

بیایید با استفاده از کتابخانه sklearn پایتون و مجموعه دادههای Iris که در کتابخانه دادههای پایتون یافت میشود، یک SVM با کرنل خطی ایجاد کنیم.
کرنل خطی زمانی استفاده میشود که دادهها به صورت خطی جداپذیر باشند، یعنی بتوان با استفاده از یک خط آنها را جدا کرد. این یکی از رایجترین کرنلهای استفاده شده است. اغلب زمانی استفاده میشود که تعداد زیادی ویژگی در یک مجموعه داده خاص وجود داشته باشد. یکی از مثالهایی که ویژگیهای زیادی دارد، طبقهبندی متن است، زیرا هر حرف الفبا یک ویژگی جدید است. بنابراین ما اغلب در طبقهبندی متن از کرنل خطی استفاده میکنیم.
توجه: برای اجرای کد زیر باید اینترنت متصل باشید زیرا شامل دانلود دادهها میشود.

در تصویر بالا، دو مجموعه ویژگی وجود دارد: ویژگیهای “آبی” و ویژگیهای “زرد”. از آنجایی که اینها به راحتی قابل جداسازی هستند یا به عبارت دیگر، به صورت خطی جداپذیر هستند، بنابراین میتوان از کرنل خطی در اینجا استفاده کرد.
مزایای استفاده از کرنل خطی
1. آموزش SVM با کرنل خطی سریعتر از آموزش با هر کرنل دیگری است.
2. هنگام آموزش SVM با کرنل خطی، تنها بهینهسازی پارامتر تنظیم C لازم است. از طرف دیگر، هنگام آموزش با کرنلهای دیگر، نیاز به بهینهسازی پارامتر γ وجود دارد که این به معنای انجام جستجوی شبکهای است که معمولاً زمان بیشتری طلب میکند.
# Import the Libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
# Import some Data from the iris Data Set
iris = datasets.load_iris()
# Take only the first two features of Data.
# To avoid the slicing, Two-Dim Dataset can be used
X = iris.data[:, :2]
y = iris.target
# C is the SVM regularization parameter
C = 1.0
# Create an Instance of SVM and Fit out the data.
# Data is not scaled so as to be able to plot the support vectors
svc = svm.SVC(kernel ='linear', C = 1).fit(X, y)
# create a mesh to plot
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# Plot the data for Proper Visual Representation
plt.subplot(1, 1, 1)
# Predict the result by giving Data to the model
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap = plt.cm.Paired, alpha = 0.8)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
# Output the Plot
plt.show()
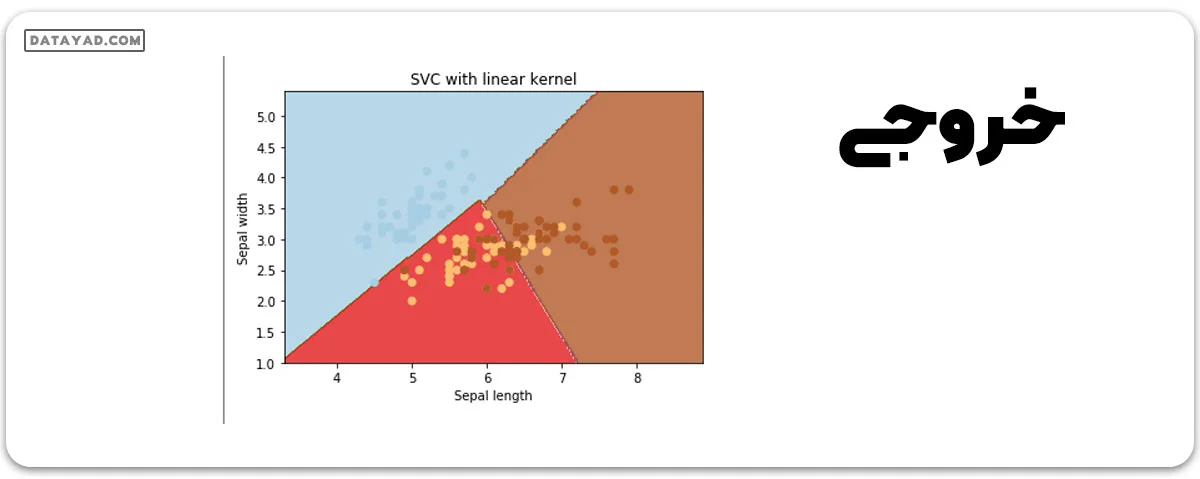
در اینجا، تمام ویژگیها با استفاده از خطوط ساده جدا شدهاند، که این نشاندهنده کرنل خطی است.











