

مدلهای زبانی کوچک یا SLMها، نسل جدیدی از سیستمهای هوش مصنوعی هستند که با هدف برقراری تعادل میان کارایی و مصرف منابع طراحی شدهاند. این مدلها برخلاف همتایان غولآسای خود، با تعداد پارامترهای بسیار کمتر در مقیاس میلیون تا چند میلیارد آموزش میبینند تا بتوانند وظایف پردازش زبان طبیعی را در محیطهایی با توان پردازشی محدود و حافظه اندک به انجام برسانند. این رویکرد نوین، امکان بهرهگیری از قدرت هوش مصنوعی را در دستگاههای لبه و اپلیکیشنهای موبایلی فراهم کرده است.
درک عمیق ساختار این مدلها برای دانشجویان و متخصصان علوم داده ضروری است، زیرا روند توسعه از سمت مدلهای همهمنظوره و سنگین به سمت مدلهای تخصصی، چابک و کمهزینه در حال حرکت است. مدلهای سبک نه تنها در مصرف انرژی صرفهجویی میکنند، بلکه با تمرکز بر دامنههای دانش خاص، در بسیاری از موارد دقتی مشابه یا حتی بالاتر از مدلهای بزرگتر از خود نشان میدهند.در این مطلب از بخش آموزش هوش مصنوعی، معماری فنی، روشهای فشردهسازی و پتانسیلهای کاربردی این فناوری را بررسی میکنیم.
تعریف مدلهای زبانی کوچک یا SLM ها
مدلهای زبانی کوچک یا همان SLMها نسخههای فشرده و بهینهای از شبکههای عصبی ترنسفورمر هستند که با هدف انجام وظایف مشخص طراحی شدهاند. این مدلها بر خلاف نسخههای غولآسا یا همان LLM ها، به جای انباشت دانش عمومی، بر کارایی عملیاتی و تخصص در یک حوزه متمرکز میشوند. ساختار سادهتر این مدلها اجازه میدهد تا فرآیند پردازش زبان طبیعی با سرعت بالاتر و پیچیدگی کمتری انجام شود.
تعریف پارامتر و مقیاس مدل
پارامترها در واقع متغیرهای داخلی مدل مثل وزنها و بایاسها هستند که در طول دوره ی آموزش تنظیم میشوند تا دقت پیشبینی بالا برود. در حالی که مدلهای بزرگ صدها میلیارد پارامتر دارند، تعداد پارامترهای یک SLM معمولا بین چند میلیون تا چند میلیارد متغیر است. این تفاوت عددی باعث میشود مدل کوچکتر، ساختاری سبک داشته باشد و برای کاربردهای خاص بهینه شود.
مقیاس کوچکتر به این معنا نیست که هوش مدل از بین رفته است؛ بلکه تمرکز آن محدودتر میشود. یک مدل کوچک با چند میلیارد پارامتر میتواند در وظایف تخصصی مثل تحلیل متنهای حقوقی یا پزشکی، بازدهی مشابه یا حتی بهتری نسبت به مدلهای سنگین داشته باشد. کاهش مقیاس در اینجا به معنای حذف دادههای غیرضروری و تمرکز روی دقت در یک دامنه ی خاص است.
تفاوت در منابع پردازشی و حافظه
مدلهای بزرگ برای اجرا و آموزش به خوشههای پردازشی عظیم و تعداد زیادی کارت گرافیک پیشرفته نیاز دارند. در مقابل، SLMها با حداقل منابع سختافزاری سازگار هستند و به راحتی روی حافظه ی رم دستگاههای معمولی اجرا میشوند. این ویژگی باعث میشود هزینه ی زیرساختی برای سازمانها به شکل چشمگیری کاهش یابد و دسترسی به فناوریهای هوشمند آسانتر شود.
به دلیل حجم کم و نیاز پایین به توان پردازشی، این مدلها امکان اجرا روی دستگاههای لبه مثل موبایلها یا حسگرهای صنعتی را فراهم میکنند. این موضوع باعث میشود پردازش دادهها به صورت محلی انجام شود و نیازی به اتصال دائمی به اینترنت یا سرورهای ابری نباشد. در نتیجه، سرعت پاسخدهی یا لیتنسی مدل به شدت بهبود پیدا کرده و مصرف انرژی نیز بهینه میشود.
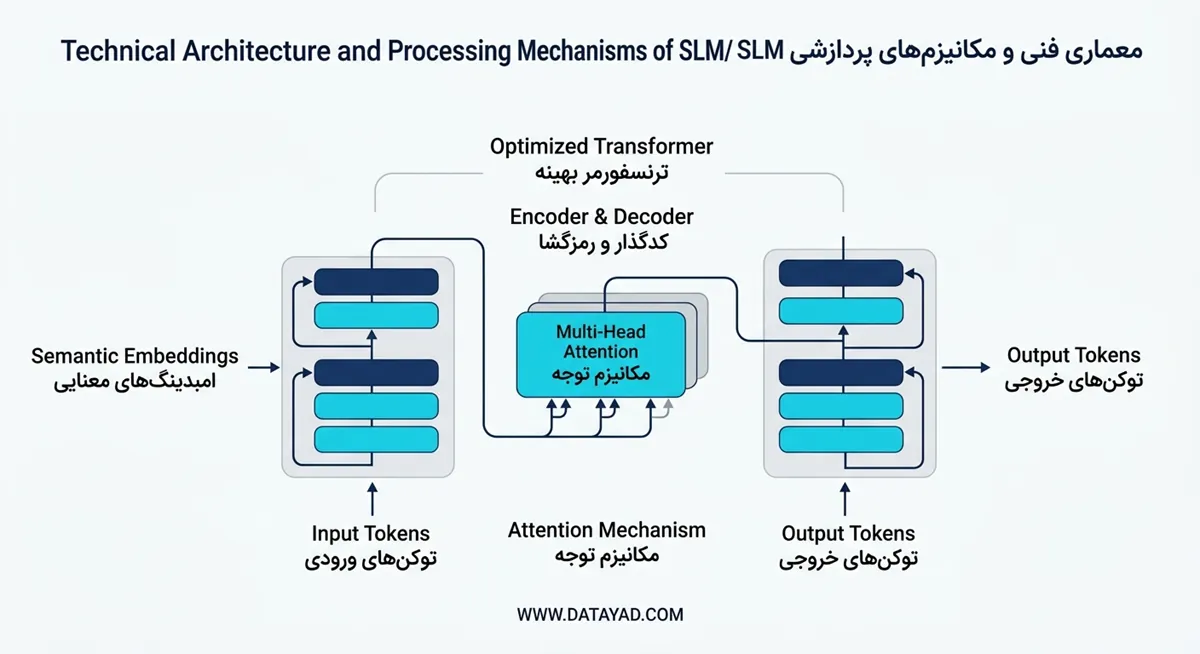
معماری فنی و مکانیزمهای پردازشی SLM
مدلهای زبانی کوچک از معماری ترنسفورمر به عنوان هسته اصلی پردازش دادهها استفاده میکنند. این ساختار بر پایه تبدیل متن به بردارهای عددی بنا شده است تا سیستم بتواند الگوهای پیچیده زبانی را درک کند. بهینهسازی در این بخش با حذف لایههای اضافی و سادهسازی اتصالات عصبی انجام میشود تا سرعت پاسخدهی افزایش یابد.
در طراحی فنی این مدلها، تلاش بر این است که با حفظ دقت، حجم محاسبات ریاضی کاهش پیدا کند. این رویکرد باعث میشود مدل بتواند روی سختافزارهای معمولی به راحتی اجرا شود. در واقع، معماری این ابزارها برای توازن میان مصرف انرژی و کیفیت خروجی مهندسی شده است.
ساختار ترنسفورمر در ابعاد کوچک
معماری ترنسفورمر در این مدلها شامل لایههای عصبی متعددی است که برای پردازش موازی دادهها طراحی شدهاند. برخلاف مدلهای حجیم، در اینجا تعداد بلوکهای سازنده کاهش یافته است تا بار پردازشی کمتری به حافظه موقت وارد شود. این سادهسازی شامل کاهش ابعاد فضای پنهان و تعداد سرهای توجه است.
هر لایه در این ساختار وظیفه ی استخراج ویژگی خاصی از متن را بر عهده دارد. با فشردهسازی این لایهها، مدل قادر است مفاهیم اصلی را با پارامترهای کمتری یاد بگیرد. این معماری سبک، امکان اجرای مدل را در محیطهای محلی به خوبی فراهم میکند.
نقش کدگذار و رمزگشا در تولید متن
فرآیند پردازش با بخش کدگذار شروع میشود که توکنهای ورودی را به بردارهای معنایی یا همان امبدینگ تبدیل میکند. این بردارها حاوی اطلاعاتی درباره ی معنا و جایگاه هر کلمه در جمله هستند. کدگذار با تحلیل این دادهها، یک نقشه ی مفهومی از ورودی کاربر ایجاد میکند.
بخش رمزگشا با استفاده از این نقشه ی مفهومی، شروع به پیشبینی و تولید توکنهای خروجی میکند. این قسمت از معماری به صورت بازگشتی عمل کرده و بر اساس کلمات قبلی، محتملترین کلمه ی بعدی را انتخاب میکند. هماهنگی میان این دو بخش باعث میشود پاسخها منطقی و مرتبط با موضوع باقی بمانند.
مکانیزم توجه برای مدیریت توکنها
مکانیزم توجه به مدل اجازه میدهد تا روی بخشهای کلیدی متن تمرکز کرده و از دادههای بی اهمیت صرفنظر کند. این تکنیک روابط بین کلمات را بدون در نظر گرفتن فاصله ی آنها از یکدیگر تحلیل میکند. در مدلهای کوچک، این مکانیزم به شکلی بهینه شده که کمترین فشار را به پردازنده وارد کند.
با استفاده از خود-توجهی، مدل وزنهای متفاوتی به هر توکن اختصاص میدهد تا اهمیت آن را در جمله مشخص کند. این روش به مدل کمک میکند تا ابهامات زبانی را برطرف کرده و مرجع ضمیرها یا کلمات چندمعنایی را به درستی تشخیص دهد. مدیریت دقیق توکنها از طریق این مکانیزم، دقت خروجی را در حوزههای تخصصی تضمین میکند.
استراتژیهای فشردهسازی و بهینهسازی مدلهای زبانی کوچک
تبدیل مدلهای سنگین به نسخههای کوچک و کارآمد، از طریق فرآیندهای مهندسی دقیقی انجام میشود که هدف آنها کاهش بار محاسباتی و اشغال حافظه است. این تکنیکها با تغییر در نحوه ذخیرهسازی وزنها یا حذف دادههای غیرضروری، اجرای مدل را روی سختافزارهای ضعیفتر تسهیل میکنند.
| روش فشردهسازی | مکانیسم عمل | مزیت اصلی |
|---|---|---|
| کوانتیزاسیون (Quantization) | تبدیل دقت اعداد از ۳۲ بیت (Floating Point) به ۸ بیت یا کمتر. | کاهش شدید حجم مدل و افزایش سرعت استنتاج روی پردازندههای معمولی. |
| هرس کردن (Pruning) | شناسایی و حذف وزنها، نورونها یا لایههایی که تاثیر کمی در خروجی دارند. | سادهسازی ساختار شبکه عصبی و کاهش تعداد عملیات ریاضی در هر پردازش. |
| تقطیر دانش (Knowledge Distillation) | آموزش یک مدل کوچک (شاگرد) برای تقلید از رفتار و خروجیهای یک مدل بزرگ (استاد). | انتقال قابلیتهای استدلالی مدلهای بزرگ به مدلهای بسیار سبک و چابک. |
| تجزیه کمرتبه (Low-rank Factorization) | تجزیه ماتریسهای بزرگ وزن به ماتریسهای کوچکتر و سادهتر ریاضی. | کاهش پیچیدگی محاسبات ضرب ماتریسی و صرفهجویی در مصرف رم. |
انتخاب هر یک از این استراتژیها بستگی به توازن مورد نیاز بین دقت و سرعت دارد. در بسیاری از پروژههای عملی، ترکیبی از این روشها برای رسیدن به بهینهترین حالت ممکن در دستگاههای لبه استفاده میشود.
مزایای کلیدی مدلهای زبانی کوچک
انتخاب مدلهای زبانی کوچک در معماری سیستم، هزینههای نهایی استنتاج و نگهداری زیرساخت را به طور میانگین تا ده برابر کاهش میدهد. این رویکرد به تیمهای فنی اجازه میدهد بدون وابستگی به کلاسترهای سنگین گرافیکی، چرخههای توسعه و آزمایش محصول را با سرعت بیشتری طی کنند.
- مالکیت کامل و امنیت دادهها: استقرار مدل روی سرورهای داخلی یا دستگاههای محلی، نیاز به ارسال اطلاعات حساس به سرویسهای ابری شخص ثالث را از بین میبرد. این موضوع در صنایع تحت نظارت مانند فینتک و سلامت، چالشهای قانونی و امنیتی را به حداقل میرساند.
- بهینهسازی بودجه عملیاتی: حذف هزینههای مربوط به فراخوانی API و اشتراکهای دلاری، مدلهای اقتصادی پروژه را توجیهپذیرتر میکند. در مقیاسهای بالا، استفاده از مدلهای اختصاصی و سبک باعث صرفهجویی قابل توجه در هزینههای ثابت میشود.
- دقت بالا در حوزههای تخصصی: به دلیل تمرکز مدل بر مجموعه دادههای محدود و مرتبط، خروجیهای تولید شده در زمینههایی مثل حقوق یا مهندسی دقیقتر از مدلهای عمومی است. این تخصصگرایی مانع از تولید پاسخهای بیربط یا کلیگوییهای رایج میشود.
- کاهش ردپای کربن و پایداری: مصرف انرژی بسیار کمتر در فرآیند استنتاج، پروژههای هوش مصنوعی را با استانداردهای محیطزیستی هماهنگ میکند. این ویژگی علاوه بر کاهش هزینههای برق سرورها، برای سازمانهای پایبند به توسعه پایدار یک مزیت استراتژیک محسوب میشود.
- چابکی در بازآموزی مدل: کم بودن تعداد پارامترها امکان آموزش مجدد مدل با دادههای جدید را در زمان کوتاهی فراهم میکند. این سرعت عمل باعث میشود سیستم هوش مصنوعی همواره با تغییرات لحظهای بازار و نیازهای جدید کاربران هماهنگ بماند.
- امکان اجرای آفلاین: قابلیت پردازش مستقیم روی دستگاه نهایی، وابستگی به اینترنت را حذف و پایداری سرویس را در شرایط قطع شبکه تضمین میکند. این مزیت برای اپلیکیشنهای موبایل و ابزارهای مورد استفاده در نقاط دورافتاده حیاتی است.
محدودیتهای فنی مدلهای زبانی کوچک
کوچکسازی مدلهای زبانی با وجود تمام مزایای عملیاتی، گلوگاههای فنی مشخصی ایجاد میکند. این مدلها به دلیل تعداد پارامترهای کمتر، در تحلیل دادههایی که نیاز به استدلال چندلایه دارند، ضعیفتر از مدلهای غولآسا عمل میکنند. کاهش ظرفیت محاسباتی مستقیما بر توانایی مدل در پردازش سناریوهای غیرمتعارف و انتزاعی اثر میگذارد.
کاهش درک مفاهیم پیچیده زبانی
تعداد محدود پارامترها باعث میشود مدل توانایی تشخیص تفاوتهای ظریف معنایی، استعارهها یا کنایههای موجود در زبان را تا حد زیادی از دست بدهد. این مدلها معمولا بر روی بخشهای تخصصی دانش تمرکز دارند و نمیتوانند ارتباط منطقی میان مفاهیم پراکنده در یک متن طولانی را به درستی برقرار کنند. در مواجهه با متون حقوقی یا ادبی سنگین، احتمال سادهسازی بیش از حد و از دست رفتن لایههای زیرین معنا در خروجی مدل افزایش مییابد.
ضعف در درک بافتار (Context) باعث میشود مدل در پاسخ به پرسشهای مبهم، به جای تحلیل دقیق، به الگوهای تکراری و ساده متوسل شود. این محدودیت ریشه در معماری ساده شده آنها دارد که سرهای توجه (Attention Heads) کمتری برای واکاوی جملات در اختیار دارد. بنابراین، خروجی این مدلها در مباحثی که نیاز به درک عمیق از فرهنگ یا لحن خاص دارند، ممکن است سطحی به نظر برسد.
احتمال بروز توهم و خطای استدلال
مدلهای زبانی کوچک در حل مسائل منطقی و محاسباتی با نرخ خطای بالاتری نسبت به نسخههای بزرگتر روبرو هستند. فشردهسازی لایهها باعث میشود مدل گاهی روابط علت و معلولی را به اشتباه تفسیر کرده و پاسخهای به ظاهر درست اما از نظر علمی غلط تولید کند. این پدیده که با نام توهم شناخته میشود، در مدلهای کوچک به دلیل آموزش بر روی دادههای محدودتر، با شدت بیشتری دیده میشود.
به دلیل ساختار سبک، این مدلها در فرآیند استنتاج (Inference) ممکن است مسیرهای کوتاهتری را برای رسیدن به پاسخ طی کنند که منجر به نادیده گرفتن جزئیات حیاتی میشود. در کاربردهایی که دقت ریاضی یا استدلال زنجیرهای اهمیت حیاتی دارد، تکیه صرف بر این مدلها بدون نظارت انسانی ریسک بالایی دارد. اعتبارسنجی مداوم خروجیها در این سطح از هوش مصنوعی برای جلوگیری از انتشار اطلاعات نادرست ضروری است.
ظرفیت محدود در ذخیرهسازی دانش
پارامترهای یک مدل در واقع نقش مخزن ذخیره حقایق و اطلاعات را ایفا میکنند. مدلهای کوچک به دلیل محدودیت عددی این پارامترها، فضای فیزیکی کافی برای نگهداری تمام دانش عمومی موجود در جهان را ندارند. آنها مانند یک کتابخانه کوچک تخصصی هستند که فقط چند موضوع محدود را با دقت بالا پوشش میدهند اما در برابر سوالات خارج از حوزه تخصصی خود، پاسخهای مبهمی ارائه میدهند.
این محدودیت باعث میشود مدل در بازیابی فکتها و رویدادهای تاریخی پراکنده دچار ضعف شود. برخلاف مدلهای بزرگ که دانشنامه عظیمی را در دل خود جای دادهاند، مدلهای کوچک برای جبران این خلاء به ابزارهای جانبی مانند RAG نیاز دارند تا اطلاعات را از منابع خارجی فراخوانی کنند. بدون این اتصال، دانش مدل به سرعت محدود به همان دادههای اولیه آموزش میشود و توانایی تعمیمدهی بالایی نخواهد داشت.

سناریوهای کاربردی در دنیای واقعی
مدلهای زبانی کوچک با هدف انتقال توان پردازشی از سرورهای ابری به لایههای عملیاتی و دستگاههای نهایی طراحی شدهاند. این مدلها به دلیل حجم کم، در سناریوهایی که تاخیر زمانی و امنیت داده اولویت دارد، جایگزین مدلهای غولآسا میشوند. تمرکز اصلی این ابزارها بر انجام وظایف مشخص با دقت بالا و صرف کمترین منابع سیستمی است.
- دستیارهای هوشمند و چتباتهای آفلاین: این مدلها امکان اجرای چتباتهای خدمات مشتریان را با سرعت پاسخدهی بالا فراهم میکنند. از آنجا که پردازش به صورت محلی انجام میشود، سازمانها بدون نیاز به اتصال دائم اینترنت و پرداخت هزینههای سنگین برای فراخوانی مدلهای ابری، تعامل با کاربر را مدیریت میکنند.
- خلاصهسازی محتوا در دستگاههای همراه: کاربران میتوانند متون طولانی، ضبطهای صوتی یا پیامهای دریافتی را مستقیماً در تلفن همراه خود خلاصهسازی کنند. این فرآیند بدون ارسال داده به سرورهای خارجی انجام میشود که علاوه بر حفظ حریم خصوصی، مصرف باتری و پهنای باند دستگاه را بهینه میکند.
- تولید و تکمیل خودکار کد: مدلهای کوچک در ابزارهای داخلی توسعه نرمافزار برای تکمیل خودکار کد و مستندسازی فنی استفاده میشوند. این مدلها با یادگیری الگوهای خاص هر پروژه، دقت بالایی در تولید قطعهکدها دارند و از نشت اطلاعات حساس و مالکیت معنوی کدها به خارج از محیط شرکت جلوگیری میکنند.
- ترجمه آنی و محلی: در محیطهایی با دسترسی محدود به شبکه یا در سفرهای بینالمللی، این ابزارها ترجمه متون و گفتار را به صورت آفلاین انجام میدهند. به دلیل سرعت بالای استنتاج، ترجمه بدون مکث انجام شده و تفاوتهای معنایی و لحن مبدا به خوبی حفظ میشود.
- نگهداری پیشبینانه در تجهیزات صنعتی: با استقرار مدلهای زبانی کوچک روی سنسورهای اینترنت اشیا، دادههای دریافتی از ماشینآلات به صورت لحظهای تحلیل میشوند. این سیستمها ناهنجاریها را شناسایی کرده و زمان خرابی قطعات را پیشبینی میکنند، بدون اینکه نیازی به ارسال حجم عظیم دادههای خام به فضای ابری باشد.
- تحلیل احساسات و دستهبندی خودکار: کسبوکارها برای بررسی بازخوردهای مشتریان، از این مدلها برای خوشهبندی نظرات و تشخیص لحن مثبت یا منفی استفاده میکنند. این مدلها به دلیل معماری بهینه، هزاران رکورد متنی را در زمان بسیار کوتاهی پردازش کرده و گزارشهای تحلیلی دقیقی ارائه میدهند.
- ناوبری و کمکراننده هوشمند: سیستمهای داخلی خودرو با استفاده از این تکنولوژی، دستورات صوتی راننده را با دادههای محیطی ترکیب میکنند. این مدلها با تحلیل سریع قوانین جادهای ذخیره شده در حافظه محلی، به راننده در تصمیمگیریهای آنی و ایمن کمک کرده و وابستگی خودرو به شبکه را در مسیرهای دورافتاده حذف میکنند.
بررسی مدلهای زبانی کوچک مطرح و شاخص در صنعت
اکوسیستم هوش مصنوعی از رقابت بر سر افزایش بیرویه پارامترها به سمت ساخت معماریهای کارآمد و تخصصی حرکت کرده است. شرکتهای پیشرو با عرضه نسخههای سبک، امکان پیادهسازی محلی و ارزانقیمت را برای پروژههای مختلف فراهم کردهاند. مدلهای زیر بر اساس توان عملیاتی و بهینهسازی ساختاری، جزو گزینههای استاندارد در صنایع فنی محسوب میشوند.
| نام مدل | توسعهدهنده | ویژگی شاخص فنی |
|---|---|---|
| DistilBERT | گوگل | استفاده از تکنیک تقطیر دانش برای حفظ عملکرد در ابعاد بسیار کوچک. |
| Gemma | گوگل | بهرهگیری از معماری مدلهای پیشرفته برای کاربردهای عمومی و پژوهشی. |
| GPT-4o mini | OpenAI | قابلیت پردازش همزمان متن و تصویر با هزینه بسیار پایین. |
| Granite | IBM | تمرکز ویژه بر سناریوهای سازمانی، امنیت داده و سیستمهای بازیابی اطلاعات. |
| Llama | Meta | ساختار متنباز با پشتیبانی گسترده از زبانهای مختلف و سرعت اینفرنس بالا. |
| Phi | مایکروسافت | توانایی استدلال منطقی بالا و مدیریت پنجرههای بافتار طولانی در ابعاد محدود. |
| Ministral | Mistral AI | بهینهسازی شده برای محاسبات ریاضی و استفاده از مکانیزم توجه پنجرهای. |
انتخاب میان این گزینهها مستقیما به محدودیتهای سختافزاری و نوع دادههای ورودی بستگی دارد. هر یک از این مدلها با استفاده از متدهای فشردهسازی، شکاف بین دقت مدلهای غولآسا و سرعت پردازش محلی را پر کردهاند.
یادگیری مدلهای زبانی و پردازش زبان طبیعی
اگر میخواهید به صورت عملی وارد دنیای مدلهای زبانی کوچک، LLMها و سیستمهای پردازش متن شوید، یادگیری مفاهیم NLP و معماری مدلهای زبانی اهمیت زیادی دارد. بسیاری از تکنیکهایی که در SLMها استفاده میشوند، مستقیماً از مباحث پردازش زبان طبیعی، ترنسفورمرها و بهینهسازی مدلهای زبانی گرفته شدهاند.
برای یادگیری اصولی این حوزه، آموزش مدل زبانی و پردازش زبان طبیعی میتواند مسیر مناسبی برای درک مفاهیم فنی، پیادهسازی پروژههای واقعی و آشنایی با معماری مدلهای مدرن هوش مصنوعی باشد. در این دوره مباحثی مثل NLP، مدلهای ترنسفورمر، LLMها، پردازش متن و کاربردهای عملی هوش مصنوعی زبانی آموزش داده میشود.
آینده پژوهی و روندهای توسعه هوش مصنوعی سبک
توسعه مدلهای زبانی سبک بر پایه انتقال بار پردازشی از خوشههای ابری به پردازندههای محلی استوار است. این مدلها به سمتی حرکت میکنند که توانایی استدلال منطقی را در محیطهای با محدودیت حافظه افزایش دهند. کاهش وابستگی به پهنای باند و بهینهسازی مصرف انرژی، نقشه راه اصلی برای تکامل این فناوری محسوب میشود.
توسعه محاسبات لبه و اینترنت اشیا
استقرار هوش مصنوعی در لبه شبکه، حسگرهای ساده اینترنت اشیا را به پردازشگرهای محلی تبدیل میکند. این روند باعث میشود تصمیمگیریهای پیچیده در کسری از ثانیه و بدون ارسال داده به سرورهای خارجی انجام شود. گرههای محاسباتی در تجهیزات صنعتی و گجتها، با استفاده از معماریهای سبک، توانایی تحلیل بافتار محلی را پیدا میکنند.
یکپارچگی مدلهای سبک با سختافزارهای تخصصی، پایداری سیستمهای خودگردان را در محیطهای بدون اینترنت تضمین میکند. حذف تاخیر حاصل از رفتوبرگشت داده، دقت واکنشهای آنی را در ناوبری و پایش تجهیزات حساس ارتقا میدهد. این تکامل فنی باعث میشود دستگاههای کوچک به جای انتقال داده، صرفا نتایج تحلیل را گزارش کنند.
یادگیری فدرال و امنیت دادهها
یادگیری فدرال امکان بازآموزی مدلهای سبک را بدون دسترسی مستقیم به دادههای خام کاربران فراهم میسازد. در این روش، پارامترهای مدل روی دستگاههای مختلف بهروزرسانی شده و فقط گرادیانهای محاسباتی برای تجمیع به سرور مرکزی ارسال میشوند. این رویکرد، دیواره امنیتی مستحکمی برای حفاظت از حریم خصوصی در پروژههای حساس ایجاد میکند.
ترکیب این متد با مدلهای کوچک، هزینه آموزش توزیعشده را به شدت کاهش میدهد. مدلها به جای یادگیری از دادههای ایستا، از تعاملات زنده و متنوع در محیطهای واقعی تکامل مییابند. این روند در نهایت منجر به تولید سیستمهای هوشمندی میشود که در عین حفظ مالکیت داده، دانش جمعی شبکه را جذب کردهاند.
برای ساخت و پیادهسازی مدلهای زبانی از کجا شروع کنیم؟
اگر تا اینجا با مفهوم مدلهای زبانی کوچک، معماری ترنسفورمر، تکنیکهای فشردهسازی و کاربردهای واقعی آنها آشنا شدهاید، قدم بعدی یادگیری عملی ساخت و استفاده از این مدلها در پروژههای واقعی است.
در عمل، کار با مدلهای زبانی فقط به دانستن تئوری محدود نمیشود. برای ورود حرفهای به این حوزه باید بتوانید مواردی مثل پردازش متن، پیادهسازی مدلهای NLP، کار با ترنسفورمرها، استفاده از LLMها و بهینهسازی مدلهای زبانی را در محیطهای واقعی پیادهسازی کنید.
در دوره جامع آموزش مدلهای زبانی و پردازش زبان طبیعی یاد میگیرید:
- مبانی کامل NLP و پردازش متن
- معماری ترنسفورمر و نحوه کار مدلهای زبانی
- کار با LLMها و مدلهای مدرن هوش مصنوعی
- پیادهسازی پروژههای عملی پردازش زبان طبیعی
- استفاده از مدلهای زبانی در کاربردهای واقعی مثل چتبات، تحلیل متن و سیستمهای هوشمند
اگر میخواهید از سطح مطالعه درباره مدلهای زبانی عبور کنید و بتوانید بهصورت عملی با مدلهای NLP و LLM کار کنید، آموزش مدل زبانی و پردازش زبان طبیعی میتواند بهترین نقطه شروع برای شما باشد.
سوالات متداول درباره مدلهای زبانی کوچک (SLM)
۱. مدل زبانی کوچک یا SLM چیست؟
مدلهای زبانی کوچک (Small Language Models)، نسخههای بهینه و فشردهای از هوش مصنوعی هستند که با پارامترهای کمتر (معمولاً زیر ۱۰ میلیارد) طراحی شدهاند. این مدلها برخلاف LLMها، با منابع سختافزاری محدود و سرعت بالاتر در حوزههای تخصصی عمل میکنند.
۲. تفاوت اصلی بین LLM و SLM در چیست؟
تفاوت اصلی در مقیاس پارامترها و نیاز پردازشی است. LLMها دانش عمومی وسیعی دارند اما به سرورهای قدرتمند نیاز دارند؛ در حالی که SLMها سبکتر هستند، قابلیت اجرای آفلاین دارند و برای وظایف خاص و محدود، کارایی و دقت بالاتری نسبت به هزینه مصرفی ارائه میدهند.
۳. آیا مدلهای زبانی کوچک میتوانند بدون اینترنت کار کنند؟
بله، یکی از بزرگترین مزایای SLMها قابلیت اجرای محلی (On-device) است. به دلیل حجم کم، این مدلها روی موبایل، لپتاپ و دستگاههای اینترنت اشیا (IoT) بدون نیاز به اتصال به کلاود یا اینترنت قابل اجرا هستند.
۴. تکنیکهای اصلی فشردهسازی مدلهای زبانی کدامند؟
برای تبدیل یک مدل بزرگ به کوچک از روشهایی مانند کوانتیزاسیون (کاهش دقت اعداد)، هرس کردن (حذف وزنهای اضافی)، و تقطیر دانش (آموزش مدل کوچک از روی مدل بزرگ) استفاده میشود.
۵. آیا دقت SLM کمتر از مدلهای غولآسایی مثل GPT-4 است؟
در دانش عمومی و استدلالهای بسیار پیچیده، بله؛ اما در وظایف تخصصی (مانند تحلیل متون حقوقی، پزشکی یا کدنویسی در یک سازمان خاص)، یک SLM که با دادههای هدف آموزش دیده باشد، میتواند عملکردی مشابه یا حتی بهتر از مدلهای بزرگ داشته باشد.
۶. بهترین مدلهای زبانی کوچک فعلی کدامند؟
در حال حاضر مدلهای Phi-3 (مایکروسافت)، Gemma (گوگل)، Llama 3 (8B) (متا) و Mistral جزو قدرتمندترین و محبوبترین مدلهای زبانی سبک در دنیا محسوب میشوند.
۷. چرا یادگیری NLP برای کار با SLMها ضروری است؟
از آنجا که SLMها منابع محدودی دارند، نحوه پردازش متن، پیشپردازش دادهها و تنظیم دقیق (Fine-tuning) آنها اهمیت دوچندان پیدا میکند. درک مفاهیم NLP به شما کمک میکند تا از این مدلهای کوچک، بیشترین بازدهی را استخراج کنید.




















