

تعبیه سازی یا Embedding در یادگیری ماشین روشی برای نمایش دادهها به شکل بردارهای عددی در یک فضای پیوسته هست. این بردارها معنا و ارتباط بین داده ها را به تصویر میکشند، به طوری که آیتمهای مشابه به یکدیگر نزدیکتر و آیتمهای متفاوت از هم دورتر قرار میگیرند. این ویژگی، کار الگوریتمها را برای درک داده های پیچیده آسان تر میکند. الگوریتمی مثل سیستم توصیه گر یا مدلهای NLP.
از کارکرد و مزایای تعبیه سازی (Embedding) به موارد زیر میتوان اشاره کرد:
- دادههای دستهای (Categorical) یا دادههایی با ابعاد زیاد (High-dimensional) را به بردارهای متراکم (Dense Vectors) تبدیل میکند.
- به مدلهای یادگیری ماشین کمک میکند تا انواع مختلف داده را بهتر درک کرده و با آنها کار کنند.
- این بردارها به درک معنای اشیا و نحوه ارتباط آنها با یکدیگر کمک میکنند.
Embedding به طور گسترده در حوزههایی مانند پردازش زبان طبیعی (NLP)، سیستمهای توصیهگر و بینایی کامپیوتر استفاده میشود.
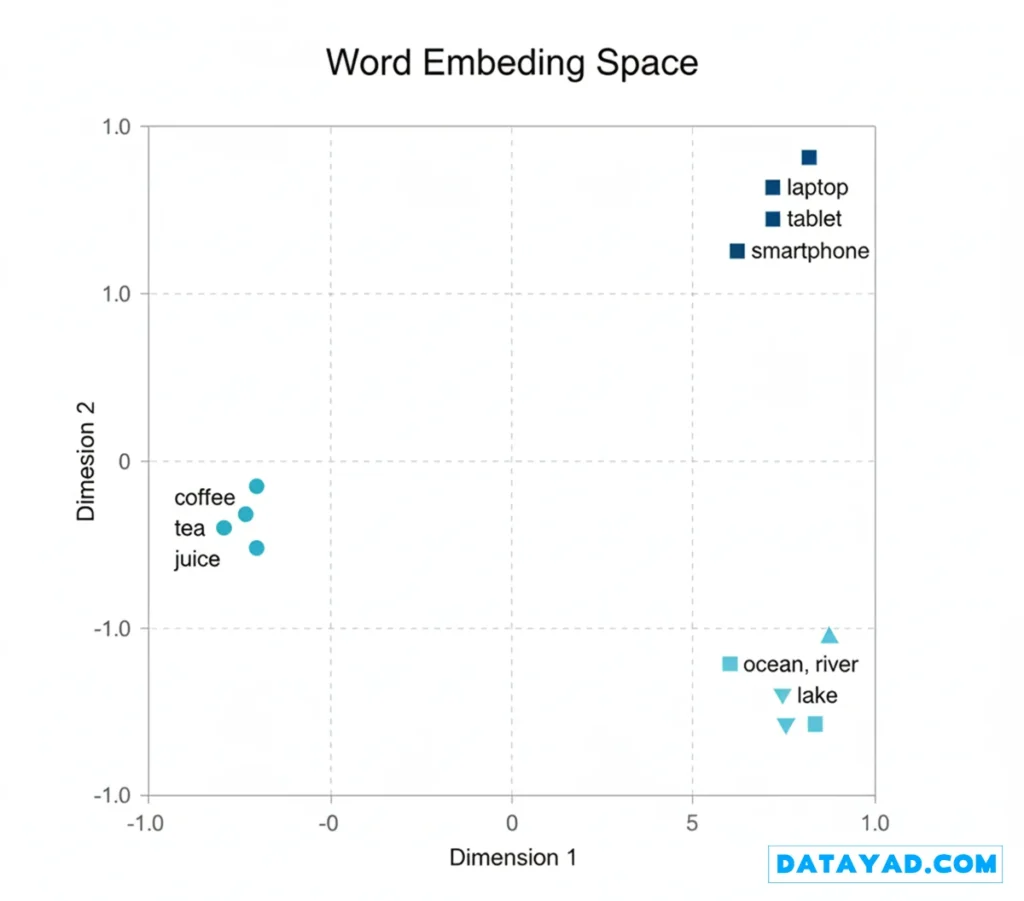
برای مثال، کلماتی مانند «لپتاپ»، «تبلت» و «موبایل» در کنار هم خوشهبندی شدهاند که نشاندهنده شباهت معنایی (Semantic Similarity) آنها است.
به همین ترتیب، «قهوه»، «چای»، «نوشیدنی» خوشه دیگری را تشکیل دادهاند که نشاندهنده ویژگیهای مشترک آنها (مانند نوشیدنی) است.
یک شکاف قابل توجه بین این دو خوشه وجود دارد که تفاوت معنایی و عدم ارتباط آنها در یک زمینه مشترک را برجسته میکند.
اصطلاحات کلیدی مرتبط با تعبیه سازی (Embedding)
۱. بردار (Vector)
بردار (Vector) لیستی از اعداد است که یک اندازه و یک جهت را توصیف میکند. در یادگیری ماشین، بردار معمولا به مجموعهای از اعداد گفته میشود که ویژگیها یا خصوصیات یک چیز را نشان میدهد.
- مثال: در یک فضای دو بعدی، بردار [3, 4] به 3 واحد در امتداد محور X و 4 واحد در امتداد محور Y اشاره دارد. طول کلی (اندازه) این بردار 5 هست.
۲. بردار متراکم (Dense Vector)
بردار متراکم (Dense Vector) نوعی بردار هست که بیشتر اعداد داخل آن صفر نیستند. در یادگیری ماشین، بردارهای متراکم اغلب برای توصیف چیزهایی مانند کلمات، تصاویر یا نقاط داده استفاده میشوند، چون جزئیات زیادی را در خود ذخیره میکنند.
- مثال: بردار [10, 1, 2, 100] میتواند مشخصات یک خانه را نشان دهد، مثلا: متراژ، تعداد اتاق خواب، تعداد حمام و سن بنا.
۳. فضای برداری (Vector Space)
فضای برداری (Vector Space) یا فضای خطی، یک ساختار ریاضی هست که از مجموعهای از بردارها تشکیل شده. این بردارها را میتوان با هم جمع کرد یا در اعداد (اسکالرها) ضرب کرد، در حالی که از ویژگیهای خاصی هم پیروی میکنند.
- این فضاها باید ویژگیهایی مانند «بسته بودن نسبت به جمع» (Closure under addition) و «بسته بودن نسبت به ضرب اسکالر» را داشته باشند.
- مثال: مجموعهی تمام بردارهای سهبعدی (3D) با مختصات اعداد حقیقی، یک فضای برداری را تشکیل میدهد. بردارهایی مانند [1, 0, 0]، [0, 1, 0] و [0, 0, 1] پایههای (basis) این فضای برداری سهبعدی هستند.
۴. فضای برداری پیوسته (Continuous Vector Space)
فضای برداری پیوسته (Continuous Vector Space) نوع خاصی از فضای برداری هست که در آن هر مقدار میتواند هر عدد حقیقی (و نه فقط اعداد صحیح) باشد.
- در بحث Embedding، این مفهوم به این معناست که هر شیء را میتوان با اعدادی توصیف کرد که قابلیت تغییرات نرم و پیوسته را دارند.
- مثال: رنگ [0.1, 0.3, 0.9] در مدل رنگی RGB، طیفی از رنگ قرمز را نشان میدهد. در این مدل، هر یک از این سه عدد میتوانند هر مقداری بین 0 و 1 باشند.

تعبیه سازی (Embedding) چگونه کار میکنند؟
۱. تعریف سیگنال شباهت
اول، باید مشخص کنیم که میخواهیم مدل چه چیزهایی را به عنوان «مشابه» در نظر بگیرد.
- متن: کلمات یا جملاتی که در زمینههای (Context) مشابهی استفاده میشوند.
- تصاویر: عکسهایی از یک شیء یا صحنه یکسان.
- گرافها: گرههایی (Nodes) که به هم متصل یا مرتبط هستند.
۲. انتخاب ابعاد (Dimensionality)
در این مرحله انتخاب میکنیم که هر آیتم با چند عدد (یعنی چند بُعد) توصیف شود. این تعداد میتواند ۶۴، ۳۸۴، ۷۶۸ یا حتی بیشتر باشد.
- ابعاد بیشتر: جزئیات بیشتری را ذخیره میکند، اما مدل کندتر شده و حافظه بیشتری مصرف میکند.
- ابعاد کمتر: مدل سریعتر است، اما ممکن است بخشی از جزئیات مهم را از دست بدهد.
۳. ساخت اِنکودر (Encoder)
انکودر همان مدلی است که دادههای ورودی ما را به یک لیست از اعداد (یعنی همان بردار) تبدیل میکند:
- متن: مدلهای زبانی مانند BERT.
- تصاویر: مدلهای بینایی مانند CNN یا ViT.
- صدا (Audio): مدلهایی که صدا را پردازش میکنند (مثلاً ابتدا آن را به طیفنگاره یا اسپکتروگرام تبدیل میکنند).
- گرافها: روشهایی مانند Node2Vec یا شبکههای عصبی گرافی (GNN).
- دادههای جدولی (Tabular): مدلهایی که ویژگیهای مختلف را فشرده کرده و به بردار تبدیل میکنند.
۴. آموزش مدل با هدف یادگیری متریک
در این مرحله، به مدل مثالهایی از آیتمهای «مشابه» و «متفاوت» نشان میدهیم. ما مدل را طوری آموزش میدهیم که آیتمهای مشابه را در فضای برداری به هم نزدیک کند و آیتمهای متفاوت را از هم دور کند. به این فرآیند، یادگیری متریک (Metric Learning) گفته میشود.
۵. نمونهبرداری منفی و دستهبندی
ما به مدل مثالهای چالشبرانگیز میدهیم. اینها آیتمهایی هستند که ظاهرا شبیه به هم هستند اما در واقعیت نیستند. این کار به مدل کمک میکند تا تفاوتهای ظریف را بهتر تشخیص دهد.
۶. اعتبارسنجی و تنظیم (Validate and Tune)
در این مرحله باید بررسی کنیم که تعبیه سازی (Embedding) های ما چقدر خوب کار میکنند. این کار با آزمایش موارد زیر انجام میشود:
- دقت نتایج جستجو چقدر است.
- آیتمها چقدر خوب در دستهبندیهای صحیح خود قرار میگیرند.
- خوشهبندی (Clustering) خودکار چقدر خوب انجام میشود.
اگر نتایج خوب نبودند، مواردی مانند اندازه بردار، روش آموزش یا دادهها را تغییر میدهیم.
۷. ایندکسگذاری برای بازیابی سریع
ما بردارهای خود را در یک پایگاه داده مخصوص (مانند Qdrant یا FAISS) ذخیره میکنیم. این کار به ما کمک میکند تا بتوانیم حتی از بین میلیونها آیتم، نزدیکترین موارد مشابه را به سرعت پیدا (بازیابی) کنیم.
۸. استفاده از تعبیه سازی (Embedding)
وقتی تعبیه سازی آماده شد، میتوان از آنها برای موارد زیر استفاده کرد:
- جستجوی معنایی (Semantic Search): جستجو بر اساس معنا، نه فقط کلمات دقیق.
- تولید محتوای مبتنی بر بازیابی (RAG): تزریق اطلاعات به مدل هوش مصنوعی (AI) برای تولید پاسخ دقیقتر.
- طبقهبندی (Classification): پیشبینی برچسب یا دسته صحیح.
- خوشهبندی (Clustering): گروهبندی آیتمهای مشابه در کنار هم.
- سیستمهای توصیهگر (Recommendations): پیشنهاد محصولات، محتوا یا کاربران مشابه.
- پایش (Monitoring): تشخیص تغییرات یا الگوهای غیرعادی در طول زمان.
اهمیت تعبیه سازی (Embedding)
تعبیه سازی یا embedding به دلایل مختلفی در حوزهها و وظایف گوناگون استفاده میشود:
- نمایش معنایی (Semantic Representation): تعبیهها روابط معنایی بین موجودیتهای درون داده را درک و ذخیره میکنند. برای مثال، در تعبیه کلمه (Word Embeddings)، کلماتی که معانی مشابهی دارند، در فضای برداری به صورت نقاطی نزدیک به هم قرار میگیرند.
- کاهش ابعاد (Dimensionality Reduction): تعبیهها ابعاد دادهها را کاهش میدهند، در حالی که ویژگیها و روابط مهم را حفظ میکنند.
- یادگیری انتقالی (Transfer Learning): تعبیههایی که برای یک وظیفه یا حوزه خاص آموزش دیدهاند، میتوانند منتقل شده و برای استفاده در وظایف یا حوزههای مرتبط، تنظیم دقیق (Fine-tune) شوند.
- مهندسی ویژگی (Feature Engineering): تعبیهها به طور خودکار ویژگیهای معناداری را از دادههای خام استخراج میکنند، که این موضوع نیاز به مهندسی ویژگی دستی را کاهش میدهد.
- تفسیرپذیری: تعبیهها نمایشهای قابل تفسیری از دادهها ارائه میدهند. برای مثال، در تعبیه کلمه، جهت و فاصله بین بردارهای کلمات میتواند با روابط معناداری مانند جنسیت، زمان فعل یا بار احساسی مطابقت داشته باشد.
چه چیزهایی را میتوان تعبیه (Embed) کرد؟
از دادههای متنی گرفته تا تصاویر و فراتر از آن، تعبیهها یک رویکرد همهکاره برای کدگذاری اطلاعات در قالب بردارهای متراکم ارائه میده دهند.
برخی از انواع اصلی دادهها یا مقادیری که میتوان آنها را تعبیه کرد عبارتند از:
۱. کلمات (Words)
تعبیه کلمه (Word Embeddings) بردارهای عددی هستند که کلمات را در یک فضای پیوسته نمایش میدهند، جایی که کلمات مشابه در نزدیکی یکدیگر قرار میگیرند. این بردارها از مجموعه دادههای متنی بزرگ آموخته میشوند و معانی و روابط بین کلمات را در خود ذخیره میکنند. این ویژگی، درک و پردازش زبان را برای کامپیوترها در وظایفی مانند تحلیل احساسات (Sentiment Analysis) و ترجمه آسانتر میکند.
برخی از مدلهای محبوب تعبیه کلمات (Word Embeddings) عبارتند از:
- Word2Vec
- GloVe (Global Vectors for Word Representation)
- FastText
- BERT (Bidirectional Encoder Representations from Transformers)
- GPT
۲. اسناد متنی کامل (Complete Text Document)
تعبیه متن (Text Embeddings) یا تعبیه سند (Document Embeddings)، کل جملات، پاراگرافها یا اسناد را به صورت بردارهای عددی در یک فضای پیوسته نشان میدهند. برخلاف تعبیه کلمه که بر کلمات تکی تمرکز دارد، تعبیه متن معنا و مفهوم (Context) بخشهای طولانیتری از متن را درک میکند. این قابلیت، مقایسه و تحلیل بخشهای کامل متن را در وظایف پردازش زبان طبیعی (NLP) مانند تحلیل احساسات، ترجمه یا طبقهبندی اسناد (Document Classification) آسانتر میکند.
برخی از مدلهای محبوب تعبیه متن عبارتند از:
- Doc2Vec
- Universal Sentence Encoder (USE)
- BERT
- ELMO
۳. دادههای صوتی (Audio Data)
دادههای صوتی شامل نمونههای صدای تکی، کلیپهای صوتی و فایلهای صوتی ضبط شده کامل هستند. با نمایش دادن صدا به صورت بردارهای متراکم در یک فضای برداری پیوسته، تکنیکهای تعبیه به طور موثری ویژگیها و روابط آکوستیک (Acoustic) را درک میکنند. این قابلیت، طیف گستردهای از وظایف پردازش صدا مانند تشخیص گفتار (Speech Recognition)، شناسایی گوینده، تشخیص احساسات و طبقهبندی ژانر موسیقی را امکانپذیر میسازد.
از جمله تکنیکهای محبوب تعبیه صدا میتوان به Wav2Vec اشاره کرد.
۴. دادههای تصویری (Image Data)
تعبیه تصویر (Image Embeddings) نمایشهای عددی از تصاویر در یک فضای برداری پیوسته هستند. این تعبیهها معمولاً از طریق پردازش تصاویر توسط شبکههای عصبی پیچشی (CNNs) استخراج میشوند. این تعبیهها محتوای بصری، ویژگیها و معنای (Semantics) تصاویر را کدگذاری میکنند و درک و پردازش کارآمد اطلاعات بصری را برای ماشینها آسان میسازند.
برخی از تکنیکهای محبوب تعبیه تصویر مبتنی بر CNN عبارتند از:
- VGG
- ResNet
- Inception
- EfficientNet
۵. دادههای گراف (Graph Data)
تعبیه گراف (Graph Embeddings) گرهها (Nodes) و یالهای (Edges) یک گراف را به بردارهای عددی تبدیل میکند، به طوری که ساختار و روابط درون گراف را به خوبی ذخیره کند. این نوع نمایش داده، استفاده از دادههای پیچیده گراف را برای مدلهای یادگیری ماشین آسانتر کرده و انجام وظایفی مانند طبقهبندی گرهها (Node Classification)، پیشبینی لینک (Link Prediction) و خوشهبندی (Clustering) را ممکن میسازد.
برخی از تکنیکهای محبوب تعبیه گراف عبارتند از:
- Node2Vec
- DeepWalk
- شبکههای عصبی گرافی (Graph Convolutional Networks)
۶. دادههای ساختاریافته (Structured Data)
دادههای ساختاریافته، مانند بردارهای ویژگی (Feature Vectors) و جداول، نیز میتوانند تعبیه شوند تا به مدلهای یادگیری ماشین در درک الگوهای پنهان کمک کنند. از تکنیکهای رایج برای این کار میتوان به خودرمزگذارها (Autoencoders) اشاره کرد.
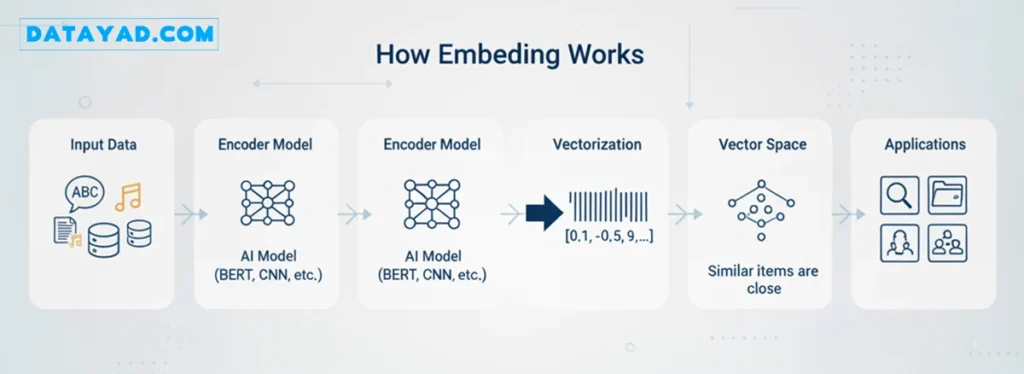
مصورسازی تعبیه کلمه (Word Embeddings) با استفاده از t-SNE
مصورسازی تعبیه کلمه میتواند بینش خوبی در مورد نحوه قرارگیری کلمات نسبت به یکدیگر در دادههایی با ابعاد زیاد (High-dimensional) ارائه دهد. در این کد، ما نشان میدهیم که چگونه تعبیههای کلمه را با استفاده از t-SNE (که یک تکنیک کاهش ابعاد است) مصورسازی کنیم. این کار پس از آموزش یک مدل Word2Vec بر روی مجموعه داده ‘text8’ انجام میشود.
گام ۱: فراخوانی کتابخانهها
NumPy: برای کار با دادههای عددی و آرایهها.
Matplotlib: برای ایجاد نمودارها و مصورسازی.
scikit-learn (sklearn): برای کاهش ابعاد بردارها به دو بُعد جهت مصورسازی آسان.
Gensim: برای دانلود مجموعه دادههای متنی و آموزش مدلهای تعبیه کلمه.
import numpy as np
import matplotlib.pyplot as plt
import gensim.downloader as api
from sklearn.manifold import TSNE
from gensim.models import Word2Ve
گام ۲: بارگیری دادهها و آموزش مدل Word2Vec
در این مرحله، یک مجموعه داده متنی نمونه بارگیری شده و از آن برای آموزش مدل Word2Vec (که بردارهای کلمات را میسازد) استفاده میشود.
text_data = api.load(‘text8’)
w2v_model = Word2Vec(text_data)
گام ۳: انتخاب کلمات و استخراج تعبیههای آنها
یک لیست از کلمات نمونه انتخاب شده و بردارهای (تعبیههای) مربوط به آنها از مدل استخراج میشوند.
selected_words = ['cat', 'dog', 'elephant', 'lion', 'bird', 'rat', 'wolf', 'cow', 'goat', 'snake', 'rabbit', 'human', 'parrot', 'fox', 'peacock', 'lotus', 'roses', 'marigold', 'jasmine', 'computer', 'robot', 'software', 'vocabulary', 'machine', 'eye', 'vision', 'grammar', 'words', 'sentences', 'language', 'verbs', 'noun', 'transformer', 'embedding', 'neural', 'network', 'optimization'] existing_words = [word for word in selected_words if word in w2v_model.wv.key_to_index]vector_list = [w2v_model.wv[word] for word in existing_words]embedding_matrix = np.array(vector_list)
گام ۴: کاهش ابعاد با t-SNE
از t-SNE برای فشردهسازی و کاهش ابعاد بردارهای با ابعاد زیاد به دو بُعد (برای مصورسازی) استفاده میکنیم.
tsne_reducer = TSNE(n_components=2, perplexity=5, random_state=42, init=’pca’, learning_rate=200)
reduced_vectors = tsne_reducer.fit_transform(embedding_matrix)
گام ۵: رسم نمودار تعبیهها
یک نمودار پراکندگی (Scatter plot) از کلمات در فضای دوبعدی نمایش داده میشود و هر نقطه با کلمه مربوط به خود برچسبگذاری میشود.
x_coords = reduced_vectors[:, 0]
y_coords = reduced_vectors[:, 1]
plt.figure(figsize=(14, 10), dpi=150)
plt.scatter(x_coords, y_coords, marker=’*’, color=’blue’, alpha=0.7)
for i, word in enumerate(existing_words): plt.annotate(word, (x_coords[i], y_coords[i]), fontsize=9, ha=’right’) plt.xlabel(‘t-SNE Dimension 1’)
plt.ylabel(‘t-SNE Dimension 2’) plt.title(‘Word Embedding Graph (t-SNE with Word2Vec)’) plt.grid(True) plt.savefig(‘word_embedding_visualization.png’) plt.show()
خروجی:
شکل بردار تعبیه اصلی: (37, 100) (یعنی 37 کلمه، هر کدام یک بردار 100 بعدی)
شکل بردار تعبیه پس از اعمال t-SNE: (37, 2) (یعنی 37 کلمه، هر کدام یک بردار 2 بعدی برای نمایش روی نمودار)
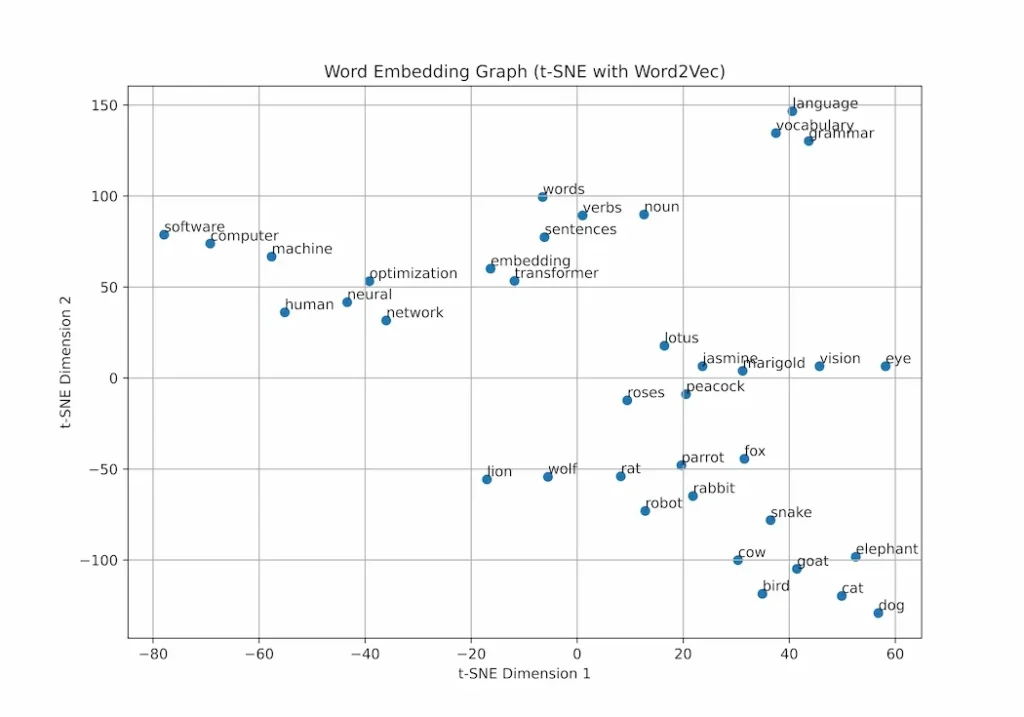
همانطور که میبینیم، کلماتی مانند «مار»، «گاو»، «پرندگان» و غیره، همگی در نزدیکی هم خوشهبندی شدهاند. این نزدیکی، شباهت معنایی آنها را نشان میدهد (چون همگی حیوان هستند).
در مقابل، کلماتی مانند «کامپیوتر» و «ماشین» از خوشه حیوانات فاصله زیادی دارند، که این فاصله عدم شباهت (یا تفاوت معنایی) آنها را به خوبی نشان میدهد.




















