسی پیش نیازهای یادگیری ماشین همیشه یکی از دغدغه های دانشجویان بوده و هست.
برای شروع موفق در این مسیر، نیازی به تخصص کامل در تمام حوزهها نیست، اما تسلط بر مهارتهای کلیدی مانند برنامهنویسی پایتون و مفاهیم پایهای آمار ضروری است. در این مطلب از بخش آموزش هوش مصنوعی، پیش نیازهای یادگیری ماشین را از ابزارهای عملیاتی تا مفاهیم نظری بررسی میکنیم تا مسیر یادگیری شما شفاف و هدفمند شود.
پایتون، یکی از پیش نیازهای یادگیری ماشین
پایتون به دلیل سینتکس ساده و کتابخانههای غنی، بهترین زبان برنامه نویسی برای هوش مصنوعی و یادگیری ماشین است. برای شروع این مسیر، تسلط بر مفاهیم پایهای برنامهنویسی مانند حلقهها، توابع و ساختارهای داده مثل لیست و دیکشنری ضروری است. همچنین درک اصول شیءگرایی به شما کمک میکند تا کدهای ساختاریافته و قابلتوسعه بنویسید.
-
- زبان برنامهنویسی پایتون: یادگیری نحو (Syntax) پایتون اولین قدم است. شما باید بتوانید منطق الگوریتمها را با استفاده از مفاهیم پایهای این زبان پیادهسازی کنید.
-
- کتابخانه NumPy: این کتابخانه ابزار اصلی برای انجام محاسبات عددی و کار با آرایههاست. از آنجا که یادگیری ماشین بر پایه محاسبات ماتریسی استوار است، تسلط بر این ابزار اهمیت زیادی دارد.
-
- کتابخانه Pandas: پیش از آموزش هر مدلی، باید دادهها را پاکسازی و تحلیل کنید. پانداز به شما اجازه میدهد دادهها را در قالب جداول (DataFrames) دستکاری و آمادهسازی کنید.
-
- محیط گوگل کولب (Colab): این پلتفرم ابری نیاز به نصب نرمافزار روی سیستم شخصی را از بین میبرد. شما میتوانید کدهای خود را در مرورگر اجرا کرده و از منابع پردازشی رایگان گوگل استفاده کنید.
یادگیری این ابزارها نیاز به زمان زیادی ندارد و نباید در آنها غرق شوید. بهترین روش این است که مفاهیم پایه را یاد بگیرید و به مرور زمان، دانش خود را حین انجام پروژههای واقعی هوش مصنوعی تکمیل کنید.
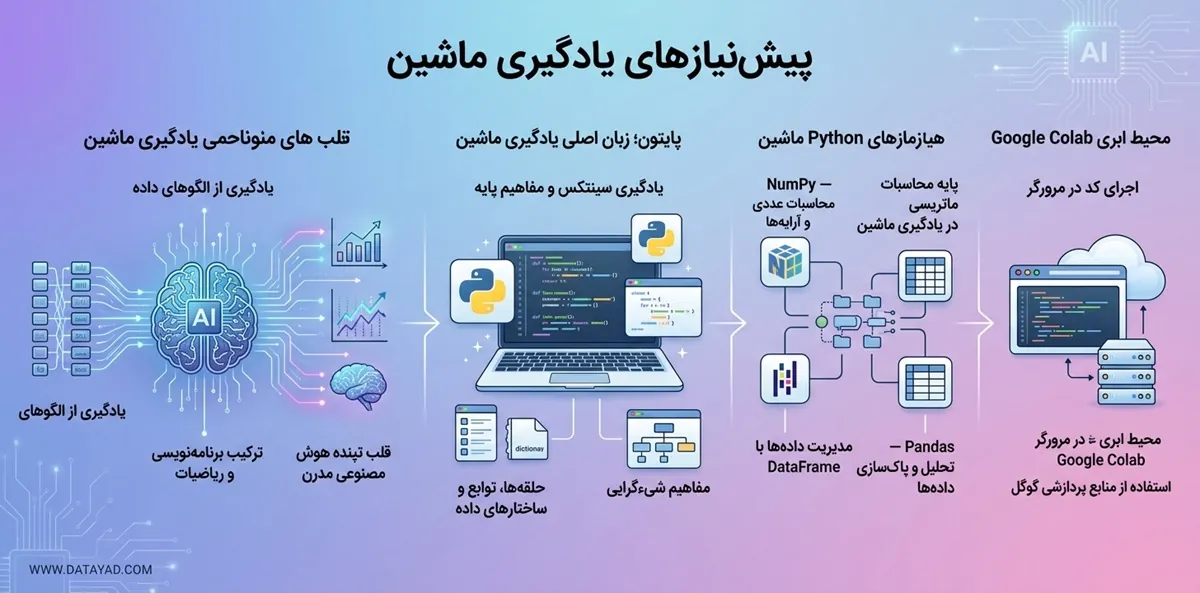
پایههای ریاضی و تفکر تحلیلی
الگوریتم های یادگیری ماشین در واقع مدل های ریاضی هستند که داده ها را به فضای برداری منتقل می کنند. پس ریاضیات یکی از مهمترین پیش نیازهای یادگیری ماشین است. بدون درک این زیربناها، عیب یابی مدل ها و انتخاب پارامترهای صحیح عملاً غیرممکن است. این دانش به شما کمک می کند تا منطق پشت پرده ی کدها را به درستی تحلیل کنید.
جبر خطی و محاسبات ماتریسی
داده های ورودی در یادگیری ماشین به صورت آرایه های چندبعدی یا ماتریس سازماندهی می شوند. جبر خطی ابزار اصلی برای جابجایی و تغییر شکل این داده ها در طول فرآیند آموزش است. یادگیری مفاهیمی مثل ضرب داخلی، مقادیر ویژه و تجزیه ی ماتریس برای درک نحوه ی عملکرد شبکه های عصبی ضرورت دارد.
آمار و احتمالات مهندسی
یادگیری ماشین با عدم قطعیت و استخراج الگو از داده های تصادفی سر و کار دارد. آمار به شما اجازه می دهد توزیع داده ها را بشناسید و میزان اطمینان به پیش بینی های مدل را اندازه بگیرید. مفاهیمی مثل قضیه ی بیز، واریانس و توزیع های احتمالی پایه ی اصلی بسیاری از مدل های طبقه بندی هستند.
حساب دیفرانسیل و بهینهسازی
فرآیند یادگیری در اکثر مدل ها به معنای کاهش خطای پیش بینی تا حد ممکن است. حساب دیفرانسیل و مبحث مشتقات جزئی ابزاری هستند که جهت و سرعت تغییرات خطا را محاسبه می کنند. الگوریتم های بهینه سازی مثل گرادیان کاهشی با تکیه بر همین محاسبات، وزن های مدل را برای رسیدن به دقیق ترین حالت ممکن تنظیم می کنند.
اگر به دنبال یک مسیر جامع و ساختاریافته هستید که تمام این پیشنیازها را از پایه پوشش دهد، پیشنهاد میکنیم آموزش متخصص علم داده را بررسی کنید. این آموزش از صفر مطلق شروع میشود و تمام مباحث موردنیاز از پایتون و تحلیل داده گرفته تا ریاضیات مهندسی و مدلسازی پیشرفته با یادگیری ماشین و یادگیری عمیق را به صورت مرحلهبهمرحله آموزش میدهد.

کتابخانههای اصلی و محیطهای توسعه
پیادهسازی مدلهای یادگیری ماشین نیازمند ابزارهایی است که فرآیند مدلسازی و ارزیابی را استانداردسازی کنند. این کتابخانهها با ارائه توابع پیشفرض، محاسبات سنگین ریاضی را ساده کرده و تمرکز برنامهنویس را بر بهبود دقت مدل معطوف میکنند.
| نام ابزار | دستهبندی | کاربرد اصلی در پروژه |
|---|---|---|
| Scikit-learn | مدلسازی کلاسیک | اجرای الگوریتمهای رگرسیون، دستهبندی و پیشپردازش دادهها |
| Matplotlib / Seaborn | بصریسازی | ترسیم توزیع آماری دادهها و نمودارهای تحلیل خطا |
| TensorFlow / PyTorch | یادگیری عمیق | طراحی و آموزش شبکههای عصبی برای دادههای حجیم و پیچیده |
| Jupyter Notebook | محیط توسعه محلی | اجرای تعاملی کدها و مستندسازی مراحل تحلیل در سیستم شخصی |
بسیاری از این ابزارها به صورت مکمل در کنار یکدیگر استفاده میشوند تا چرخه کامل دریافت، تحلیل و پیشبینی دادهها تکمیل شود. انتخاب بین این محیطها و کتابخانهها به پیچیدگی مسئله و نوع دادههای در دسترس بستگی دارد.
ساختمان داده و منطق الگوریتم
چیدمان دادهها در حافظه و مسیر اجرای دستورات، زیربنای اصلی هر برنامه یادگیری ماشین محسوب میشود. انتخاب یک ساختمان داده اشتباه میتواند سرعت اجرای مدل را به شدت کاهش دهد یا مصرف حافظه را بیدلیل بالا ببرد. در این بخش، یادگیری نحوه ذخیرهسازی اطلاعات در قالب لیستها، پشتهها و درختها اهمیت زیادی پیدا میکند تا بازیابی دادهها با بیشترین کارایی ممکن انجام شود.
منطق الگوریتم به معنای توانایی تجزیه یک مسئله بزرگ به مراحل کوچک و قابل اجرا است. برای طراحی مدلهای هوشمند، باید بدانید که چگونه شرطها و حلقههای تکرار را برای مدیریت جریان دادهها به کار بگیرید. این تفکر منطقی به شما کمک میکند تا فرآیندهای پیچیدهای مثل جستجو در پایگاهدادههای حجیم یا دستهبندی خودکار اطلاعات را به درستی پیادهسازی کنید.
درک مرتبه اجرایی یا پیچیدگی الگوریتمها به شما اجازه میدهد تا رفتار کد خود را در مواجهه با دادههای بزرگ پیشبینی کنید. بسیاری از توابع آماده در کتابخانههای پایتون بر پایه الگوریتمهای بهینه جستجو و مرتبسازی بنا شدهاند. تسلط بر این مفاهیم باعث میشود تا به جای استفاده کورکورانه از ابزارها، کدهایی بنویسید که از نظر فنی پایداری و سرعت لازم برای پروژههای واقعی را داشته باشند.
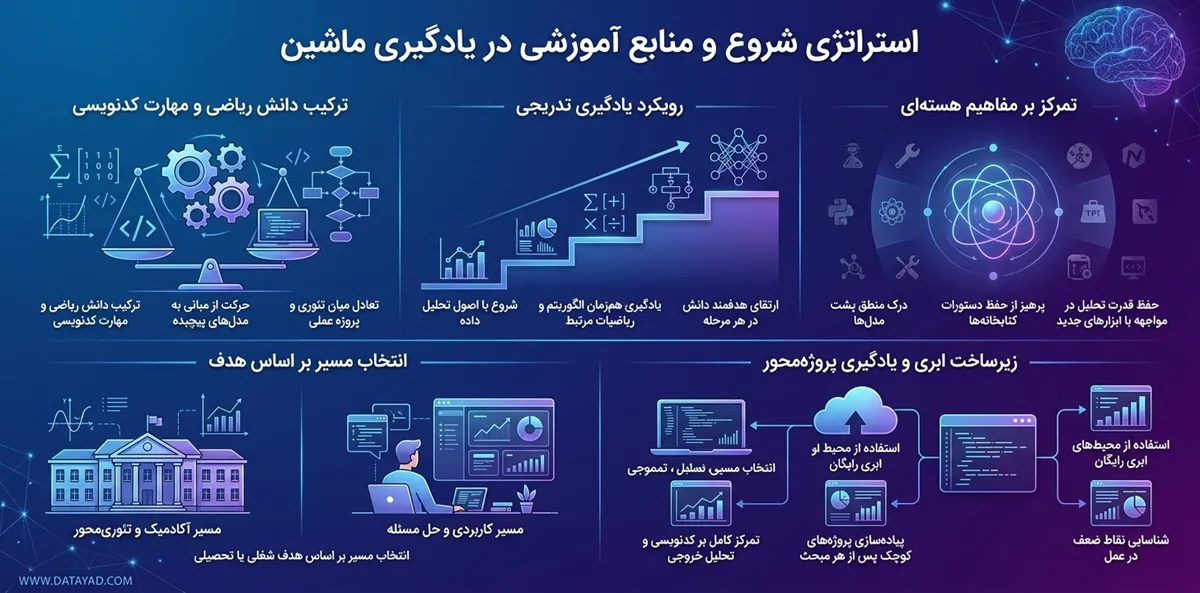
استراتژی شروع و منابع آموزشی
موفقیت در یادگیری ماشین به توانایی ترکیب همزمان دانش ریاضی و مهارت کدنویسی بستگی دارد. بسیاری از متخصصان توصیه میکنند به جای مطالعه پراکنده، از یک نقشه راه منسجم که از مبانی به سمت مدلهای پیچیده حرکت میکند، استفاده کنید. این مسیر باید شامل تعادلی میان درک تئوری و پیادهسازی پروژههای واقعی باشد.
-
- رویکرد یادگیری تدریجی: برای شروع نیازی به تسلط کامل بر تمام زیرشاخههای ریاضیات پیشرفته ندارید. بهترین استراتژی این است که ابتدا با اصول اولیه تحلیل داده آشنا شوید و سپس همزمان با یادگیری هر الگوریتم، دانش ریاضی مرتبط با آن را به صورت هدفمند ارتقا دهید.
-
- تمرکز بر مفاهیم هستهای: منابع معتبر جهانی مانند آموزشهای فشرده گوگل تاکید دارند که به جای حفظ کردن دستورات یک کتابخانه خاص، روی درک مفاهیم اصلی یادگیری ماشین تمرکز کنید. یادگیری منطق پشت مدلها باعث میشود تا در مواجهه با ابزارهای جدید و فریمورکهای متفاوت، قدرت تحلیل خود را حفظ کنید.
-
- انتخاب مسیر بر اساس هدف شغلی یا تحصیلی: اگر هدف شما درک عمیق و آکادمیک است، منابعی مانند دورههای دانشگاه استنفورد که بر تئوریهای یادگیری نظارت شده و بدون نظارت تمرکز دارند، اولویت دارند. برای ورود سریع به حوزه اجرا، دورههای کاربردی که مستقیما سراغ حل مسئله میروند کارایی بیشتری خواهند داشت.
-
- بهرهگیری از زیرساختهای ابری: برای شروع فرآیند یادگیری، درگیر کردن ذهن با چالشهای نصب نرمافزارهای سنگین و مدیریت سختافزار پیشنهاد نمیشود. استفاده از محیطهای ابری رایگان به شما اجازه میدهد تمام تمرکز خود را روی کدنویسی و تحلیل خروجی مدلها بگذارید.
-
- یادگیری پروژهمحور: پس از مرور هر بخش از مفاهیم، بلافاصله آن را در قالب یک پروژه کوچک پیادهسازی کنید. این کار باعث میشود نقاط ضعف شما در پیادهسازی الگوریتمها شناسایی شده و درک بهتری از نحوه تعامل اجزای مختلف سیستم پیدا کنید.
نقشه راه یادگیری ماشین + منابع لازم
برای داشتن یک شروع موفق، پیشنهاد میکنیم گامهای پیشنهادی ما را دنبال کنید: ابتدا با تثبیت پیش نیازهای یادگیری ماشین مهارتهای برنامهنویسی پایتون و ریاضیات پایه شروع کرده و سپس به سمت یادگیری الگوریتمهای کلاسیک حرکت کنید. با دنبال کردن این مسیر مرحلهبهمرحله، نه تنها مفاهیم برای شما شفافتر میشود، بلکه اعتمادبهنفس کافی برای ورود به پروژههای عملی و بازار کار هوش مصنوعی را به دست خواهید آورد.، حتماً نگاهی به نقشه راه یادگیری هوش مصنوعی بیندازید. این نقشه راه، ویترینِ مهارتهای موردنیاز است که به شما کمک میکند به جای آزمون و خطاهای بیپایان، دقیقاً بدانید از کجا شروع کنید، چه ابزارهایی را در اولویت قرار دهید و چگونه در سریعترین زمان ممکن به یک متخصص تبدیل شوید.



















