

در درس قبلی با SVM ها آشنا شدیم. اگر درس قبلی را نخوانده اید، حتما برگردید آن را بخوانید و بعد به این درس چهل و دوم یعنی دسته بندی داده ها با SVM ها در پایتون مراجعه کنید.
در یادگیری ماشین، ماشین های بردار پشتیبان (SVMها یا شبکههای بردار پشتیبان) مدلهای یادگیری نظارت شده با الگوریتمهای یادگیری مرتبط هستند که دادههای مورد استفاده برای تجزیه و تحلیل دستهبندی و رگرسیون را تحلیل میکنند. ماشین بردار پشتیبان (SVM) یک دستهبند تمایزی است که به طور رسمی توسط یک صفحهی مجزا تعریف میشود. به عبارت دیگر، با توجه به دادههای آموزشی برچسبدار (یادگیری نظارت شده)، الگوریتم یک صفحهی بهینهی مجزا را خروجی میدهد که مثالهای جدید را دستهبندی میکند.
ماشین بردار پشتیبان (SVM) چیست؟
یک مدل SVM نمایشی از مثالها به عنوان نقاطی در فضا است که به گونهای نگاشت شدهاند تا مثالهای دستههای جداگانه توسط یک فاصلهی روشن که تا حد امکان وسیع است، جدا شوند. علاوه بر انجام دستهبندی خطی، SVMها میتوانند به صورت مؤثری دستهبندی غیرخطی را انجام دهند و به طور ضمنی ورودیهای خود را به فضاهای ویژگی با بعد بالا نگاشت کنند.
SVM چه کاری انجام میدهد؟
در حالتی که مجموعهای از نمونههای آموزشی داریم که هر کدام به یکی از دو دسته تعلق دارند، الگوریتم آموزش SVM مدلی میسازد که نمونههای جدید را به یکی از این دستهها اختصاص میدهد. این کار را به عنوان یک دستهبند خطی باینری و غیر احتمالاتی انجام میدهد.
قبل از اینکه ادامه این مقاله را بخوانید، مهم است که درک پایهای از آن داشته باشید. در اینجا ما درباره مثالی از دستهبندی SVM در مورد دادههای سرطان UCI با استفاده از ابزارهای یادگیری ماشین مانند scikit-learn که با پایتون سازگار است، صحبت خواهیم کرد.
پیشنیازها:
Numpy، Pandas، matplot-lib، scikit-learn.
حالا بیایید نگاهی به یک مثال از دسته بندی داده ها با SVM ها در پایتون بیندازیم. اول باید یک مجموعه داده ایجاد کنیم.
# importing scikit learn with make_blobs from sklearn.datasets import make_blobs # creating datasets X containing n_samples # Y containing two classes X, Y = make_blobs(n_samples=500, centers=2, random_state=0, cluster_std=0.40) import matplotlib.pyplot as plt # plotting scatters plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='spring'); plt.show()
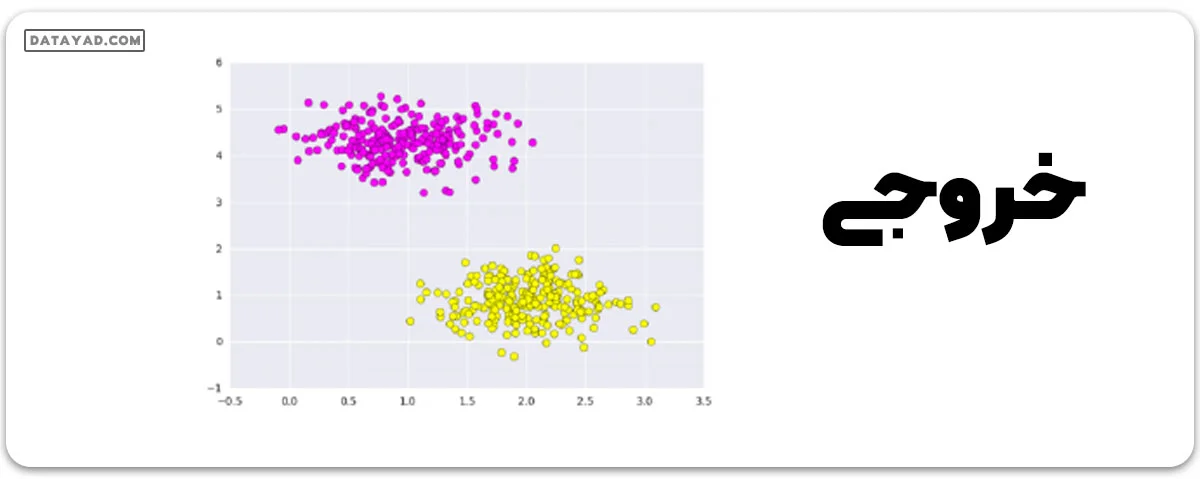
آنچه ماشینهای بردار پشتیبان انجام میدهند، تنها کشیدن یک خط بین دو کلاس نیست، بلکه در نظر گرفتن یک منطقه در اطراف خط با عرض مشخصی است. در اینجا مثالی از آنچه میتواند به نظر برسد آورده شده است.
# creating linspace between -1 to 3.5 xfit = np.linspace(-1, 3.5) # plotting scatter plt.scatter(X[:, 0], X[:, 1], c=Y, s=50, cmap='spring') # plot a line between the different sets of data for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]: yfit = m * xfit + b plt.plot(xfit, yfit, '-k') plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none', color='#AAAAAA', alpha=0.4) plt.xlim(-1, 3.5); plt.show()
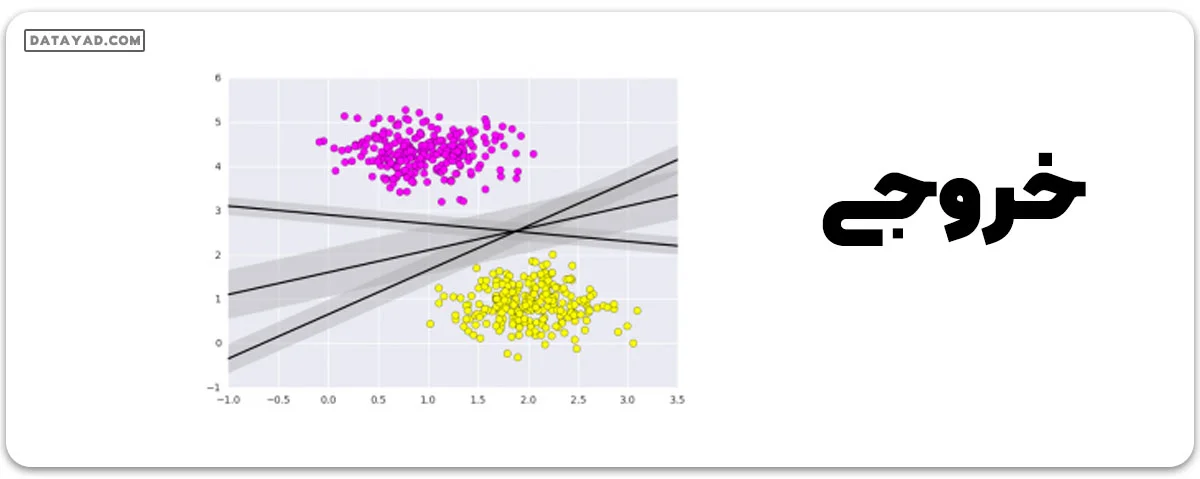
این استدلال پشت ماشینهای بردار پشتیبان است که یک مدل تمایز خطی را بهینه میکنند و فاصله عمودی بین دادهها را نشان میدهند. حالا بیایید با استفاده از دادههای آموزشیمان، دستهبند را آموزش دهیم. قبل از آموزش، باید دادههای سرطان را به عنوان یک فایل csv وارد کنیم که در آن دو ویژگی از بین تمام ویژگیها را آموزش خواهیم داد.
# importing required libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# reading csv file and extracting class column to y.
x = pd.read_csv("C:\...\cancer.csv")
a = np.array(x)
y = a[:,30] # classes having 0 and 1
# extracting two features
x = np.column_stack((x.malignant,x.benign))
# 569 samples and 2 features
x.shape
print (x),(y)
خروجی:
# importing required libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# reading csv file and extracting class column to y.
x = pd.read_csv(“C:\…\cancer.csv”)
a = np.array(x)
y = a[:,30] # classes having 0 and 1
# extracting two features
x = np.column_stack((x.malignant,x.benign))
# 569 samples and 2 features
x.shape
print (x),(y)
استفاده از ماشین بردار پشتیبان
حالا ما یک دستهبند ماشین بردار پشتیبانی را بر روی این نقاط تنظیم خواهیم کرد. در حالی که جزئیات ریاضی مدل احتمالاتی جالب هستند، ما آنها را برای خواندن در جای دیگری قرار میدهیم. در عوض، فقط الگوریتم scikit-learn را به عنوان یک جعبه سیاه در نظر میگیریم که کار فوق را انجام میدهد.
# import support vector classifier # "Support Vector Classifier" from sklearn.svm import SVC clf = SVC(kernel='linear') # fitting x samples and y classes clf.fit(x, y)
پس از تنظیم، این مدل میتواند برای پیشبینی مقادیر جدید استفاده شود:
clf.predict([[120, 990]]) clf.predict([[85, 550]])
خروجی:
array([ 0.])
array([ 1.])
بیایید نگاهی به نمودار بیندازیم تا ببینیم چگونه نمایش داده میشود.
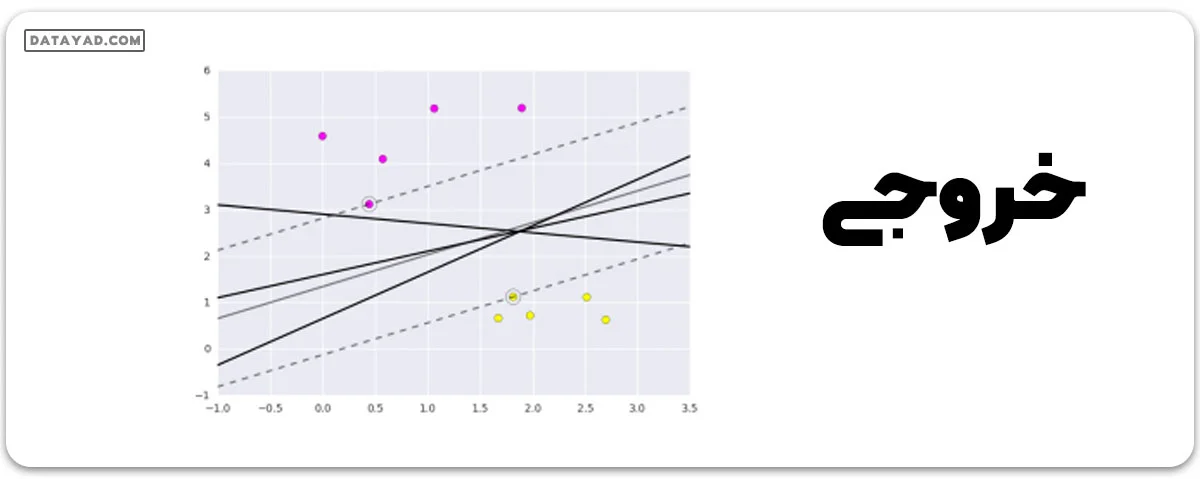
این گراف با تجزیه و تحلیل دادههای گرفته شده و استفاده از روشهای پیشپردازش برای ساخت صفحههای بهینه به وسیله توابع matplotlib به دست میآید.










