

تشخیص اشیا (Object Detection) به عنوان یک ستون محوری در قلمرو بینایی کامپیوتر (Computer Vision) و پردازش تصویر (Image Processing) ، فرآیندی است که ماشینها را قادر میسازد تا اشیا موجود در دادههای بصری (تصاویر و ویدئوها) را شناسایی کرده و موقعیت دقیق فضایی آنها را تعیین کنند. امروزه، این تکنیک تقریباً به طور کامل بر پایه روشهای قدرتمند یادگیری عمیق (Deep Learning)، به ویژه شبکههای عصبی کانولوشنی (CNN)، بنا شده است. این قابلیت پیشرفته، تأثیر خود را در کاربردهای متعددی نظیر سیستمهای خودروهای خودران (Autonomous Vehicles)، نظارت و امنیت هوشمند، تحلیل تصاویر پزشکی، و بهینهسازی فرآیندهای تولید صنعتی به وضوح نشان داده است.
در اصل، وظیفه تشخیص اشیاء شامل دو بخش است: طبقه بندی نوع شی (Classification) و مکانیابی (Object Localization). این موضوع، تفاوت اصلی آن با طبقه بندی تصویر است. طبقه بندی تصویر (Image Classification) تنها یک برچسب کلی به کل تصویر میدهد، اما سیستم تشخیص اشیاء همزمان مشخص میکند که هر شی در کجا قرار دارد و با رسم یک جعبه مرزی (Bounding Box) مکان دقیق آن را تعیین میکند.
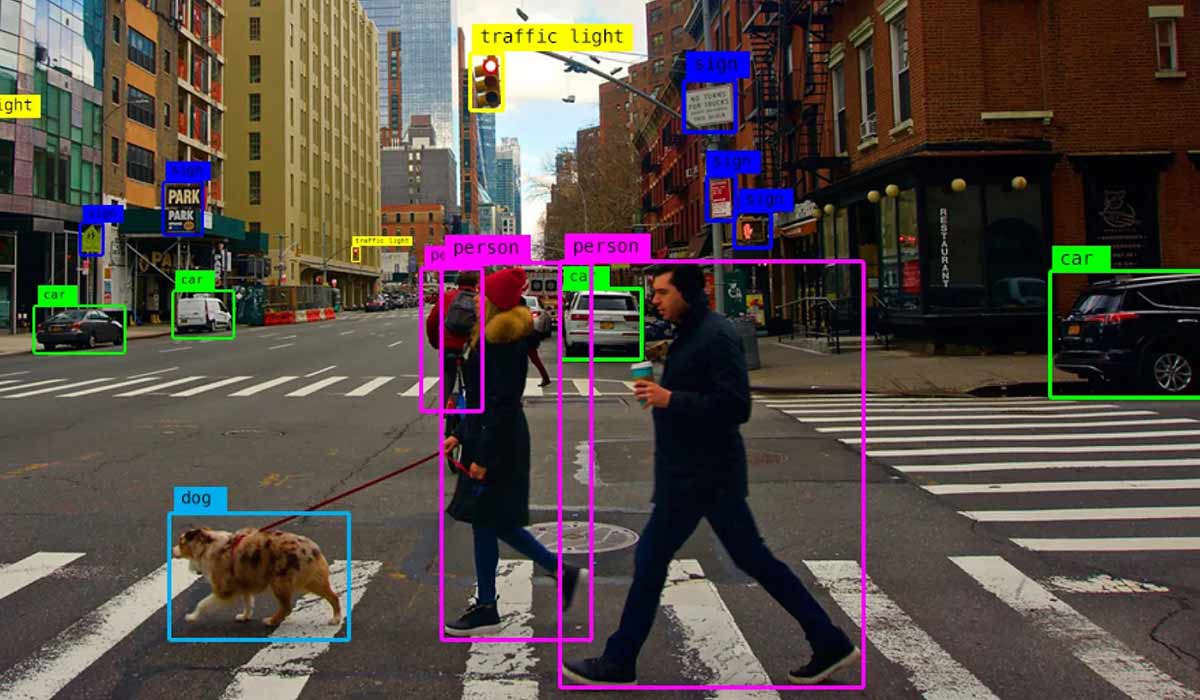
تشخیص اشیا (Object Detection) چیست؟
تشخیص اشیاء (Object Detection) یک ستون کلیدی در حوزه بینایی کامپیوتر (Computer Vision) و پردازش تصویر محسوب میشود. این فناوری پیشرفته، ماشینها را قادر میسازد تا اشیا موجود در تصاویر و ویدئوها را شناسایی کرده و موقعیت دقیق آنها را در کادر مشخص کنند. در عصر حاضر، قدرت این تکنیک تقریباً به طور کامل بر پایه روشهای پیشرفته یادگیری عمیق (Deep Learning)، به ویژه شبکههای عصبی کانولوشنی (CNN)، بنا شده است.
Object Detection را میتوان به عنوان مغز متفکر سامانههای هوشمندی در نظر گرفت که نیاز به درک بصری پیچیده دارند. قابلیتهای این فناوری در کاربردهای تحولآفرینی چون خودروهای خودران (Autonomous Vehicles)، نظارت و امنیت هوشمند، تحلیل تصاویر پزشکی، و بهینهسازی فرآیندهای تولید صنعتی، کاملاً مشهود است و این حوزه را به یکی از داغترین مباحث در هوش مصنوعی تبدیل کرده است.
تشخیص اشیا در مقابل طبقه بندی تصویر و مکانیابی
وظیفه تشخیص اشیا (Object Detection) اغلب با سایر تکنیکهای کلیدی بینایی کامپیوتر (Computer Vision) اشتباه گرفته میشود. در واقع، Object Detection ترکیبی از دو وظیفه مستقل است: طبقه بندی شی و مکانیابی شی (Object Localization). درک تفاوتهای این سه مفهوم، برای توسعه مدلهای هوش مصنوعی ضروری است:
| وظیفه اصلی | هدف | خروجی |
| ۱. طبقه بندی تصویر (Image Classification) | تعیین اینکه چه نوع شیئی در کل تصویر وجود دارد. |
یک برچسب (Label) کلی برای تمام تصویر. (مثال: تصویر یک سگ است.)
|
| ۲. مکانیابی شیء (Object Localization) | تعیین مکان دقیق یک شیء واحد در تصویر. |
یک جعبه مرزی (Bounding Box) برای شیء مورد نظر.
|
| ۳. تشخیص اشیاء (Object Detection) | شناسایی و مکانیابی همزمان تمام اشیاء موجود در تصویر. |
چندین جعبه مرزی و برچسب برای هر شیء بهصورت جداگانه.
|
چرا این تفاوت اهمیت دارد؟
تشخیص اشیا عملاً دو وظیفه طبقه بندی و مکانیابی را در یک شبکه عصبی ترکیب میکند. این فرآیند به سیستمهای هوشمند اجازه میدهد که در یک صحنه شلوغ (مثلاً یک خیابان)، نه تنها وجود انسانها یا خودروها را تأیید کنند (مانند طبقه بندی)، بلکه موقعیت دقیق، اندازه و فاصله هر کدام را نیز مشخص کنند. این قابلیت پیشرفته، نقش محوری جعبه مرزی را به عنوان قلب تشخیص اشیاء تثبیت میکند و آن را برای کاربردهایی نظیر خودروهای خودران که به دادههای مکانی لحظهای نیاز دارند، حیاتی میسازد.
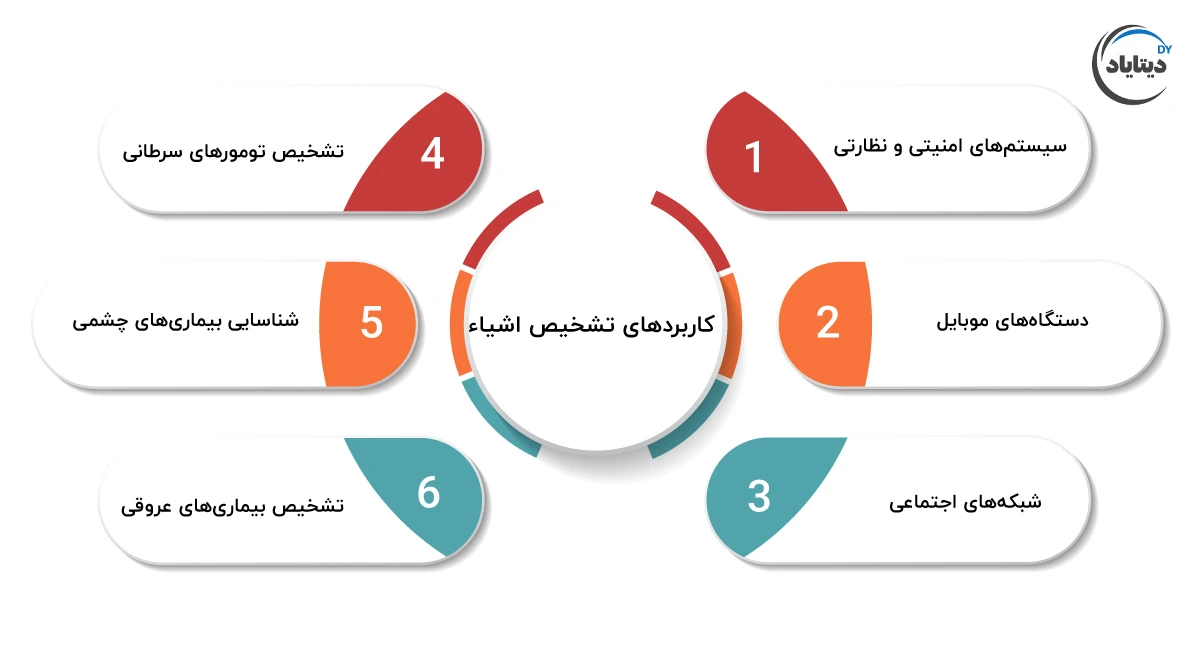
کاربردهای عملی تشخیص اشیا
قابلیت تشخیص اشیا برای درک محیط اطراف، این فناوری را به یکی از مهمترین ابزارهای تحول دیجیتال تبدیل کرده است. کاربردهای این حوزه فراتر از آزمایشگاهها رفته و به بخشهای حیاتی اقتصاد وارد شده است.
خودروهای خودران و حملونقل هوشمند
تشخیص اشیا قلب تپنده سیستمهای خودروهای خودران (Autonomous Vehicles) است. مدلهای Deep Learning به صورت لحظهای وظیفه شناسایی و مکانیابی دقیق عابران پیاده، خودروهای دیگر، چراغهای راهنمایی و علائم جادهای را بر عهده دارند. این فرآیند حیاتی، پایه و اساس تصمیمگیریهای ایمن و جلوگیری از تصادفات است.
امنیت و نظارت هوشمند
در سیستمهای امنیتی، Object Detection جایگزین نظارت انسانی شده است. این فناوری میتواند اشیاء یا رفتارهای مشکوک (مانند جاماندن یک بسته یا تجمع افراد) را بهصورت Real-Time شناسایی کرده و هشدار دهد. در حوزهی کنترل دسترسی، امکان تشخیص چهره یا اشیای ممنوعه نیز فراهم میشود.
پزشکی و سلامت
در حوزه پردازش تصاویر پزشکی، تشخیص اشیاء نقشی نجاتدهنده دارد. از آن برای مکانیابی و شناسایی ناهنجاریها، تومورها، یا سلولهای خاص در تصاویر رادیولوژی (مانند MRI و CT Scan) استفاده میشود. این قابلیت به پزشکان کمک میکند تا با دقت و سرعت بالاتری تشخیصگذاری کنند.
تولید صنعتی و کنترل کیفیت
در خطوط تولید کارخانجات، مدلهای تشخیص اشیا برای کنترل کیفیت خودکار به کار میروند. این سیستمها میتوانند نقصهای کوچک، قطعات معیوب یا جایگذاری نادرست قطعات را شناسایی کرده و راندمان تولید را به شکل چشمگیری افزایش دهند.
خردهفروشی و مدیریت فروشگاه
در بخش خردهفروشی (Retail)، این فناوری برای بهینهسازی تجربه مشتری و مدیریت موجودی استفاده میشود. تشخیص اشیا میتواند بهطور خودکار:
- تعداد مشتریان و مسیر حرکت آنها در فروشگاه را تحلیل کند.
- خروج کالا بدون پرداخت یا اجناس نامناسب را از روی قفسهها شناسایی کند.
- فناوری فروشگاههای بدون صندوق (مانند آمازون گو) را از طریق تشخیص دقیق اقلامی که مشتری برمیدارد یا برمیگرداند، ممکن سازد.
تجربه کاربری و واقعیت افزوده (AR)
در حوزه واقعیت افزوده (Augmented Reality – AR)، Object Detection امکان تشخیص اجسام فیزیکی (مانند یک محصول) را میدهد تا اطلاعات دیجیتالی یا تجربیات تعاملی بر روی آن نمایش داده شوند.

جعبه مرزی (Bounding Box): مفهوم و نقش آن در مکانیابی
جعبه مرزی (Bounding Box)، در واقع قلب تپندهی فرآیند مکانیابی (Object Localization) در تشخیص اشیاء است. این جعبه یک مستطیل فرضی است که اطراف هر شی شناساییشده در تصویر کشیده میشود و چهار مختصات اصلی شیء را مشخص میکند.
اهمیت Bounding Box در عملکرد مدل
بدون این جعبهها، مدلهای Deep Learning تنها میتوانند بگویند شیء در تصویر هست، اما نمیتوانند به ما بگویند کجای تصویر قرار دارد. کارکرد اصلی جعبه مرزی را میتوان در سه جنبه خلاصه کرد:
- مکانیابی دقیق: جعبه مرزی مکان دقیق شیء را با ارائه مختصات (مانند ) به سیستم میدهد.
- تفکیک اشیاء متراکم: در صحنههای شلوغ، Bounding Box به مدل کمک میکند تا اشیاء همپوشان را از یکدیگر تفکیک و برای هر کدام یک برچسب مجزا و دقیق صادر کند.
- معیار ارزیابی (IoU): جعبههای مرزی پایه و اساس معیار کلیدی Intersection over Union (IoU) هستند. IoU میزان همپوشانی جعبه پیشبینیشده توسط مدل با جعبه واقعی (Ground Truth) در دادههای آموزشی را اندازه میگیرد و معیاری حیاتی برای سنجش دقت مدل است.
در فرآیند آموزش، جعبههای مرزی توسط انسانها در دیتاستها برچسبگذاری میشوند و سپس مدل یاد میگیرد که این مختصات را در تصاویر جدید پیشبینی کند. دقت این پیشبینیها مستقیماً بر کیفیت نهایی مدل تشخیص اشیاء تأثیر میگذارد.
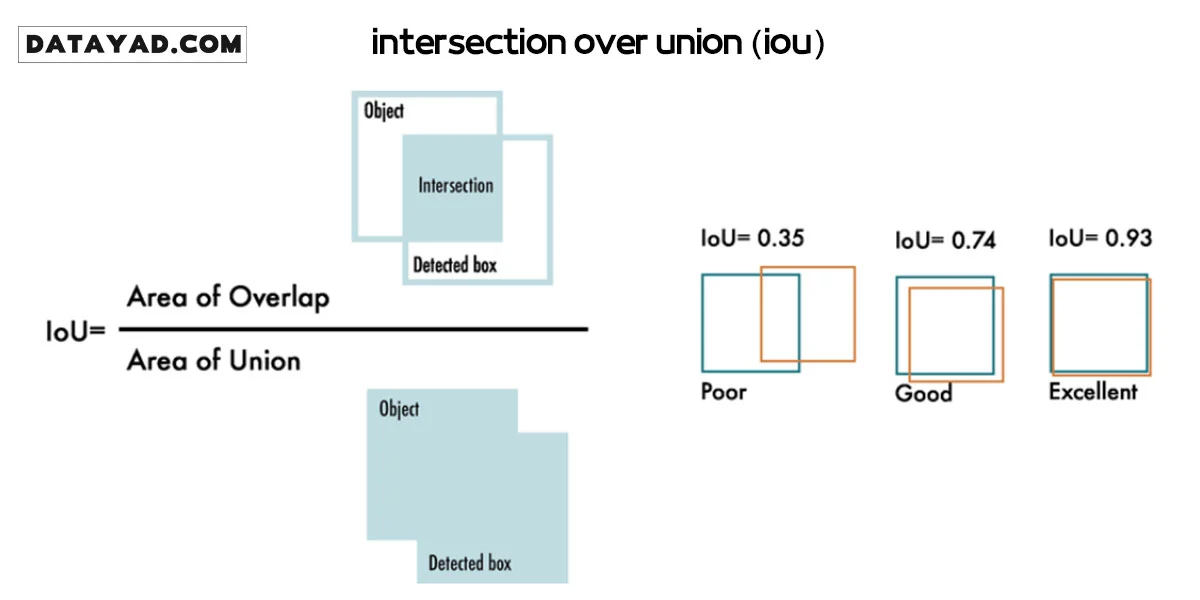
چالش های تخصصی در Object Detection و راهحلهای Deep Learning
با وجود پیشرفتهای چشمگیر، تشخیص اشیا همچنان با چالشهای فنی مهمی روبرو است که میتواند دقت و عملکرد مدلها را در محیطهای واقعی تحت تأثیر قرار دهد. مقابله موفق با این موانع، نیازمند استفاده از تکنیکهای پیشرفته یادگیری عمیق است.
تشخیص اشیا با مقیاسهای مختلف (Scale Variation)
یکی از رایجترین مشکلات، حضور همزمان اشیاء بسیار کوچک و بسیار بزرگ در یک تصویر است. مدلهای سنتی CNN اغلب در تشخیص اشیاء کوچک دچار مشکل میشوند، زیرا ویژگیهای آنها در لایههای عمیقتر شبکه از بین میرود.
راهحل یادگیری عمیق (Deep Learning): استفاده از شبکههای هرمی ویژگی (Feature Pyramid Networks – FPN). معماری FPN به مدل اجازه میدهد تا ویژگیها را از لایههای مختلف شبکه در مقیاسهای گوناگون استخراج کند. این رویکرد، دقت مکانیابی اشیاء کوچک را با بهرهگیری از ویژگیهای با وضوح بالا در لایههای کمعمق، به شدت افزایش میدهد.
مشکل تراکم و همپوشانی (Occlusion and Clutter)
در تصاویر شلوغ و پرتراکم (مانند یک پارکینگ پر از خودرو)، چندین شیء در یک کادر دیده میشوند یا یکدیگر را میپوشانند (همپوشانی). این وضعیت، وظیفه تفکیک جعبههای مرزی مجزا را برای مدل دشوار میسازد.
- راهحل فنی: استفاده از الگوریتمهای پسپردازش پیشرفته مانند حذف غیرحداکثری نرم (Soft Non-Maximum Suppression – Soft-NMS). در حالی که NMS استاندارد، جعبههای همپوشان با اطمینان پایین را بهطور کامل حذف میکند، Soft-NMS به جای حذف کامل، امتیاز (Score) آنها را کاهش میدهد و احتمال از دست رفتن اشیا بهدرستی شناساییشده را پایین میآورد.
عدم تعادل دادهها (Data Imbalance)
در بسیاری از دیتاستها، تعداد مناطق پسزمینه (Background) یا کلاسهای پرتعداد، به مراتب بیشتر از اشیاء هدف (Foreground) یا کلاسهای کمیاب است. این عدم تعادل شدید باعث میشود مدل به سمت پیشبینی کلاسهای غالب سوگیری پیدا کند.
- راهحل تخصصی: پیادهسازی تابع زیان محوری (Focal Loss). Focal Loss یک نوع تابع زیان وزنی است که به طور فعال به نمونههای سخت (Hard Examples) یا کلاسهای نادر وزن بیشتری اختصاص میدهد. این کار، اثرات منفی نمونههای آسان (Easy Negatives) را کاهش داده و تمرکز مدل بر یادگیری اشیا چالشبرانگیزتر را افزایش میدهد.
انتخاب دیتاست مناسب؛ معرفی COCO، Pascal VOC و…
کیفیت و حجم دیتاست مورد استفاده، مهمترین عامل تعیینکننده دقت و عملکرد مدل تشخیص اشیاء است. مدلهای دیپ لرنینگ تنها به اندازه دادههایی که با آنها آموزش میبینند، هوشمند هستند. انتخاب دیتاست باید بر اساس هدف پروژه و منابع محاسباتی در دسترس صورت گیرد.
معیارهای انتخاب دیتاست برای تشخیص اشیا (Object Detection)
هنگام انتخاب دادهها، توجه به موارد زیر ضروری است:
- کیفیت برچسبگذاری (Annotation Quality): دقت جعبههای مرزی (Bounding Box) و برچسبها (Labels) باید در بالاترین سطح باشد. دادههای ضعیف، حتی قویترین مدلها را هم دچار مشکل میکنند.
- تنوع داده (Diversity): تصاویر باید شامل زوایا، نورپردازیها و پسزمینههای متنوع باشند تا از بیشبرازش (Overfitting) جلوگیری شود و مدل در محیطهای واقعی عملکرد خوبی داشته باشد.
- تعداد کلاسها و حجم: دیتاست باید تعداد کافی از کلاسهای مورد نیاز پروژه را داشته باشد و حجم آن (تعداد تصاویر) متناسب با پیچیدگی مدل انتخابی شما باشد.
بررسی مهمترین دیتاستهای استاندارد
جامعه بینایی کامپیوتر به صورت جهانی از چند دیتاست استاندارد برای آموزش و مقایسه مدلها استفاده میکند که عبارتند از:
انتخاب یکی از این دیتاستهای استاندارد یا گردآوری یک دیتاست سفارشی با رعایت این معیارها، اولین گام عملی برای دستیابی به دقت بالاست.
مقایسه روشهای تشخیص اشیا (تکنیکهای One-Stage و Two-Stage)
با اینکه مدلهای تشخیص اشیاء بسیاری توسعه یافتهاند، اما همه آنها در دو خانواده معماری اصلی دستهبندی میشوند: مدلهای دو مرحلهای (Two-Stage) که بر دقت تأکید دارند و مدلهای یک مرحلهای (One-Stage) که بر سرعت متمرکز هستند.
۱. مدلهای دو مرحلهای (Two-Stage Detectors): دقت در اولویت
این مدلها فرآیند تشخیص را در دو گام مجزا انجام میدهند، که منجر به دقت بالاتر (بهویژه در اشیاء کوچک) اما سرعت پایینتر میشود:
- مرحله اول (Region Proposal): شبکه عصبی ابتدا مناطق احتمالی حضور شیء را در تصویر (Region Proposals) شناسایی میکند. مدلهای پیشرفتهتر مانند Faster R-CNN از یک شبکه عصبی اختصاصی به نام RPN (Region Proposal Network) برای تولید این پیشنهادات بهره میبرند.
- مرحله دوم (Classification & Refinement): برای هر منطقه پیشنهادی، طبقهبندی انجام شده و جعبه مرزی با دقت بیشتری مکانیابی و اصلاح میشود.
نمونههای کلیدی: مدلهای خانواده R-CNN (شامل R-CNN، Fast R-CNN، و Faster R-CNN)
۲. مدلهای یک مرحلهای (One-Stage Detectors): سرعت بالا و Real-Time
این مدلها با هدف تشخیص بلادرنگ (Real-Time Detection) طراحی شدهاند. آنها کل فرآیند (پیشنهاد منطقه، طبقهبندی و مکانیابی) را در یک مرحله و با یک شبکه عصبی انجام میدهند.
- مزیت کلیدی: سرعت بسیار بالا در پردازش فریمها در هر ثانیه (FPS).
- نقطه ضعف: بهطور سنتی در تصاویر بسیار شلوغ یا اشیاء بسیار کوچک، دقت (mAP) کمتری نسبت به مدلهای Two-Stage داشتند (گرچه نسخههای جدید YOLO این اختلاف را به حداقل رساندهاند).
نمونههای کلیدی: YOLO (You Only Look Once) و SSD (Single Shot MultiBox Detector)
جدول مقایسه عملکردی مدلهای کلیدی Object Detection
جدول زیر، تفاوتهای عملکردی دو نماینده اصلی این خانوادهها را نشان میدهد و به شما در انتخاب مدل برای پروژههای عملی کمک میکند:
پروژه عملی: پیادهسازی تشخیص اشیا با پایتون (گامبهگام)
تبدیل دانش نظری به مهارت عملی، نیازمند شروع یک پروژه واقعی است. در حال حاضر، مدلهای One-Stage نظیر YOLO به دلیل سرعت بالا، سادگی نصب و اکوسیستم غنی، بهترین گزینه برای شروع پروژههای تشخیص اشیا هستند. در اینجا یک نقشه راه گامبهگام برای پیادهسازی اولیه با پایتون و فریمورکهای مرسوم آورده شده است:
گام ۱: آمادهسازی محیط و نصب پیشنیازها
شروع هر پروژه Deep Learning با نصب کتابخانههای کلیدی آغاز میشود. اما قبل از نصب، لازم است مهارت کافی برای آمادهسازی و تحلیل داده با پایتون را داشته باشید تا بتوانید کیفیت دیتاست را ارزیابی و آن را برای آموزش مدل بهینهسازی کنید. پس از آن باید کتابخانههای کلیدی شامل YOLOv8 (از طریق بسته ultralytics) و OpenCV برای پردازش تصویر را نصب کنید:
pip install ultralytics opencv-pythonگام ۲: انتخاب و بارگذاری مدل از پیشآموزشدیده
بهترین راه، استفاده از مدلهای سبک و از پیشآموزشدیده (Pre-trained) بر روی دیتاست COCO است که امکان Transfer Learning را فراهم میکند.
from ultralytics import YOLO
# بارگذاری مدل سبک YOLOv8n (n: nano)
model = YOLO('yolov8n.pt')گام ۳: تشخیص و ترسیم خروجی (Inference)
با استفاده از تابع predict مدل، میتوانید تشخیص اشیا را تنها با یک خط کد بر روی تصویر یا ویدئو اعمال کرده و نتایج (شامل جعبههای مرزی و طبقه بندی) را بهصورت گرافیکی دریافت کنید:
import cv2
# تشخیص اشیاء بر روی یک فایل تصویری
results = model.predict('path/to/your/image.jpg', conf=0.25)
# نمایش خروجی با جعبههای مرزی و ذخیره آن
for r in results:
im_array = r.plot() # r.plot() جعبهها را روی تصویر ترسیم میکند
cv2.imwrite('output_image.jpg', im_array)گام ۴: آموزش سفارشی (Fine-Tuning)
اگرچه استفاده از مدلهای از پیش آموزش دیده کافی است، برای دقت بیشتر در یک دامنه خاص، باید مدل را با یک دیتاست کوچک سفارشی آموزش (Fine-Tuning) دهید:
# آموزش مدل بر روی دیتاست سفارشی (مثلاً در فرمت YAML)
results = model.train(data='custom_data.yaml', epochs=100, imgsz=640)
تبدیل دانش به مهارت پروژه محور
اگر به یادگیری تشخیص اشیا و تبدیل این دانش به مهارتهای عملی علاقهمند هستید، دو مسیر اصلی پیش روی شماست که میتوانید انتخاب کنید:
🔹 برای تسلط مستقیم بر پروژههای Real-Time و سریع بازار کار، آموزش YOLO بهترین گزینه است.
🔸 و اگر به دنبال یادگیری عمیقتر مفاهیم پایه، از پردازش تصویر تا یادگیری عمیق هستید، دوره بینایی کامپیوتر را به شما پیشنهاد میکنیم.
جمعبندی و آینده تشخیص اشیا (Object Detection)
تشخیص اشیاء (Object Detection) به عنوان یکی از مهمترین و پویاترین حوزهها در بینایی کامپیوتر، مسیر تحولی چشمگیری را طی کرده است. از مدلهای کند و پیچیدهی اولیهی R-CNN تا معماریهای Real-Time و فوق سریع امروزی مانند YOLOv8، این فناوری ثابت کرده که ستون فقرات سامانههای هوشمند مدرن است.
در این مقاله، ما آموختیم که Object Detection چگونه با ترکیب موفقیتآمیز طبقهبندی و مکانیابی دقیق (با استفاده از جعبه مرزی)، خود را از سایر تکنیکهای پردازش تصویر متمایز میکند. همچنین دیدیم که چالشهای پیچیدهای مانند تغییر مقیاس و عدم تعادل دادهها با استفاده از راهحلهای تخصصی Deep Learning نظیر FPN و Focal Loss حل میشوند.
مسیر آینده Object Detection
آینده این حوزه در مسیری روشن و هیجانانگیز قرار دارد:
- دقت فراتر از جعبه مرزی: تمرکز از جعبههای مرزی ساده به سمت روشهای دقیقتر مانند بخشبندی نمونه (Instance Segmentation) حرکت میکند که بهجای مستطیل، مرزهای پیکسلی شیء را مشخص میکند.
- مدلهای سبُکتر و سریعتر: نیاز روزافزون به پیادهسازی تشخیص اشیاء بر روی دستگاههای کوچک (مانند تلفنهای همراه و سختافزارهای کممصرف) باعث ظهور مدلهای بسیار بهینهشده و کمحجمتر میشود.
- درک سهبُعدی: در کاربردهایی مانند خودروهای خودران (Autonomous Vehicles)، مدلهای تشخیص اشیاء بهسرعت در حال ادغام با دادههای سهبُعدی (مانند Lidar) هستند تا نه تنها موقعیت، بلکه عمق و فاصله دقیق اشیاء نیز تعیین شود.
در نهایت، با توجه به این پیشرفتها، Object Detection در سالهای آتی نقشی بسیار پررنگتر و حیاتیتر در هوشمندسازی زندگی روزمره، از امنیت تا پزشکی و صنعت، ایفا خواهد کرد.




















