

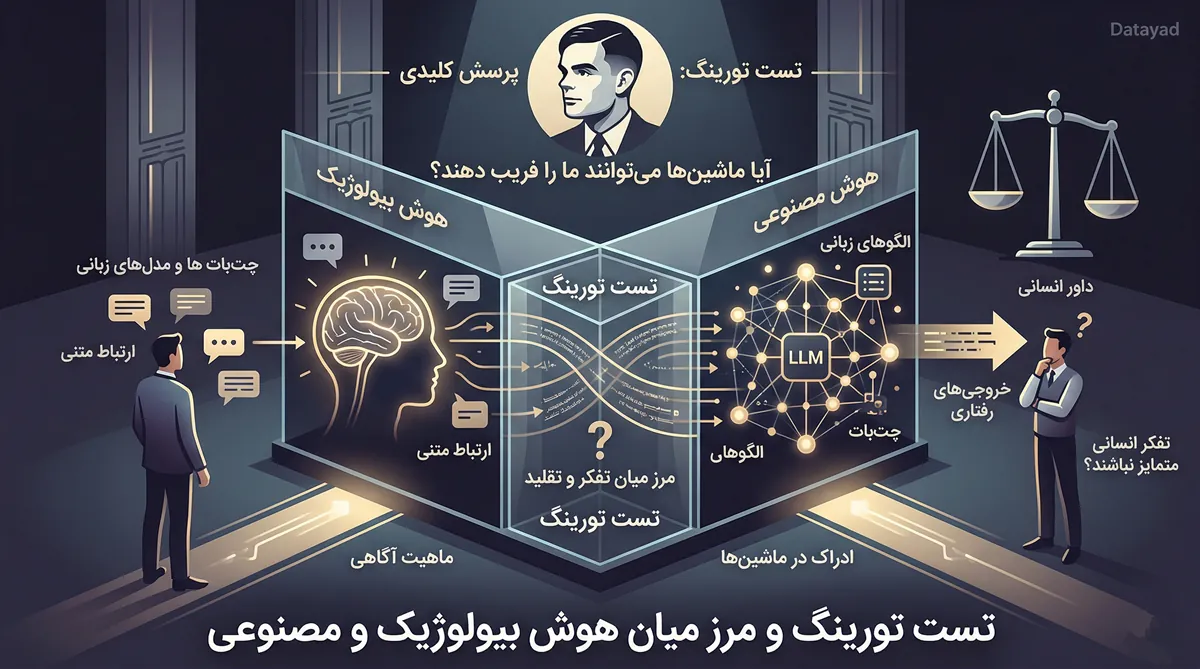
تست تورینگ به عنوان یکی از بنیادیترین مفاهیم در حوزه هوش مصنوعی، پرسشی کلیدی را مطرح میکند: آیا ماشینها میتوانند به گونهای رفتار کنند که از تفکر انسانی متمایز نباشند؟ این آزمون که در سالهای آغازین توسعه علوم کامپیوتر توسط آلن تورینگ طراحی شد، به جای تمرکز بر ساختار داخلی مغز الکترونیک، بر خروجیهای رفتاری و توانایی برقراری ارتباط متنی تمرکز دارد تا مرز میان هوش بیولوژیک و مصنوعی را به چالش بکشد. در حقیقت، نقطه شروع بسیاری از روایتهای تاریخچه هوش مصنوعی، همین آزمون ساده تورینگ است.
در دنیای امروز که چتباتها و مدلهای زبانی بزرگ به بخشی جداییناپذیر از زندگی دیجیتال تبدیل شدهاند، بازخوانی مفاهیم این تست ضرورت دوچندانی یافته است. در این مطلب از بخش آموزش هوش مصنوعی، به بررسی این موضوع میپردازیم که چگونه یک سیستم میتواند با تقلید الگوهای زبانی، داور انسانی را فریب دهد؛ درکی که نه تنها به شناخت بهتر فناوریهای فعلی کمک میکند، بلکه دریچهای به سوی مباحث فلسفی عمیق در زمینه ماهیت آگاهی و ادراک در ماشینها میگشاید.
مفهوم و فلسفه بازی تقلید
آلن تورینگ برای پاسخ به پرسش بنیادین «آیا ماشینها میتوانند فکر کنند؟»، آزمونی عملی را پیشنهاد داد که ابتدا آن را «بازی تقلید» نامید. این همان نقطهای است که درک میکنیم تست تورینگ چیست و چرا هنوز در مباحث تخصصی هوش مصنوعی اهمیت دارد. او بهجای درگیر شدن در تعاریف پیچیده از ماهیت فکر، معیار را بر توانایی شبیهسازی رفتار انسانی گذاشت.
فلسفه اصلی این بازی بر پایه رفتارگرایی بنا شده است. تورینگ معتقد بود اگر یک سیستم بتواند بهگونهای عمل کند که از رفتار یک موجود هوشمند متمایز نباشد، باید آن را هوشمند دانست. در نسخه اولیه این بازی، یک داور باید از طریق پیامهای متنی تشخیص میداد که طرف مقابل او یک مرد است یا زن. در مرحله بعد، ماشین جایگزین یکی از شرکتکنندگان شد تا قدرت تقلید خود را به چالش بکشد.
در این ساختار، اگر هوش مصنوعی بتواند داور را فریب دهد و او را متقاعد کند که در حال گفتگو با یک انسان است، موفقیت خود را اثبات کرده است. تمرکز این تست بر پردازش زبان طبیعی و کیفیت برقراری ارتباط است. بازی تقلید نشان میدهد که هوش را باید از روی خروجی و عملکرد سنجید؛ یعنی اگر ماشینی بتواند به شکلی متقاعدکننده مانند انسان صحبت کند، از دیدگاه این آزمون، به سطح مطلوبی از هوشمندی دست یافته است.

ارکان و مراحل عملیاتی آزمون
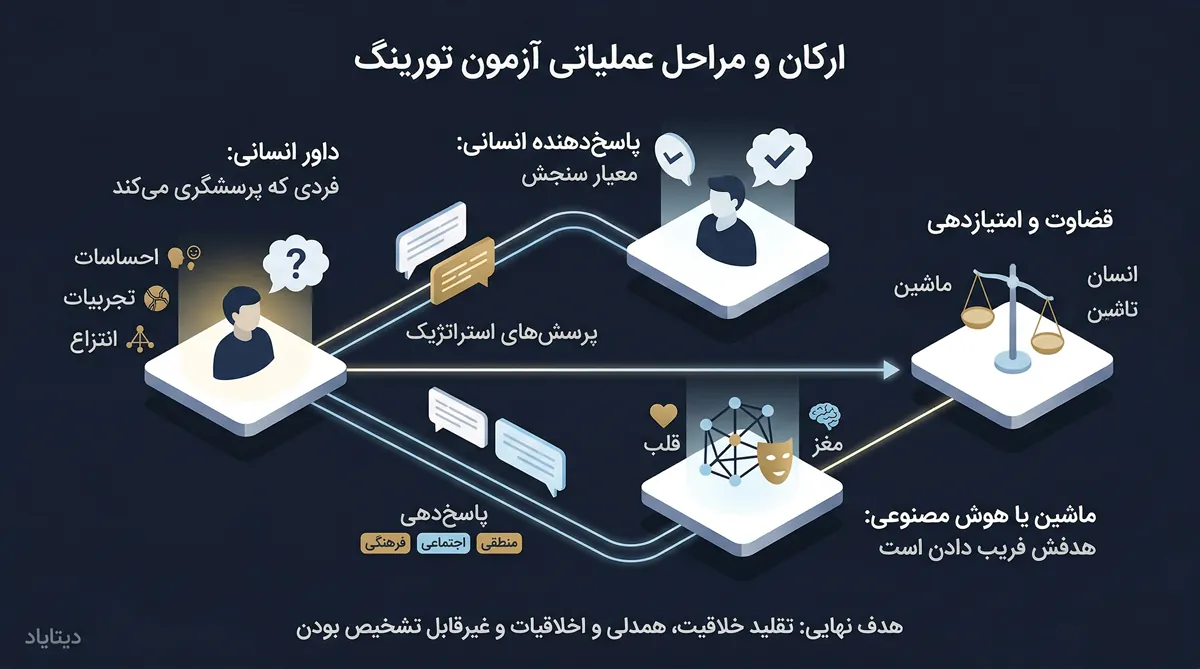
تست تورینگ برای سنجش توانایی یک ماشین در نمایش رفتارهای هوشمندانه، مشابه با انسان طراحی شده است. این آزمون که در ابتدا «بازی تقلید» نامیده میشد، بر پایه سه رکن اصلی و یک ساختار اجرایی دقیق بنا شده است. برای درک بهتر تست تورینگ، باید جزئیات عملیاتی آن را بشناسید.
شرکتکنندگان اصلی در آزمون
- داور انسانی: فردی که وظیفه پرسشگری را بر عهده دارد. او باید با طرح سوالات مختلف، تلاش کند هویت پاسخدهندگان را فاش کند.
- پاسخدهنده انسانی: فردی که به سوالات داور پاسخهای طبیعی میدهد و به عنوان معیار سنجش (Baseline) عمل میکند.
- ماشین یا هوش مصنوعی: سیستمی که هدف آن فریب دادن داور است. این سیستم باید به گونهای پاسخ دهد که داور متقاعد شود با یک انسان در حال گفتگو است.
مراحل اجرایی و عملیاتی تست تورینگ
اجرای این تست شامل مراحل منظمی است که بر پایه پنهانسازی هویتها استوار است:
- ایجاد محیط ایزوله: داور و شرکتکنندگان در محیطهای مجزا قرار میگیرند. ارتباطات تنها از طریق رابطهای متنی (مانند چت کامپیوتری) انجام میشود تا نشانه های فیزیکی مثل ظاهر یا لحن صدا، داور را راهنمایی نکند.
- طرح پرسشهای استراتژیک: داور سوالاتی را مطرح میکند که فراتر از دادههای خام هستند. این سوالات معمولا شامل موضوعات احساسی، تجربیات شخصی، سناریوهای فرضی و مفاهیم انتزاعی است تا قدرت پردازش زبان طبیعی در هوش مصنوعی را به چالش بکشد.
- پردازش و پاسخدهی: ماشین باید با تحلیل کلمات کلیدی و درک بافتار جملات، پاسخی تولید کند که نه تنها منطقی، بلکه از نظر اجتماعی و فرهنگی نیز انسانی به نظر برسد.
- قضاوت و امتیازدهی: در مرحله نهایی، داور بر اساس پاسخهای دریافت شده قضاوت میکند. اگر داور نتواند با اطمینان تشخیص دهد کدام پاسخ متعلق به ماشین است، یا هوش مصنوعی را به جای انسان اشتباه بگیرد، سیستم از آزمون سربلند بیرون آمده است.
موفقیت در این مراحل به توانایی هوش مصنوعی در تقلید خلاقیت، همدلی و اخلاقیات بستگی دارد. در واقع، هدف نهایی آزمون این است که ثابت کند آیا یک ماشین میتواند به گونهای عمل کند که از نظر ارتباطی، از انسان قابل تشخیص نباشد یا خیر.
مقایسه مدلهای موفق و جوایز جهانی
پاسخ به پرسش تست تورینگ در طول دههها تغییر کرده است. مدلهای مختلف هوش مصنوعی با استراتژیهای گوناگون سعی در متقاعد کردن داوران داشتهاند. برخی با تمرکز بر خطاهای انسانی و برخی با قدرت تحلیل بالا در این مسیر قدم برداشتهاند. جدول زیر مقایسهای میان شاخصترین تلاشها و معیارهای جهانی در این حوزه است:
| نام مدل یا جایزه | استراتژی اصلی برای موفقیت | وضعیت در آزمون تورینگ |
|---|---|---|
| الیزا (ELIZA) | تکرار کلمات کاربر و الگوی تطبیق جملات | موفق در فریب کاربران در محیطهای محدود |
| یوجین گوستمن (Eugene Goostman) | استفاده از شخصیت یک کودک برای توجیه اشتباهات | ادعای عبور از مرز ۳۰ درصد موفقیت در فریب داوران |
| مدلهای زبانی بزرگ (مانند ChatGPT) | درک عمیق بافت متن و تولید پاسخهای همدلانه | عبور غیررسمی از تست در بسیاری از گفتگوهای روزمره |
| جایزه لوبنر (Loebner Prize) | رقابت سالانه برای شناسایی هوشمندترین چتبات | معیار اصلی برای سنجش پیشرفت هوش مصنوعی کلامی |
| آزمون تجسمی تورینگ | ارزیابی توانایی تشخیص جزئیات در تصاویر | نسخه تکامل یافته برای سنجش ادراک بصری ماشین |
توسعهدهندگان هوش مصنوعی برای دستیابی به جوایز جهانی، صرفاً بر دانش تکیه نمیکنند. آنها دریافتهاند که رفتار انسانی شامل نقصهایی مانند تردید یا شوخطبعی است. به همین دلیل، مدلهای موفق آنهایی هستند که به جای پاسخهای دایرهالمعارفی، ارتباطی نزدیک به لحن طبیعی انسان برقرار میکنند.
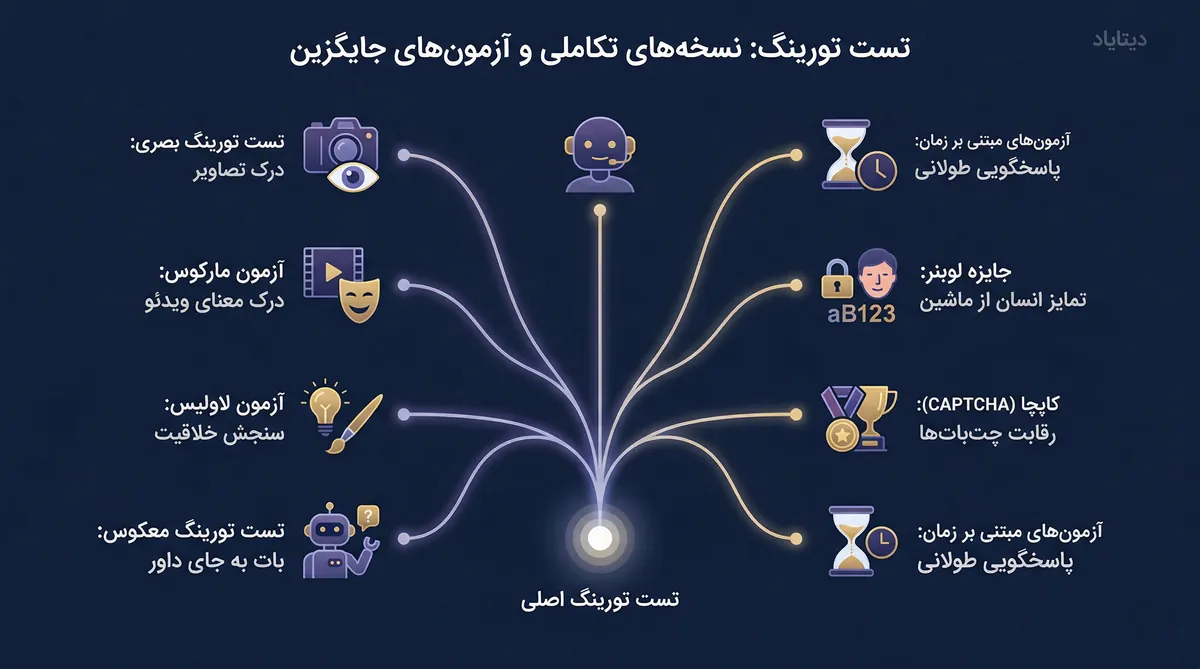
نسخههای تکاملی و آزمونهای جایگزین تست تورینگ
- تست تورینگ بصری: این آزمون توانایی هوش مصنوعی در درک و شناسایی جزئیات تصاویر را بررسی میکند. ماشین در این نسخه باید ویژگیهای بصری محیط را مشابه انسان تحلیل و توصیف کند.
- آزمون مارکوس: تمرکز این تست بر درک عمیق معنای محتوای ویدئویی است. هوش مصنوعی باید بتواند طرح داستان، طنز یا کنایههای موجود در یک فیلم را به درستی تشخیص دهد تا مشخص شود سطح درک آن از مفاهیم انسانی چقدر است.
- آزمون لاولیس: این نسخه برای سنجش خلاقیت طراحی شده است. برای موفقیت در این آزمون، هوش مصنوعی باید ایدهای کاملا نو و غافلگیرکننده تولید کند که فراتر از دادههای آموزشی اولیه او باشد.
- تست تورینگ معکوس: در این مدل، جای داور و شرکتکننده عوض میشود. یک سیستم هوش مصنوعی نقش بازجو را ایفا میکند تا تشخیص دهد آیا مخاطب او یک انسان است یا یک ربات دیگر.
- کپچا (CAPTCHA): این ابزار یک نسخه کاملا خودکار برای تفکیک انسان از ماشین است. در مورد کاربرد روزمره تست تورینگ، میتوان به همین سیستمهای امنیتی وبسایتها اشاره کرد که جلوی فعالیت باتهای مخرب را میگیرند.
- جایزه لوبنر: این رقابت فرصتی برای ارزیابی چتباتهای پیشرفته فراهم میکند. در این مسابقه، برنامههایی که بتوانند در بازههای زمانی مشخص داوران را بیشتر فریب دهند، به عنوان نمونههای موفق هوش مصنوعی معرفی میشوند.
- آزمونهای مبتنی بر زمان: برخی منتقدان پیشنهاد میدهند زمان گفتگو با ماشین به بیش از صد دقیقه افزایش یابد. این کار باعث میشود قدرت استدلال و ثبات رفتاری سیستم در بلندمدت بهتر سنجیده شود.
چالشهای فنی و محدودیتهای شناختی
تست تورینگ با وجود قدمت زیاد، با انتقادات فنی و فلسفی متعددی روبروست. یکی از بزرگترین چالشها این است که این آزمون تنها رفتار بیرونی ماشین را ارزیابی میکند. در واقع، موفقیت در این تست به معنای وجود شعور یا درک واقعی در هوش مصنوعی نیست؛ بلکه تنها نشان دهنده توانایی سیستم در تقلید از الگوهای انسانی است. یک ماشین ممکن است با استفاده از پایگاه داده های عظیم و پردازش زبان طبیعی، پاسخ های متقاعدکننده ای تولید کند بدون اینکه معنای واقعی کلمات را بفهمد.
محدودیت دیگر به ذهنیت داوران بازمیگردد. تشخیص اینکه تست تورینگ چگونه اجرا میشود، به شدت به دانش و تجربه داور بستگی دارد. اگر داور سوالات سطحی بپرسد یا با محدودیت های فنی هوش مصنوعی آشنا نباشد، احتمال فریب خوردن او بالا میرود. از سوی دیگر، پدیده ای به نام «اثر همدست» وجود دارد که در آن داور ممکن است یک انسان واقعی را به اشتباه، ماشین تشخیص دهد.
همچنین، این آزمون به طور عمده بر مهارت های کلامی و نوشتاری تمرکز دارد. ابعاد دیگر هوش مانند خلاقیت بصری یا درک منطقی پیچیده در این قالب گنجانده نمیشوند. برخی سیستم ها با استفاده از ترفندهایی مثل پاسخ های مبهم، شوخی یا حتی ایجاد اشتباهات دستوری عمدی سعی میکنند نقص های شناختی خود را پنهان کنند. این موضوع ثابت میکند که عبور از تست تورینگ همیشه به معنای رسیدن به سطح تفکر انسانی نیست.




















