

در دنیای امروز، ما در اقیانوسی از دادهها غرق شدهایم. اما بخش بزرگی از این دادهها، دادههای متنی بدون ساختار (Unstructured Text) هستند، مانند نظرات مشتریان، پستهای رسانههای اجتماعی، ایمیلها و مقالات. این حجم عظیم از متن، گنجینهای پنهان از اطلاعات ارزشمند است، اما استخراج این اطلاعات به صورت دستی غیرممکن است. اینجا، متن کاوی (Text Mining) اهمیت پیدا میکند.
متن کاوی (Text Mining)، که گاهی داده کاوی متن (text data mining) نیز نامیده میشود، فرآیند تبدیل این متون آشفته و بدون ساختار به بینشهای قابل فهم و ساختاریافته است. این فرآیند به کسبوکارها کمک میکند تا الگوهای پنهان، روندها و نظرات مشتریان را کشف کنند. در این مقاله، ما به صورت عمیق بررسی میکنیم که متن کاوی چیست، چه تفاوتی با تحلیل متن دارد، از چه تکنیکهایی استفاده میکند و چه کاربردهای شگفتانگیزی در دنیای واقعی دارد.
متن کاوی چیست؟
متن کاوی (Text Mining)، فرآیند تبدیل متن بدون ساختار (Unstructured Text) به یک فرمت ساختاریافته (Structured Data) است تا بتوان الگوهای معنادار و بینشهای جدید را شناسایی کرد. شما میتوانید از متن کاوی برای تجزیه و تحلیل مجموعههای عظیمی از متون استفاده کنید تا مفاهیم کلیدی، روندها و روابط پنهان را کشف نمایید.
شرکتها با بهکارگیری الگوریتم هایی مانند Naive Bayes یا SVM و یا الگوریتمهای یادگیری عمیق، قادر به کاوش و کشف روابط پنهان در دادههای بدون ساختار خود هستند.
متن یکی از رایجترین انواع داده در پایگاههای داده است. بسته به نوع پایگاه داده (Database)، این دادهها میتوانند به شکلهای زیر سازماندهی شوند:
- دادههای ساختاریافته (Structured data): این دادهها در یک قالب جدولی استاندارد با سطرها و ستونهای متعدد سازماندهی میشوند، که ذخیرهسازی و پردازش آنها را برای تجزیه و تحلیل الگوریتمهای یادگیری ماشین آسانتر میکند. دادههای ساختاریافته میتوانند شامل ورودیهایی مانند نامها، آدرسها و شماره تلفنها باشند.
- دادههای بدون ساختار (Unstructured data): این دادهها فرمت دادهای از پیش تعریفشدهای ندارند. این دادهها میتوانند شامل متن از منابعی مانند رسانههای اجتماعی یا نظرات کاربران در مورد محصولات، یا فرمتهای رسانهای مانند فایلهای ویدیویی و صوتی باشند.
- دادههای نیمه ساختاریافته (Semi-structured data): همانطور که از نامش پیداست، این دادهها ترکیبی از فرمتهای دادههای ساختاریافته و بدون ساختار هستند. اگرچه این دادهها میزانی از سازماندهی را دارند، اما ساختار کافی برای برآورده کردن الزامات یک پایگاه داده رابطهای (relational database) را ندارند. نمونههایی از دادههای نیمه ساختاریافته شامل فایلهای XML ،JSON و HTML هستند.
از آنجایی که بخش عظیمی از دادههای جهان در فرمتی بدون ساختار قرار دارند، متن کاوی یک اقدام فوقالعاده ارزشمند در سازمانها محسوب میشود. ابزارهای متن کاوی و تکنیکهای پردازش زبان طبیعی (NLP)، مانند استخراج اطلاعات (information extraction)، به ما این امکان را میدهند که اسناد بدون ساختار را به فرمتی ساختاریافته تبدیل کنیم تا امکان تجزیه و تحلیل و تولید بینشهای باکیفیت فراهم شود. این امر به نوبه خود، فرآیند تصمیمگیری در سازمانها را بهبود بخشیده و منجر به نتایج تجاری بهتری میشود.
متن کاوی چه تفاوتی با تحلیل متن دارد؟
شاید فکر کنید متن کاوی (Text Mining) و تحلیل متن (Text Analytics) یک معنی دارند، چون اغلب به جای یکدیگر استفاده میشوند، اما بهتر است یک تفاوت ظریف بین آنها قائل شویم.
بیایید این فرآیند را مرحله به مرحله ببینیم:
۱. کشف الگوها (کار متن کاوی): متن کاوی مانند یک کاوشگر عمل میکند. این کاوشگر با استفاده از ابزارهایی مانند یادگیری ماشین، آمار و زبانشناسی، به عمق دادههای بدون ساختار شما میرود تا الگوها و روندهای پنهان در متن را پیدا کند. وظیفه اصلی آن، تبدیل متنهای نامرتب و پراکنده به دادههای ساختاریافته و قابل فهم است.
۲. رسیدن به نتایج کمی (کار تحلیل متن): پس از اینکه متن کاوی دادهها را مرتب کرد، تحلیل متن (Text Analytics) وارد عمل میشود. تحلیل متن از آن دادههای ساختاریافته استفاده میکند تا بینشهای کمی (یعنی نتایج عددی و قابل اندازهگیری) استخراج کند.
۳. ارائه نتایج: در نهایت، میتوانیم از تکنیکهای مصورسازی داده (مانند نمودارها) استفاده کنیم تا این یافتهها و نتایج را به شکلی ساده و قابل فهم به مخاطبان گستردهتری نشان دهیم.
تکنیکهای متن کاوی
فرآیند متن کاوی شامل چندین فعالیت است که به شما امکان میدهد از دادههای متنی بدون ساختار، اطلاعات مفیدی استخراج کنید.
قبل از اینکه بتوانید تکنیکهای مختلف متن کاوی را به کار ببرید، باید با پیشپردازش متن (text preprocessing) شروع کنید. پیشپردازش متن به معنای پاکسازی و تبدیل دادههای متنی به یک فرمت قابل استفاده است. این کار، بخش اصلی پردازش زبان طبیعی (NLP) محسوب میشود و معمولاً شامل تکنیکهایی مانند تشخیص زبان، توکنسازی (tokenization)، برچسبگذاری اجزای کلام (part-of-speech tagging)، تقطیع (chunking) و تجزیه نحوی (syntax parsing) است تا دادهها به شکل مناسبی برای تجزیه و تحلیل آماده شوند.
هنگامی که پیشپردازش متن کامل شد، میتوانید از الگوریتمهای متن کاوی برای به دست آوردن بینش از دادهها استفاده کنید. برخی از این تکنیکهای رایج متن کاوی عبارتند از:
بازیابی اطلاعات
بازیابی اطلاعات (Information Retrieval یا IR) فرآیندی است که اطلاعات یا اسناد مرتبط را بر اساس مجموعهای از query ها یا عبارات از پیش تعریفشده، پیدا کرده و برمیگرداند.
سیستمهای بازیابی اطلاعات از الگوریتمهایی استفاده میکنند تا رفتار کاربر را ردیابی کرده و دادههای مرتبط را شناسایی کنند. بازیابی اطلاعات به طور گسترده در سیستمهای کاتالوگ کتابخانهها و موتورهای جستجوی محبوبی مانند گوگل استفاده میشود.
برخی از زیرشاخههای رایج در بازیابی اطلاعات عبارتند از:
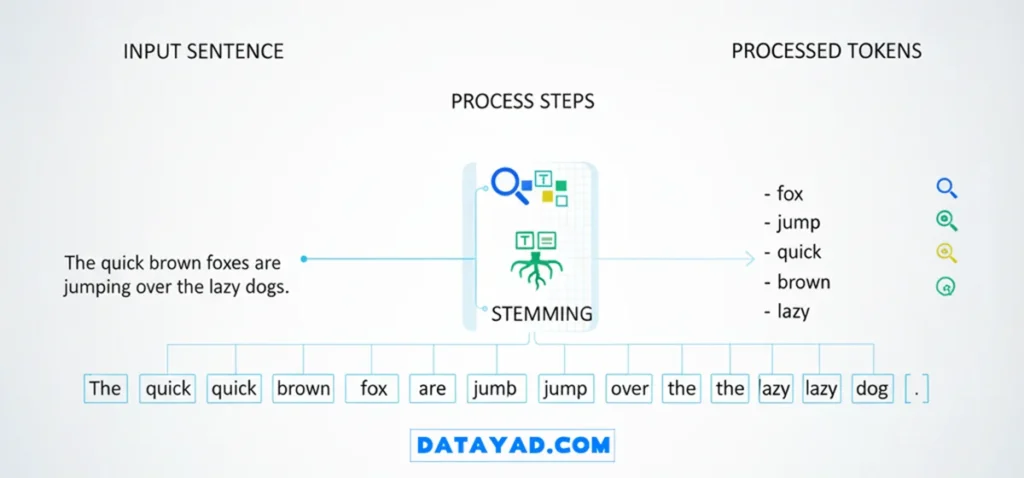
- توکنسازی (Tokenization): این فرآیند به معنای شکستن متنهای طولانی به واحدهای کوچکتری به نام “توکن” (token) است، (این واحدها میتوانند جمله یا کلمه باشند). این توکنها سپس در مدلهایی مانند (bag-of-words) برای کارهایی مثل خوشهبندی متن (text clustering) و تطبیق اسناد استفاده میشوند.
- ریشهیابی کلمات (Stemming): این فرآیند به جداسازی پیشوندها و پسوندها از کلمات اشاره دارد تا به “ریشه کلمه” و معنای اصلی آن دست یابیم. این تکنیک با کاهش دادن حجم تنوع فایلهای ایندکسگذاری شده، به بهبود فرآیند بازیابی اطلاعات کمک میکند.
پردازش زبان طبیعی (NLP)
پردازش زبان طبیعی (که از زبانشناسی محاسباتی ریشه گرفته است) از رشتههای مختلفی مانند علوم کامپیوتر، هوش مصنوعی، زبانشناسی و علم داده استفاده میکند تا کامپیوترها بتوانند زبان انسان را در دو حالت نوشتاری و گفتاری درک کنند.
زیرشاخههای NLP با تجزیه و تحلیل ساختار جمله و گرامر، به کامپیوترها اجازه میدهند تا متن را درک کنند. برخی از این زیرشاخههای رایج عبارتند از:
- خلاصهسازی (Summarization): این تکنیک، خلاصهای از متون طولانی ارائه میدهد تا یک جمعبندی کوتاه و منسجم از نکات اصلی یک سند ایجاد کند.
- برچسبگذاری اجزای کلام (Part-of-Speech – PoS tagging): این تکنیک به هر توکن (کلمه) در یک سند، بر اساس نقش دستوری آن (مانند اسم، فعل، صفت و غیره) یک برچسب اختصاص میدهد. این مرحله، امکان تحلیل معنایی (semantic analysis) روی متن بدون ساختار را فراهم میکند.
- دستهبندی متن (Text categorization): این کار، که به آن طبقهبندی متن (text classification) نیز گفته میشود، وظیفه تحلیل اسناد متنی و طبقهبندی آنها بر اساس موضوعات یا دستهبندیهای از پیش تعریفشده را بر عهده دارد. این زیرشاخه به ویژه هنگام دستهبندی کلمات مترادف و مخففها بسیار مفید است.
- تحلیل احساسات (Sentiment analysis): این وظیفه، احساسات مثبت یا منفی را از منابع داده داخلی یا خارجی تشخیص میدهد و به شما این امکان را میدهد که تغییرات در نگرش مشتریان را در طول زمان ردیابی کنید. تحلیل احساسات معمولاً برای ارائه اطلاعات در مورد برداشتها از برندها، محصولات و خدمات استفاده میشود. این بینشها میتوانند کسبوکارها را به سمت ارتباط بهتر با مشتریان و بهبود فرآیندها و تجربه کاربری سوق دهند.
استخراج اطلاعات
استخراج اطلاعات (Information Extraction یا IE) تکنیکی است که به شما کمک میکند هنگام جستجو در اسناد مختلف، دقیقاً همان قطعات کلیدی و مرتبط داده را پیدا کنید.
وظیفه اصلی این فرآیند این است که اطلاعات ساختاریافته و مشخصی را از دل متنهای آزاد بیرون بکشد. (برای مثال، از یک پاراگراف متن نامنظم، نام شخص، نام شرکت و یک تاریخ را استخراج کند).
سپس این اطلاعات استخراج شده (مانند موجودیتها، ویژگیها یا روابط بین آنها) را به شکلی مرتب در یک پایگاه داده (database) ذخیره میکند تا بعداً بتوان به راحتی از آنها استفاده کرد.
زیرشاخههای رایج استخراج اطلاعات عبارتند از:
- انتخاب ویژگی (Feature selection): انتخاب ویژگی (یا انتخاب صفت)، فرآیند انتخاب مهمترین ویژگیها (ابعاد) است که بیشترین تأثیر را در خروجی یک مدل predictive analytics دارند.
- استخراج ویژگی (Feature extraction): این فرآیند، انتخاب زیرمجموعهای از ویژگیها برای بهبود دقت در یک وظیفه طبقهبندی (classification) است. این کار به ویژه برای کاهش ابعاد (dimensionality reduction) اهمیت دارد.
- تشخیص موجودیتهای نامگذاریشده (Named-entity recognition – NER): این تکنیک، که به آن شناسایی موجودیت یا استخراج موجودیت نیز گفته میشود، با هدف یافتن و دستهبندی موجودیتهای خاص در متن، مانند نامها یا مکانها، انجام میشود. برای مثال، NER «کالیفرنیا» را به عنوان یک مکان و «مریم» را به عنوان نام یک زن شناسایی میکند.
داده کاوی
داده کاوی (Data mining) فرآیند شناسایی الگوها و استخراج بینشهای مفید از مجموعه کلاندادهها (big data) است. این عمل، هم دادههای ساختاریافته و هم بدون ساختار را ارزیابی میکند تا اطلاعات جدیدی را شناسایی کند و معمولاً برای تحلیل رفتار مصرفکننده در بازاریابی و فروش استفاده میشود.
متن کاوی (Text mining) اساساً زیرشاخهای از داده کاوی است، زیرا متن کاوی بر ساختار بخشیدن به دادههای بدون ساختار و تجزیه و تحلیل آنها برای تولید بینشهای نو تمرکز دارد. تکنیکهایی که در بالا ذکر شد، همگی انواعی از داده کاوی هستند، اما به طور خاص در حوزه تحلیل دادههای متنی قرار میگیرند.
ابزارها و کتابخانههای محبوب متن کاوی
امروزه، پروژههای متن کاوی به ندرت از پایه ساخته میشوند. برنامهنویسان و متخصصان علم داده (data scientists) معمولاً از کتابخانههای قدرتمند، بهویژه در زبان برنامهنویسی پایتون (Python)، استفاده میکنند.
برخی از محبوبترین آنها عبارتند از:
- NLTK (Natural Language Toolkit): یک ابزار بنیادی و عالی برای کارهای پایهای پردازش زبان طبیعی، مانند توکنسازی و ریشهیابی کلمات.
- Scikit-learn: این کتابخانه، ابزار استاندارد یادگیری ماشین در پایتون است و برای کارهایی مانند طبقهبندی متن (text classification)، (مثلاً تشخیص هرزنامه)، و خوشهبندی (clustering) ایدهآل است.
- spaCy: یک کتابخانه مدرن و بسیار سریع که برای استفادههای صنعتی و پروژههای بزرگ بهینهسازی شده و در تشخیص موجودیتهای نامگذاریشده (NER) عملکرد فوقالعادهای دارد.
علاوه بر این، پلتفرمهای نرمافزاری مانند KNIME یا RapidMiner به کاربرانی که دانش کدنویسی ندارند، اجازه میدهند تا فرآیندهای متن کاوی را به صورت بصری پیادهسازی کنند.
چالشهای کلیدی در پروژههای متن کاوی
پیادهسازی متن کاوی با چالشهای بزرگی همراه است، زیرا زبان انسان ذاتاً پیچیده و مبهم است.
ابهام (Ambiguity) یکی از بزرگترین موانع است، یک کلمه میتواند بسته به بافت (context) متن، معانی کاملاً متفاوتی داشته باشد. علاوه بر این، درک مفاهیمی مانند کنایه یا طعنه برای ماشینها بسیار دشوار است. این موضوع میتواند نتایج تحلیل احساسات را به طور کامل اشتباه کند، (برای مثال، یک نظر کنایهآمیز مثبت تشخیص داده شود).
چالش مهم دیگر، کیفیت پایین دادهها است. دادههای بدون ساختار اغلب “کثیف” هستند و پر از غلطهای املایی، اصطلاحات عامیانه، مخففها و فرمتهای ناسازگار میباشند. به همین دلیل، بخش بزرگی از زمان در هر پروژه متن کاوی، صرف فرآیند پیشپردازش (preprocessing) و پاکسازی دادهها میشود تا برای الگوریتمها قابل فهم باشند.
کاربردهای متن کاوی
تحلیل متن روش کار بسیاری از صنایع را متحول کرده است و به آنها این امکان را میدهد که تجربه کاربری محصول را بهبود بخشند و تصمیمات تجاری سریعتر و بهتری اتخاذ کنند.
برخی از موارد استفاده عبارتند از:
- خدمات مشتری (Customer service): ما از راههای مختلفی بازخورد مشتری را از کاربران خود دریافت میکنیم. سیستمهای دریافت بازخورد، مانند چتباتها (chatbots)، نظرسنجیهای مشتریان، نظرات آنلاین، تیکتهای پشتیبانی و پروفایلهای رسانههای اجتماعی، وقتی با ابزارهای تحلیل متن ترکیب میشوند، به شرکتها این امکان را میدهند که تجربه مشتری خود را بهسرعت بهبود بخشند. متن کاوی و تحلیل احساسات میتوانند مکانیزمی را در اختیار شرکتها قرار دهند تا مهمترین مشکلات و دغدغههای مشتریان خود را اولویتبندی کنند، این امر به کسبوکارها اجازه میدهد تا به مسائل فوری در لحظه پاسخ دهند و رضایت مشتری را افزایش دهند.
- مدیریت ریسک (Risk management): متن کاوی در مدیریت ریسک نیز کاربرد دارد. در این حوزه، متن کاوی میتواند با پایش تغییرات در احساسات (بازار) و استخراج اطلاعات از گزارشهای تحلیلگران و وایتپیپرها، بینشهایی پیرامون روندهای صنعت و بازارهای مالی ارائه دهد. این امر بهویژه برای مؤسسات بانکی ارزشمند است، زیرا این دادهها هنگام بررسی سرمایهگذاریهای تجاری در بخشهای مختلف، اطمینان خاطر بیشتری ایجاد میکنند.
- نگهداری و تعمیرات (Maintenance): متن کاوی تصویری غنی و کامل از عملکرد و کارایی محصولات و ماشینآلات ارائه میدهد. با گذشت زمان، متن کاوی با آشکار ساختن الگوهایی که با مشکلات و رویههای نگهداری پیشگیرانه و واکنشی مرتبط هستند، فرآیند تصمیمگیری را خودکار میکند. تحلیل متن به متخصصان نگهداری و تعمیرات کمک میکند تا علت ریشهای چالشها و خرابیها را سریعتر کشف کنند.
- حوزه سلامت (Healthcare): تکنیکهای متن کاوی برای محققان در زمینه زیستپزشکی (biomedical) بهویژه برای خوشهبندی اطلاعات، بهطور فزایندهای ارزشمند شدهاند. بررسی دستی تحقیقات پزشکی میتواند پرهزینه و زمانبر باشد، متن کاوی یک روش خودکار برای استخراج اطلاعات ارزشمند از ادبیات پزشکی (medical literature) فراهم میکند.
- فیلتر کردن هرزنامه (Spam filtering): هرزنامه (Spam) اغلب به عنوان یک نقطه ورود برای هکرها جهت آلوده کردن سیستمهای کامپیوتری به بدافزار (malware) عمل میکند. متن کاوی میتواند روشی برای فیلتر کردن و حذف این ایمیلها از صندوق ورودی (inbox) ارائه دهد، که این امر تجربه کاربری کلی را بهبود بخشیده و خطر حملات سایبری (cyber-attacks) را برای کاربران نهایی به حداقل میرساند.
سوالات متداول
۱. تفاوت اصلی متن کاوی و داده کاوی چیست؟
داده کاوی (Data Mining) یک مفهوم گستردهتر است که شامل استخراج الگو از هر نوع دادهای (چه ساختاریافته مانند جداول فروش، و چه بدون ساختار) میشود. متن کاوی (Text Mining) به طور خاص، زیرشاخهای از داده کاوی است که فقط بر روی دادههای متنی بدون ساختار تمرکز دارد.
۲. آیا متن کاوی همان پردازش زبان طبیعی (NLP) است؟
خیر، اما این دو ارتباط بسیار نزدیکی دارند. پردازش زبان طبیعی (NLP) بر درک و پردازش زبان انسان توسط کامپیوتر (مانند درک گرامر یا معنای کلمات) تمرکز دارد. متن کاوی از تکنیکهای NLP به عنوان ابزار استفاده میکند تا بتواند الگوهای بزرگتری را در حجم وسیعی از متن کشف کند. به طور ساده، NLP ابزار است و متن کاوی فرآیند استفاده از آن ابزار برای کشف بینش است.
۳. مهمترین مرحله در یک پروژه متن کاوی چیست؟
اگرچه همه مراحل مهم هستند، اما اکثر متخصصان معتقدند پیشپردازش (Preprocessing) یا همان پاکسازی دادهها، حیاتیترین مرحله است. اگر دادههای متنی شما پر از غلطهای املایی، اصطلاحات عامیانه ناسازگار یا «نویز» باشد، نتایج الگوریتمهای شما دقیق و قابل اعتماد نخواهد بود.
اگر به کار با داده های متنی و پردازش زبان طبیعی علاقه دارید، دوره جامع آموزش NLP سایت دیتایاد، جامع ترین آموزش این حوزه در کامیونیتی فارسی زبان ایران هست. این دوره از درک متن، پردازش زبان طبیعی تا مدلهای زبانی بزرگ و بسیاری از دیگر مباحث پیشرفته رو پوشش میده.




















