

در این مطلب از بخش آموزش هوش مصنوعی، به بررسی الگوریتمهای پردازش زبان طبیعی (NLP) میپردازیم. NLP شاخهای از هوش مصنوعی (AI) است که بر توسعه الگوریتمهایی برای درک و پردازش زبان انسان تمرکز دارد. این الگوریتمها رایانهها را قادر میسازند تا زبان انسان را درک، تحلیل و تولید کنند و به این ترتیب، امکان تعاملات طبیعیتر میان انسانها و ماشینها را فراهم میآورند.
الگوریتمهای NLP چگونه کار میکنند؟
تصور کنید بخواهید به یک کودک بیاموزید که چگونه تفاوت میان یک شوخی و یک انتقاد جدی را درک کند؛ این دقیقاً همان چالشی است که در دنیای هوش مصنوعی با آن روبرو هستیم. الگوریتمهای پردازش زبان طبیعی (NLP) در واقع نقش مترجمانی هوشمند را ایفا میکنند که به رایانهها میآموزند چگونه سیل عظیم واژگان انسانی را به کدهایی معنادار تبدیل کرده و مفهوم نهفته در پس هر جمله را درک کنند.
در واقع، این الگوریتمها زیربنای تکنولوژیهایی هستند که هر روز با آنها سروکار داریم؛ از دستیاران صوتی گوشیهای هوشمند گرفته تا سیستمهای ترجمه همزمان. با استفاده از این ابزارها، ماشینها دیگر فقط پردازشگر اعداد نیستند، بلکه به تحلیلگرانی تبدیل شدهاند که میتوانند لحن، احساس و هدف ما از بیان کلمات را متوجه شوند و پاسخی هوشمندانه ارائه دهند.
تعریف الگوریتمهای NLP
الگوریتمهای NLP فرمولهای ریاضی پیچیدهای هستند که برای آموزش رایانهها جهت پردازش و درک زبان طبیعی به کار میروند. این الگوریتمها به ماشینها کمک میکنند تا دادههای حاصل از کلمات مکتوب یا گفتاری را درک کرده و اطلاعات و الگوهای معنادار را استخراج کنند. در اصل، این الگوریتمها مانند واژهنامه عمل میکنند و ماشینها را قادر میسازند تا زبان انسان را بدون نیاز به درک کامل پیچیدگیهای آن، تفسیر کنند.
الگوریتمهای NLP از تکنیکهای مختلفی از جمله تحلیل احساسات، استخراج کلمات کلیدی، گرافهای دانش، ابر کلمات و خلاصهسازی متن برای تحلیل و تفسیر دادههای زبانی استفاده میکنند.
انواع الگوریتمهای NLP
الگوریتمهای پردازش زبان طبیعی اهداف متفاوتی را دنبال میکنند و برای دستیابی به نتایج گوناگون در کاربردهای NLP مورد استفاده قرار میگیرند. در اینجا برخی از انواع رایج آورده شده است:
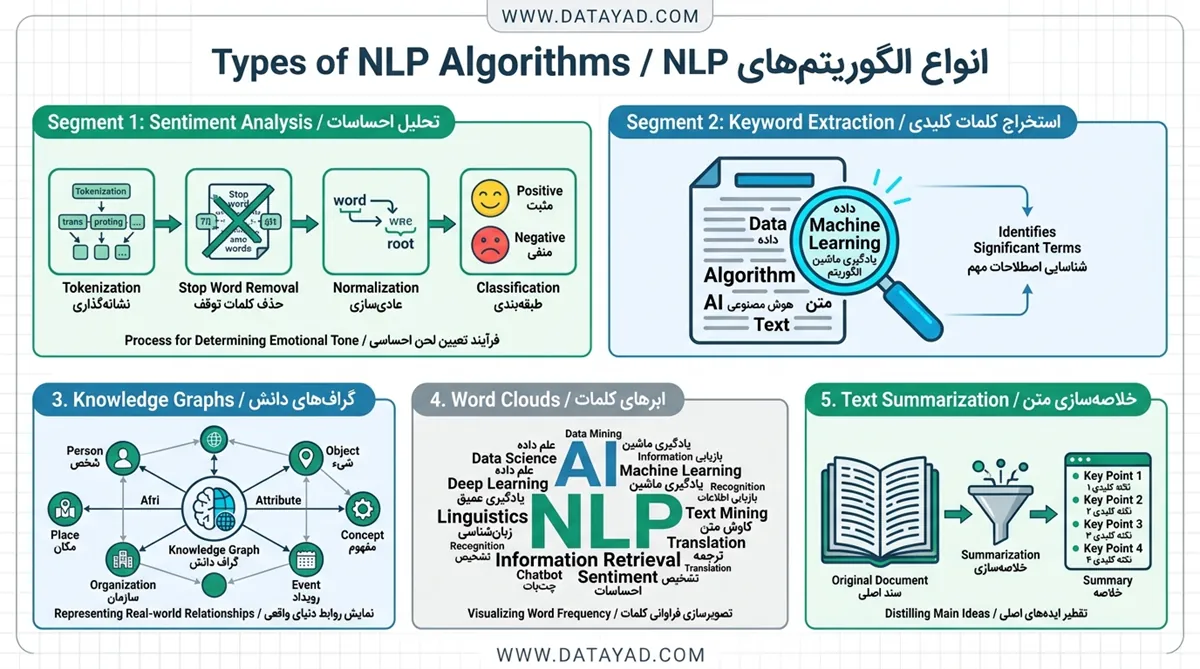
تحلیل احساسات
تحلیل احساسات، متن را به دستههایی از جمله احساسات مثبت، منفی یا خنثی طبقهبندی میکند. این فرآیند شامل چندین مرحله است:
- توکنگذاری (Tokenization): تجزیه متن به کلمات یا توکنهای مجزا.
- حذف کلمات توقف (Stop Words Removal): حذف کلمات رایج (مانند “است”، “یک”، “آن”) که معنای قابل توجهی ندارند.
- نرمالسازی متن (Text Normalization): تبدیل کلمات به شکل پایه یا ریشه آنها (مثلاً تبدیل “میدویدم” به “دویدن”).
- استخراج ویژگی (Feature Extraction): استخراج ویژگیها یا کلمات کلیدی که نشاندهنده احساسات هستند (مانند صفتهایی مثل “خوب” یا “بد”).
- طبقهبندی (Classification): استفاده از الگوریتمهای یادگیری ماشین برای طبقهبندی احساسات، که میتواند دوکلاسه (مثبت/منفی)، چندکلاسه (شادی، غم، خشم) یا بر اساس یک مقیاس (امتیاز ۱ تا ۱۰) باشد.
چالشهای این حوزه شامل برخورد با کنایه، طعنه و اصطلاحات عامیانه است که میتواند بر دقت تعیین احساسات تأثیر بگذارد. با این حال، تحلیل احساسات بهطور گسترده توسط کسبوکارها برای سنجش نظرات مشتریان از طریق بازخوردها استفاده میشود.
استخراج کلمات کلیدی
استخراج کلمات کلیدی، کلمات یا عبارات مهم را از متن شناسایی و استخراج میکند تا موضوعات یا روندها را تعیین نماید. این الگوریتم برای تحلیل حجم زیادی از دادههای متنی بدون ساختار، مانند اسناد، پستهای وبلاگ و صفحات وب مفید است. کسبوکارها از استخراج کلمات کلیدی برای نظارت بر گفتگوهای مشتریان و شناسایی فرصتهای بازار استفاده میکنند.
گرافهای دانش
گرافهای دانش شبکهای از موجودیتهای مهم مانند افراد، مکانها و اشیاء ایجاد میکنند تا روابط میان آنها را درک کنند. این الگوریتم به ماشینها کمک میکند تا بافتار و معناشناسی زبان انسان را درک کرده و فهم تفاوتهای ظریف و پیچیدگیهای زبان را ممکن سازند.
ابر کلمات
ابر کلمات یک نمایش گرافیکی از فراوانی کلمات در متن است که در آن کلمات با تکرار بیشتر، با فونتهای بزرگتر نمایش داده میشوند. ابر کلمات برای شناسایی تمها یا موضوعات برجسته در محتوای متنی، مانند پستهای شبکههای اجتماعی، نظرات مشتریان و بازخوردها استفاده میشوند. آنها خلاصهای بصری و شهودی از متن ارائه میدهند و اغلب در ارائهها به کار میروند.
خلاصهسازی متن
خلاصهسازی متن نسخههای فشردهای از متون طولانی ایجاد میکند و در عین حال مهمترین اطلاعات را حفظ مینماید. این کار میتواند با استفاده از روشهای استخراجی (انتخاب جملات کلیدی) یا روشهای انتزاعی (تولید جملات جدید) انجام شود. کسبوکارها از خلاصهسازی متن برای تحلیل سریع اسناد بزرگ یا بازخوردهای مشتریان استفاده میکنند.
چگونه با الگوریتمهای NLP شروع کنیم
برای پیادهسازی الگوریتمهای پردازش زبان طبیعی، این مراحل را دنبال کنید:
مرحله ۱: مسئله خود را تعیین کنید
مسئله کسبوکار خود را با پرسیدن سوالاتی مانند زیر تعریف کنید:
- چه دادههایی در اختیار دارید؟
- به دنبال چه بینشهایی هستید؟
دقیق بودن در این مرحله به انتخاب الگوریتم مناسب کمک میکند.
مرحله ۲: مجموعهداده خود را شناسایی کنید
مجموعهداده خود را بر اساس مسئلهای که میخواهید حل کنید، شناسایی کنید. این دادهها میتوانند شامل دادههای بازخورد مشتریان، نظرات محصول، پستهای انجمنها یا دادههای شبکههای اجتماعی باشند.
مرحله ۳: پاکسازی دادهها
دادهها را با پاکسازی آماده کنید؛ این کار شامل حذف دادههای نامرتبط، اصلاح غلطهای املایی، تبدیل متن به حروف کوچک و نرمالسازی زبان است. کتابخانههای NLP مانند NLTK و SpaCy و همچنین ابزارهایی مانند TextBlob، Scikit-learn و Stanford CoreNLP میتوانند در پاکسازی دادهها کمک کنند.
مرحله ۴: انتخاب یک الگوریتم
الگوریتمی را بر اساس مسئله کسبوکار خود انتخاب کنید. الگوریتم را با استفاده از مجموعهداده خود و با کمک کتابخانههایی مانند Scikit-learn که ابزارها و الگوریتمهای مختلف NLP را ارائه میدهد، آموزش دهید.
مرحله ۵: تحلیل نتایج خروجی
نتایج خروجی الگوریتم خود را تحلیل کنید. عملکرد را با استفاده از معیارهایی مانند موارد زیر ارزیابی کنید:
- Precision (دقت): صحت الگوریتم در طبقهبندی درست دادهها.
- Recall (بازیافت): نسبت دادههای مرتبطی که به درستی طبقهبندی شدهاند.
- F1 Score (امتیاز F1): ایجاد تعادل بین دقت و بازیافت.
از بصریسازیهایی مانند ابر کلمات برای ارائه نتایج به ذینفعان استفاده کنید.
سوالات متداول در مورد الگوریتمهای پردازش زبان طبیعی
تفاوت بین NLP و NLU چیست؟
NLP (پردازش زبان طبیعی) حوزهای گسترده است که تمام تکنیکهای پردازش و تحلیل زبان انسان را در بر میگیرد. NLU (درک زبان طبیعی) زیرمجموعهای از NLP است که بر درک معنا و قصد نهفته در متن تمرکز دارد.
آیا الگوریتمهای NLP میتوانند چندین زبان را پشتیبانی کنند؟
بله، بسیاری از الگوریتمها و مدلهای NLP را میتوان برای پشتیبانی از چندین زبان تطبیق داد. کتابخانههایی مانند SpaCy و Transformers متعلق به Hugging Face از زبانهای مختلف پشتیبانی میکنند.
برخی از چالشهای رایج در NLP چیست؟
چالشهای رایج شامل مدیریت ابهام در زبان، درک بافتار، برخورد با اصطلاحات کنایی و پردازش زبانهایی با ساختارهای گرامری پیچیده است.
مدلهای پیشآموزشدیده چگونه به NLP کمک میکنند؟
مدلهای پیشآموزشدیده مانند BERT و GPT روی مجموعههای بزرگی از متون آموزش دیدهاند و میتوانند برای وظایف خاص تنظیم (Fine-tune) شوند، که این کار حجم داده و منابع محاسباتی مورد نیاز برای آموزش را کاهش میدهد.
مسیر تخصص در الگوریتمهای NLP
درک الگوریتمهای NLP و نحوه عملکرد آنها، اولین قدم برای ورود به دنیای هیجانانگیز هوش مصنوعی است. اما برای اینکه از یک ناظر تئوری به یک متخصص عملگرا تبدیل شوید و بتوانید از این الگوهای ریاضی برای حل مسائل پیچیده استفاده کنید، نیاز به یک مسیر یادگیری ساختاریافته دارید. دوره جامع LLM و NLP دقیقاً برای توسعهدهندگانی طراحی شده است که قصد دارند به دنیای هوش مصنوعی مولد قدم بگذارند. در این دوره پیشرفته، شما مفاهیم اولیه را به پروژههای واقعی و کاربردی پیوند میزنید.
- تسلط بر مدلهای زبانی بزرگ (LLMs) و تکنیکهای پیشرفته پردازش متن.
- ساخت پروژههای جذاب و هوشمند مانند چتباتهای اختصاصی.
- آموزش عملی پیادهسازی سیستمهای RAG برای استخراج دانش از دادهها.




















