

امروزه باتوجه به حجم انبوه دادههای تولید شده، علم داده به یکی از مهمترین بخشهای صنایع مختلف تبدیل شده است و یکی از موضوعات موردبحث در محافل فناوری اطلاعات به شمار میآید. محبوبیت این تکنولوژی در طول سالهای اخیر افزایش پیدا کرده و شرکتها شروع به پیادهسازی تکنیکهای علم داده برای رشد کسب و کار خود و افزایش رضایت مشتری کردهاند. در این مقاله کاربردهای علم داده، فرآیندها و مشاغل این حوزه را بررسی میکنیم. حجم فزاینده منابع داده و متعاقباً دادههای سازمانی، باعث شده تا علم داده یکی از سریعترین زمینههای درحالرشد در هر صنعتی باشد. در نتیجه جای تعجب نیست که موقعیت شغلی یک متخصص علم داده توسط مؤسسه هاروارد بیزینس ریویو بهعنوان “جذابترین شغل قرن بیست و یک” شناخته شود. برای یادگیری بدون پیش نیاز و کار در حوزه علم داده پیشنهاد میکنیم از دوره علم داده دیتایاد استفاده کنید. همچنین میتوانید با استفاده از سایر دورههای آموزش هوش مصنوعی دیتایاد، دانش خود را در این حوزه گسترش دهید.

علم داده چیست؟
علم داده حوزهای است که با حجم وسیعی از دادهها سر و کار دارد و از ابزارها و تکنیکهای مدرن برای کشف الگوهای پنهان، استخراج اطلاعات معنادار و اتخاذ تصمیمات تجاری استفاده میکند.
در این حوزه، از الگوریتمهای پیچیده یادگیری ماشین برای ساخت مدلهای پیشبینی بهره گرفته میشود. دادههای مورد استفاده در این تحلیلها میتوانند از منابع متنوع و در قالبهای مختلف باشند.
حال که تعریفی مقدماتی از علم داده به دست آوردیم، بیایید به تعریف دقیقتری از این حوزه بپردازیم و بررسی کنیم چرا علم داده در چشمانداز فناوری اطلاعات و کسبوکارها نقش ضروری دارد.
چرا علم داده مهم است؟
اهمیت علم داده به این دلیل است که ابزارها، روشها و فناوریها را برای استخراج معانی پنهان و ارزشمند از دادهها به کار میگیرد. در دنیای امروز، سازمانها و شرکتها با حجم عظیمی از دادهها مواجهاند؛ دادههایی که توسط دستگاهها و حسگرهای گوناگون بهصورت خودکار جمعآوری و ذخیره میشوند.
علاوه بر این، سیستمهای آنلاین، شبکههای اجتماعی و درگاههای پرداخت دادههای بیشتری را در حوزههای متنوعی مانند تجارت الکترونیک، بهداشت و درمان، امور مالی و سایر جنبههای زندگی انسان ثبت و نگهداری میکنند. به همین دلیل، ما اکنون به مجموعهای گسترده و متنوع از دادهها در قالبهای متنی، صوتی، تصویری و ویدیویی دسترسی داریم.
استفاده از علم داده به سازمانها این امکان را میدهد که از این اطلاعات عظیم و پراکنده، الگوهای مفیدی استخراج کنند و به بهبود تصمیمگیریها، بهینهسازی فرایندها و در نهایت ایجاد ارزش افزوده برای مشتریان بپردازند. علم داده همچنین در پیشبینی روندها و آیندهنگری مؤثر است و این مسئله اهمیت آن را در دنیای پررقابت امروز بیشتر میکند.

تاریخچه علم داده
اصطلاح «علم داده» جدید نیست، اما مفهوم و کاربرد آن در طول زمان دستخوش تغییرات بسیاری شده است.
اولینبار در دهه ۱۹۶۰ میلادی، این اصطلاح بهعنوان نامی جایگزین برای علم آمار مطرح شد. در آن زمان، علم داده به رویکردی برای تحلیل دادههای آماری محدود میشد.
در اواخر دهه ۱۹۹۰، متخصصان علوم کامپیوتر تعریف رسمیتری از علم داده ارائه دادند. آنها این حوزه را بهعنوان رشتهای مستقل با چهار جنبه اصلی معرفی کردند:
- طراحی
- جمعآوری
- ذخیره سازی
- تحلیل دادهها
این رویکرد جدید به علم داده، باعث شد که آن بهعنوان حوزهای میانرشتهای با تلفیق دانش آمار، کامپیوتر و تحلیل دادهها در نظر گرفته شود.
تا یک دهه بعد از آن، اصطلاح علم داده بیشتر در فضاهای آکادمیک و پژوهشی مورد استفاده قرار میگرفت.
با این حال، در اوایل قرن بیستویکم، با رشد دادههای دیجیتال و نیاز به تحلیلهای پیچیدهتر، علم داده به ابزاری کلیدی در صنعت و تجارت نیز تبدیل شد.
امروز علم داده بهعنوان یکی از علوم مهم و استراتژیک شناخته میشود که تقریباً تمام صنایع برای پیشبینی روندها و تصمیمگیری بهتر از آن استفاده میکنند.
آینده علم داده
پیشرفتهای هوش مصنوعی و یادگیری ماشین سبب شدهاند که پردازش و تحلیل دادهها با سرعت و بهرهوری بیشتری انجام شود. این تحولات همراه با نیاز فزاینده بخشهای صنعتی به تحلیل داده، اکوسیستمی کامل از دورههای آموزشی، مدارک تحصیلی و فرصتهای شغلی را در حوزه علم داده به وجود آورده است.
از آنجا که علم داده به مجموعهای از مهارتهای میانرشتهای و تخصصی نیاز دارد، پیشبینی میشود که این حوزه در دهههای آینده رشد چشمگیری داشته باشد.
انتظار میرود که کاربردهای گسترده علم داده در زمینههایی مانند پزشکی، مدیریت شهری، صنعت و تجارت الکترونیک، ارزش آن را بیش از پیش برجسته کند و موجب ایجاد فرصتهای جدیدی در مشاغل مرتبط شود.
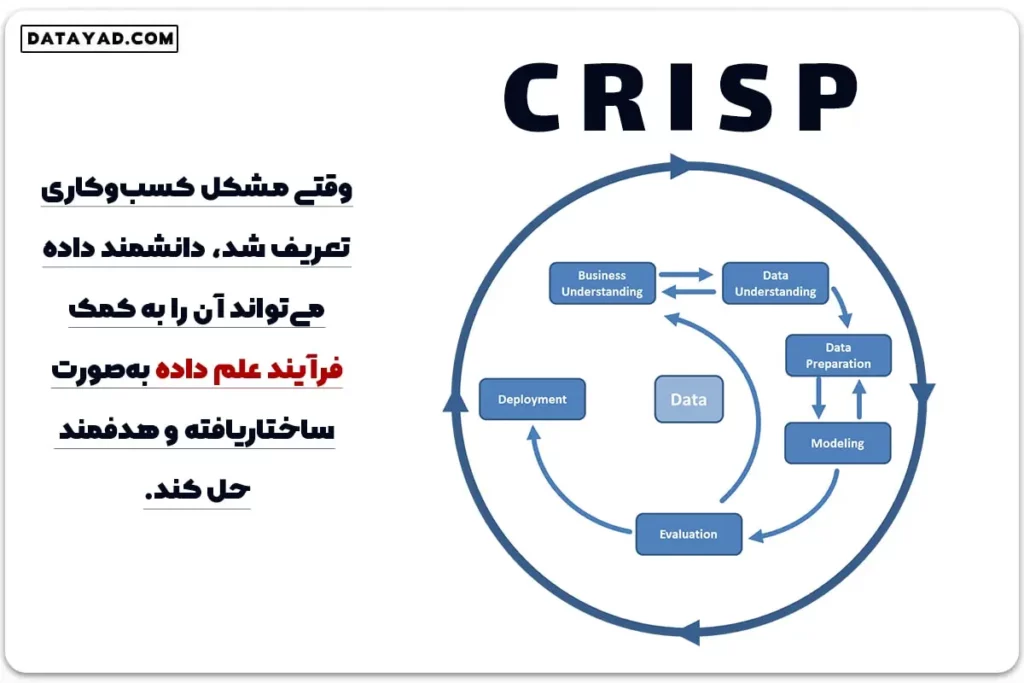
فرآیند علم داده چیست؟
معمولاً یک مسئله در کسبوکارها باعث آغاز فرآیند علم داده میشود. دانشمند داده بهطور نزدیک با سهامداران و مدیران کسبوکار همکاری میکند تا نیازهای اصلی آن را درک کند. پس از تعریف دقیق این مسئله، دانشمند داده میتواند از طریق چارچوب CRISP در علم داده به حل آن بپردازد.
این فرآیند شامل چندین مرحله و استفاده از ابزارها و تکنیکهای مختلف است تا از دادهها ارزش ایجاد کند:
1. درک کسبوکار (Business Understanding)
در این مرحله، تیم دادهها باید دقیقا بداند چه سؤالاتی در کسب و کار باید پاسخ داده شوند. تعریف دقیق مسئله به روشنسازی هدف اصلی کمک میکند و فرآیندهای بعدی را هدایت میکند. بدون تعریف دقیق، فرآیند ممکن است به نتایج کمارزش منجر شود.
2. درک دادهها (Data Understanding)
پس از تعریف مسئله، مرحله بعدی جمعآوری و بررسی دادهها است. در این مرحله، دادهها به منظور شناسایی الگوها، بررسی کیفیت دادهها و تشخیص نقاط ضعف و قدرت آنها تجزیه و تحلیل میشوند. این مرحله شامل جمع آوری داده ها، بررسی اولیه دادهها، تحلیلهای توصیفی و درک بهتر از منابع داده است.
3. آمادهسازی دادهها (Data Preparation)
مرحله آمادهسازی دادهها شامل تمیز کردن دادهها، انتخاب ویژگیهای مناسب و در برخی موارد ترکیب یا تغییر ساختار دادهها است. هدف از این مرحله، ایجاد مجموعهای از دادههای آماده و بهینه است که برای مدلسازی استفاده خواهد شد. این فرآیند شامل حذف نویز، جایگزینی مقادیر از دسترفته و استانداردسازی دادهها میباشد.
4. مدلسازی (Modeling)
در این مرحله، مدلهای یادگیری ماشین یا آماری برای تحلیل دادهها و پیشبینی نتایج توسعه داده میشوند. با توجه به مسئله و نوع دادهها، مدلهای مختلفی مانند رگرسیون، دستهبندی و خوشهبندی انتخاب و تنظیم میشوند. در این مرحله، پارامترهای مدلها تنظیم شده و دادهها برای به دست آوردن بهترین نتیجه به مدل تغذیه میشوند.
5. ارزیابی (Evaluation)
پس از ساخت مدلها، عملکرد آنها ارزیابی میشود تا اطمینان حاصل شود که مدلها به درستی به اهداف کسبوکار پاسخ میدهند. معیارهایی مانند دقت، حساسیت، دقت پیشبینی، امتیاز F1 و دیگر معیارها برای ارزیابی عملکرد مدلها استفاده میشوند. در این مرحله، مدلها ممکن است بهروزرسانی یا بهینهسازی شوند تا نتایج بهتری ارائه دهند.
6. پیادهسازی (Deployment)
آخرین مرحله از فرآیند CRISP، پیادهسازی مدل در محیط عملیاتی است. در این مرحله، مدلها در سیستمهای عملیاتی مستقر میشوند و مورد استفاده قرار میگیرند. فرآیند پیادهسازی شامل مانیتورینگ مدل و اطمینان از عملکرد صحیح آن در دنیای واقعی است. بسته به نیاز کسبوکار، این مرحله ممکن است شامل گزارشگیری، تولید داشبوردهای مدیریتی یا بهکارگیری مدلها در سیستمهای تصمیمگیری باشد.
نظارت و بهبود مداوم (Monitoring and Continuous Improvement)
علم داده یک فرآیند تکرارشونده است که نیاز به توجه و نگهداری مداوم دارد. برای اطمینان از انطباق مدلها با تغییرات دادهها و نیازهای جدید، نظارت و بهروزرسانی آنها امری ضروری است. با گذشت زمان، مدلها ممکن است به تنظیمات بیشتری نیاز داشته باشند تا عملکرد و کارایی مطلوب خود را حفظ کنند. به همین دلیل، ایجاد یک چرخه دائمی از بررسی و بهبود، کلید موفقیت در علم داده محسوب میشود.
فرآیند CRISP با ساختار تکرارشوندهاش به تیمهای علم داده این امکان را میدهد که به طور مرحلهای و سیستماتیک فرآیند استخراج دانش از دادهها را به انجام برسانند. این مدل انعطافپذیری و امکان بازبینی مراحل مختلف را فراهم میکند و به سازمانها کمک میکند تا با اتخاذ تصمیمات مبتنی بر داده، مزیت رقابتی قابل توجهی کسب کنند. بهعلاوه، با استفاده از این فرآیند، تیمها میتوانند به سرعت به تغییرات در دادهها و نیازهای بازار پاسخ دهند و بدین ترتیب، به بهبود مستمر عملکرد خود ادامه دهند.

روشهای علم داده در مطالعه دادهها
خوب است اینجا بدانیم که علم داده برای مطالعه داده ها، به 4 روش مورد استفاده قرار می گیرد:
1. تحلیل توصیفی (Descriptive Analysis)
تحلیل توصیفی به بررسی دادهها میپردازد تا در مورد آنچه که در محیط دادهای اتفاق میافتد یا ممکن است اتفاق بیفتد، دانش و آگاهی کسب کند.
از ویژگیهای بارز این نوع تحلیل، مصورسازیهایی مانند:
- نمودار دایره ای،
- نمودار میله ای،
- گراف های خطی،
- جدول ها
- سایر موارد
می باشد.
بهعنوان مثال، یک شرکت ارائهدهنده خدمات رزرو بلیت هواپیما ممکن است دادههایی مانند تعداد بلیتهای رزرو شده در هر روز را ثبت و نگهداری کند.تحلیل توصیفی میتواند به شناسایی زمانهای اوج و رکود رزرو بلیت و ماههایی که این شرکت بهترین عملکرد را دارد، کمک کند.
2. تحلیل تشخیصی (Diagnostic Analysis)
تحلیل تشخیصی به ارزیابی و بررسی عمیق و مفصل دادهها برای درک دلایل وقوع یک اتفاق میپردازد. این نوع تحلیل شامل تکنیکهایی مانند:
- تکنیک شکستن مسئله (Drill-Down)
- کشف دانش از دادهها (Data Discovery)
- داده کاوی (Data Mining)
- بررسی همبستگی و وابستگی (Correlation Analysis)
چندین تغییر و عملیات مختلف دادهای روی یک مجموعه داده (Data Set) انجام میشود تا الگوهای منحصر به فرد در هر یک از این تکنیکها کشف شود.
بهعنوان مثال، این شرکت خدمات رزرو بلیت پرواز میتواند واکاوی دقیقی روی ماههایی که فروش موفقی داشتهاند، انجام دهد تا دلیل این اوجگیری رزرو بلیت را درک کند. این تحلیل ممکن است منجر به کشف این حقیقت شود که مشتریان زیادی برای حضور در یک رویداد ورزشی خاص به یک شهر خاص سفر میکنند.
3. تحلیل پیشبینیکننده (Predictive Analysis)
تحلیل پیشبینیکننده از دادههای تاریخی برای انجام پیشبینیهای دقیق در مورد الگوهای دادهای که ممکن است در آینده رخ دهد، استفاده میکند. ویژگیهای این نوع تحلیل شامل تکنیکهایی مانند:
- یادگیری ماشین (Machine Learning)
- پیشنگری- برآوردی احتمالی از وقوع پدیده ای در آینده (Forecasting)
- تطبیق الگو (Pattern Matching)
- مدلسازی پیشبینیکننده (Predictive Modeling)
در این تکنیکها، کامپیوترها یاد میگیرند که ارتباطات علیت موجود در دادهها را شبیهسازی کنند. بهعنوان مثال، شرکت خدمات رزرو بلیت هواپیما ممکن است در ابتدای سال از علم داده برای پیشبینی الگوهای رزرو بلیت در طول سال استفاده کند.
الگوریتمهای مربوطه میتوانند دادههای پیشین را بررسی کرده و زمان اوج رزرو بلیت را برای مقصدهای خاص در ماههای معین پیشبینی کنند. این تحلیل به شرکت کمک میکند تا نیازمندیهای پرواز مشتریان بالقوه خود را شناسایی کرده و از این طریق تبلیغات هدفمند را آغاز کند.
4. تحلیل تجویزی (prescriptive analysis)
تحلیل تجویزی یک مرحله پیشرفتهتر از تحلیل پیشبینیکننده است. این نوع تحلیل نهتنها پیشبینی میکند که چه احتمالاتی وجود دارد، بلکه واکنشهای بهینه را نیز برای این احتمالات ارائه میدهد.
ابزارهای مورد استفاده در این نوع تحلیل شامل:
- تحلیل گراف (Graph Analysis)
- شبیهسازی (Simulation)
- مدیریت و تحلیل رویدادهای پیچیده (Complex Event Management)
- شبکههای عصبی (Neural Networks)
- سیستمهای توصیهگر (Recommendation Systems)
برای مثال، تحلیل تجویزی میتواند به بررسی و ارزیابی کمپینهای بازاریابی گذشته بپردازد تا بهترین استراتژیها را برای حداکثر کردن سود در دورههای اوج رزرو بلیت شناسایی کند. یک دانشمند داده میتواند با استفاده از دادههای موجود، تخمین بزند که با توجه به سطح سرمایهگذاری و هزینههای تبلیغاتی در کانالهای مختلف، چه میزان از رزرو بلیت قابل انتظار است. این تحلیل به شرکت خدمات رزرو بلیت هواپیما کمک میکند تا با اطلاعات دقیقتری در تصمیمگیریهای بازاریابی خود عمل کند و از فرصتهای بازار بهرهبرداری کند.
بهطور کلی، علم داده با استفاده از این چهار نوع تحلیل به سازمانها کمک میکند تا درک بهتری از دادههای خود داشته باشند و تصمیمات بهتری بگیرند. این روند نهتنها به بهبود عملکرد کسبوکارها کمک میکند، بلکه زمینهساز نوآوری و رشد در صنایع مختلف خواهد بود.

کاربردهای علم داده
شرکتها میتوانند از کاربردهای گسترده علم داده بهرهمند شوند. کاربردهای رایج علم داده شامل بهینهسازی فرایندها از طریق اتوماسیون هوشمند و هدفگذاری و شخصیسازی پیشرفته برای بهبود تجربه مشتری (CX) است. علاوه بر این، نمونههای دیگری نیز وجود دارند که عبارتاند از:
- بانکها با استفاده از مدلهای ریسک اعتباری که مبتنی بر یادگیری ماشین و معماری ترکیبی محاسبات ابری هستند، میتوانند خدمات وام خود را سریعتر از طریق یک اپلیکیشن تلفن همراه ارائه دهند که هم قدرتمندتر و هم امنتر است.
- شرکتهای الکترونیکی در حال توسعه حسگرهای سهبعدی فوقالعادهای برای هدایت خودروهای بدون راننده هستند. این راهکار به ابزارهای علم داده و تجزیهوتحلیل داده برای ارتقای قابلیتهای مربوط به تشخیص اشیا در لحظه نیاز دارد.
- ارائهدهندگان خودکارسازی فرایند رباتیک (RPA) با طراحی راهکارهایی برای استخراج و اتوماسیون فرآیندهای کسبوکار، قادرند زمان رسیدگی به حوادث را برای شرکتها به طور قابل توجهی کاهش دهند. این کاهش زمان میتواند بین ۱۵ تا ۹۵ درصد متغیر باشد و به عواملی مانند نوع فرایند، پیچیدگی سیستم و فناوریهای مورد استفاده بستگی دارد. بهعلاوه، RPA میتواند به سیستمهای تحلیل داده و یادگیری ماشین متصل شود تا با بررسی محتوای ایمیلهای مشتریان، احساسات و اولویتهای آنها را شناسایی کند. این امر به تیمهای خدمات مشتری کمک میکند تا ایمیلها و درخواستهای مهمتر را شناسایی و به آنها سریعتر پاسخ دهند.
- رسانه دیجیتال با تجزیهوتحلیل رفتار مخاطبان خود بررسی میکند که چه چیزی مخاطبان تلویزیون را درگیر میکند. برای این کار از تجزیهوتحلیل عمیق دادهها و یادگیری ماشین برای جمعآوری بینش از دادهها استفاده میکند تا بتواند رفتار بیننده را تشخیص دهد.
- پلیس شهری از ابزارهای تجزیهوتحلیل آماری برای تجزیهوتحلیل حوادث استفاده میکند تا به افسران کمک کند بفهمند چه زمانی و در چه موقعیتی باید منابع را مستقر کنند تا بتوانند از وقوع جرم جلوگیری کنند. این راهکار مبتنی بر داده، گزارشها و داشبوردهایی را برای افزایش آگاهی میدانی افسران فراهم میآورد.
- ایجاد یک پلتفرم ارزیابی پزشکی مبتنی بر هوش مصنوعی که میتواند سوابق پزشکی موجود را تجزیهوتحلیل کند و بیماران را بر اساس خطر تجربه سکته مغزی یا دیگر بیماریها طبقهبندی کند. به این ترتیب میتواند میزان موفقیت برنامههای درمانی مختلف را برای بیماران پیشبینی کند.

نقش و وظایف یک دانشمند داده (Data Scientist)
دانشمندان داده از ترکیبی از تکنیکها، ابزارها و فناوریهای پیشرفته برای تجزیه و تحلیل دادهها و استخراج بینشهای ارزشمند استفاده میکنند. وظیفه اصلی آنها این است که بهکمک دادهها، مسائل پیچیده کسبوکار را حل کنند و به تصمیمگیریهای هوشمندانه کمک نمایند.
نقش یک دانشمند داده به چندین عامل بستگی دارد:
-
ابعاد سازمان: در شرکتهای بزرگ، یک دانشمند داده معمولاً با تیمهای مختلفی از جمله تحلیلگران، مهندسان و متخصصان یادگیری ماشین همکاری میکند تا پروژههای علمی داده را از ابتدا تا انتها مدیریت کند.
-
تیمهای کوچک: در تیمهای کوچکتر، یک دانشمند داده ممکن است چندین نقش مختلف را بهتنهایی بر عهده بگیرد. این ممکن است شامل تجزیه و تحلیل، مهندسی داده و یادگیری ماشین باشد.
وظایف کلیدی یک دانشمند داده عبارتند از:
-
جمعآوری و تحلیل دادهها: درک عمیق از نیازهای کسبوکار و شناسایی مسائل کلیدی.
-
استفاده از تکنیکهای پیشرفته: بهکارگیری آمار، یادگیری ماشین و هوش مصنوعی برای تحلیل دادهها و استخراج بینشها.
-
توسعه ابزار و مدلها: ایجاد برنامهها و مدلهایی که میتوانند بهصورت خودکار دادهها را پردازش و تحلیل کنند.
-
توضیح نتایج: بیان واضح و مؤثر نتایج به تصمیمگیرندگان بهگونهای که قابل فهم باشد، حتی برای کسانی که تجربه فنی کمتری دارند.
-
همکاری با تیمها: کار مشترک با سایر اعضای تیم برای رسیدن به اهداف مشترک و حل مشکلات کسبوکار.
بهطور خلاصه، دانشمندان داده نقش حیاتی در تبدیل دادههای خام به اطلاعات ارزشمند ایفا میکنند و به سازمانها کمک میکنند تا تصمیمات بهتری بگیرند و در بازار رقابتی پیشرفت کنند.
مبانی و تکنیکهای علم داده
در علم داده، تکنیکها و روشها بهصورت متنوعی وجود دارند، اما اصول و مبانی اساسی آنها شامل مراحل زیر است:
-
آموزش ماشین: در ابتدا، یک مدل یادگیری ماشین باید با استفاده از یک دیتاست مشخص و شناختهشده آموزش داده شود. بهعنوان مثال، برای طبقهبندی احساسات، کلیدواژههایی نظیر «خوشحال» بهعنوان مثبت و «نفرت» بهعنوان منفی به مدل ارائه میشود.
-
تجزیه و تحلیل دادههای جدید: پس از آموزش، مدل باید قادر باشد دادههای جدید و ناشناخته را دریافت کند و بهصورت مستقل آنها را طبقهبندی کند. این مرحله شامل ارزیابی و پیشبینی نتایج براساس یادگیریهای قبلی مدل است.
-
مدیریت خطا و عدم قطعیت: در این مرحله، باید به عدم صحت و اشتباهات در نتایج توجه شود. مدل باید توانایی مدیریت احتمالهای مختلف و در نظر گرفتن عوامل نااطمینانی را داشته باشد. این مساله شامل استفاده از تکنیکهایی برای ارزیابی دقت پیشبینیها و بهبود مستمر مدل است.
با رعایت این اصول، میتوان به تحلیل دقیقتری از دادهها و استخراج بینشهای ارزشمند دست یافت.
علم داده بهطور مداوم در حال پیشرفت است و با بهکارگیری این مبانی، میتوان در مسیر تحلیل دادهها و حل مسائل پیچیده کسبوکار گام برداشت.
تکنیکهای مورد استفاده در علم داده
متخصصان علم داده از سیستمهای کامپیوتری برای پیشبرد فرآیند علم داده استفاده میکنند. مهمترین تکنیکهای بهکاررفته توسط دانشمندان داده عبارتند از:
طبقه بندی (Classification)
طبقهبندی یکی از تکنیکهای اساسی در علم داده و یادگیری ماشین است که به فرآیند دستهبندی دادهها به گروهها یا کلاسهای مشخص اشاره دارد. این تکنیک به کامپیوترها این امکان را میدهد که دادهها را شناسایی و بهطور مؤثر مرتب کنند. الگوریتمهای طبقهبندی با استفاده از دیتاستهای شناختهشده آموزش میبینند تا الگوها و روابط موجود در دادهها را شناسایی کنند و بر اساس آنها تصمیمگیری کنند. این الگوریتمها به سرعت قادر به پردازش و دستهبندی دادهها هستند. در زیر چند نمونه از کاربردهای رایج طبقهبندی آورده شده است:
-
مرتبسازی محصولات: محصولات میتوانند به دو دسته محبوب و نامحبوب تقسیم شوند. این دستهبندی به کسبوکارها کمک میکند تا تصمیمات بهتری در زمینه مدیریت موجودی و بازاریابی اتخاذ کنند.
-
ارزیابی درخواستهای بیمه: درخواستهای بیمه میتوانند بر اساس سطح ریسک به دو گروه با ریسک بالا و ریسک پایین تقسیمبندی شوند. این کار به شرکتهای بیمه کمک میکند تا در ارزیابی ریسک و تعیین حق بیمه مناسب مؤثرتر عمل کنند.
-
تحلیل نظرات در شبکههای اجتماعی: نظرات کاربران میتوانند به دستههای مثبت، منفی یا خنثی تقسیم شوند. این تحلیل به شرکتها کمک میکند تا احساسات مشتریان را بهتر درک کرده و خدمات خود را بهبود دهند.
-
شناسایی چهره: سیستمهای شناسایی چهره میتوانند تصاویر افراد را به دستههای شناختهشده و ناشناخته تقسیم کنند. این تکنیک در امنیت و احراز هویت کاربردهای زیادی دارد.
-
شناسایی ایمیلهای اسپم: الگوریتمهای طبقهبندی میتوانند ایمیلها را به دو دسته اسپم و غیر اسپم تقسیم کنند. این قابلیت به کاربران کمک میکند تا از دریافت ایمیلهای ناخواسته جلوگیری کنند.
- تشخیص بیماریها: در پزشکی، الگوریتمهای طبقهبندی میتوانند نتایج آزمایشها را به دو گروه مبتلا به بیماری و غیر مبتلا تقسیم کنند. این امر به پزشکان در تشخیص سریعتر و دقیقتر بیماریها کمک میکند.
بهطور کلی، متخصصان علم داده از سیستمهای کامپیوتری و الگوریتمهای طبقهبندی بهمنظور استخراج بینشهای ارزشمند از دادهها بهره میبرند. این رویکرد به آنها این امکان را میدهد که تصمیمات هوشمندانهتری بر اساس دادههای موجود اتخاذ کنند و فرایندهای تجاری را بهینهسازی نمایند. با استفاده از این تکنیکها، سازمانها میتوانند به تحلیل عمیقتری از رفتار مشتریان و روندهای بازار دست یابند و در نهایت، عملکرد خود را بهطور مؤثرتری ارتقا دهند.
رگرسیون (Regression)
رگرسیون یک تکنیک آماری است که به تحلیل و مدلسازی روابط میان متغیرها میپردازد. این روش به ما این امکان را میدهد تا بفهمیم چگونه تغییرات در یک یا چند متغیر مستقل (پیشبینیکننده) میتواند بر یک متغیر وابسته (پیشبینیشده) تأثیر بگذارد.
رگرسیون معمولاً با استفاده از مدلهای ریاضی، مانند معادلات خطی یا غیرخطی، انجام میشود و نتایج آن میتواند در قالب گرافها یا منحنیها نمایش داده شود. با استفاده از این روش، میتوانیم مقادیر آینده را بر اساس دادههای موجود پیشبینی کنیم.
به عنوان مثال:
-
پیشبینی نرخ شیوع بیماریها با استفاده از دادههای مربوط به دما، رطوبت و الگوهای جوی و ….
-
تحلیل ارتباط بین رضایتمندی مشتری و تعداد کارمندان برای شناسایی تأثیرات نیروی کار بر تجربه مشتری.
- بررسی رابطه بین تعداد ایستگاههای آتشنشانی و میزان جراحات ناشی از آتشسوزی در یک منطقه خاص، به منظور بهینهسازی تخصیص منابع.
رگرسیون ابزاری قدرتمند است که به متخصصان علم داده کمک میکند تا تصمیمات آگاهانهتری بر اساس تحلیلهای دقیقتری از دادهها اتخاذ کنند.
خوشه بندی (Clustering)
خوشه بندی یکی از تکنیکهای اصلی در علم داده و یادگیری ماشین است که به منظور گروهبندی دادهها بر اساس ویژگیهای مشترک آنها به کار میرود. این روش به شناسایی الگوها و ناهنجاریها (آنامولیها) کمک میکند.
خوشه بندی با مرتب کردن (sorting) تفاوت دارد؛ زیرا در مرتب کردن، دادهها بر اساس یک معیار خاص ترتیب مییابند، در حالی که در خوشه بندی، دادهها به گروههایی تقسیم میشوند که در آنها شباهت بیشتری وجود دارد و هر گروه نمایانگر یک خوشه است. این خوشهها میتوانند به ما کمک کنند تا روابط و الگوهای جدید را در دادهها شناسایی کنیم.
-
گروه بندی مشتریان: شناسایی مشتریانی با رفتار خرید مشابه، به شرکتها این امکان را میدهد که خدمات و پیشنهادات خود را به طور خاص برای هر گروه بهینهسازی کنند و تجربه مشتریان را بهبود بخشند.
-
تحلیل ترافیک شبکه: با خوشه بندی دادههای ترافیک شبکه، میتوان الگوهای استفاده روزمره را شناسایی کرده و به سرعت به حملات شبکه پاسخ داد. این کار به امنیت سایبری کمک میکند.
-
شناسایی محتوای جعلی: با گروه بندی مقالات بر اساس ویژگیهای مشترک، میتوان به شناسایی محتواهای خبری جعلی و ساختگی پرداخت و از این طریق به بهبود کیفیت اطلاعات در دسترس کمک کرد.
-
تحلیل دادههای پزشکی: خوشه بندی میتواند به شناسایی الگوهای جدید در دادههای بیماران کمک کند، مانند شناسایی گروههایی از بیماران با شرایط مشابه که نیاز به درمانهای خاص دارند.
نتیجهگیری و جمع بندی
علم داده، بهعنوان یک رشته بینرشتهای، نقش بسزایی در دنیای امروز ایفا میکند. با توجه به افزایش چشمگیر حجم دادهها و نیاز به تجزیه و تحلیل آنها، علم داده به ابزاری کلیدی برای سازمانها و کسبوکارها تبدیل شده است. این علم با استفاده از تکنیکها و روشهای مختلف مانند یادگیری ماشین، آمار، و تحلیل داده، به شناسایی الگوها و استخراج بینشهای ارزشمند از دادهها کمک میکند.
کاربردهای علم داده در صنایع مختلف، از بهداشت و درمان گرفته تا مالی، به طرز چشمگیری گسترش یافته است. با بهرهگیری از این علم، سازمانها قادرند تصمیمات مبتنی بر داده اتخاذ کنند، کارایی خود را افزایش دهند و تجربه مشتری را بهبود بخشند. بهعلاوه، علم داده به ما این امکان را میدهد که به چالشهای پیچیدهتری پاسخ دهیم و نوآوریهای جدیدی را ایجاد کنیم.
در نهایت، با توجه به پیشرفتهای سریع فناوری و دسترسی روزافزون به دادهها، علم داده به یک مهارت ضروری برای متخصصان و سازمانها تبدیل شده است.
آیا آمادهاید تا مسیر شغلی خود را به سطحی بالاتر ببرید و در دنیای جذاب و روبهرشدی مثل علم داده و هوش مصنوعی بدرخشید؟ ما دورههای جامع و کاملی را در دیتایاد طراحی کردهایم تا شما را برای ورود به بازار کار آماده کنیم. اگر به موضوعات هیجانانگیزی مانند هوش مصنوعی و علم داده علاقه دارید، پیشنهاد میکنیم با توجه به نیازتان، از دورههای هوش مصنوعی و آموزش دیتا ساینس بهره ببرید و مهارتهای ارزشمندی را کسب کنید.














عالی و مفید بود
متشکرم، خوشحالم که برات مفید بود
دم شما گرم، پر قدرت ادامه بدین
مرسی از انرژی خوبت
من می خوام وارد این مسیر یادگیری علم داده بشم
به زودی گام به گام بهتون میگیم چیکار کنین که بدون سردرگمی خیلی راحت بتونین وارد این مسیر بشین و ادامه اش بدین
ممنونم از اینکه انقدر جامع در مورد علم داده گفتید، کاش در مورد دانشمند داده بیشتر توضیح می دادین.
لطف داری، برای این مورد که گفتی می تونی این اموزش زیر رو ببینی، روی لینک زیر کلیک کن:
آموزش متخصص علم داده
عالی بود، 5 دقیقه زمان برد خوندنش اما کلی اطلاعات جدید یاد گرفتم. مرسی از سایت خوب تون
ممنونم احسان عزیز، خوشحالم که برات مفید و کاربردی بود