

پاکسازی داده ها یکی از برجستهترین مراحل یادگیری ماشین است. این مرحله در ساختن یک مدل نقش پررنگی دارد. اگرچه این بخش ممکن است جذاب به نظر نرسد و راز خاصی هم نداشته باشد، اما موفقیت یک پروژه بطور قابل توجهی به پاکسازی دادهها وابسته است.
دانشمندان حرفهای داده مقدار زیادی از وقت خود را به این مرحله اختصاص میدهند، زیرا باور دارند:
“دادهی خوب، بهتر از الگوریتمهای پیچیده است”.
اگر دادههای تمیزی داشته باشیم، با الگوریتمهای ساده هم میتوانیم نتایج بسیار خوبی بگیریم، که در مواقعی، به خصوص وقتی مجموعه داده بزرگی داریم، بسیار مفید است. البته بسته به نوع دادهها، نحوه پاکسازی هم متفاوت است، اما همیشه میتوان با یک رویکرد منظم شروع کرد.
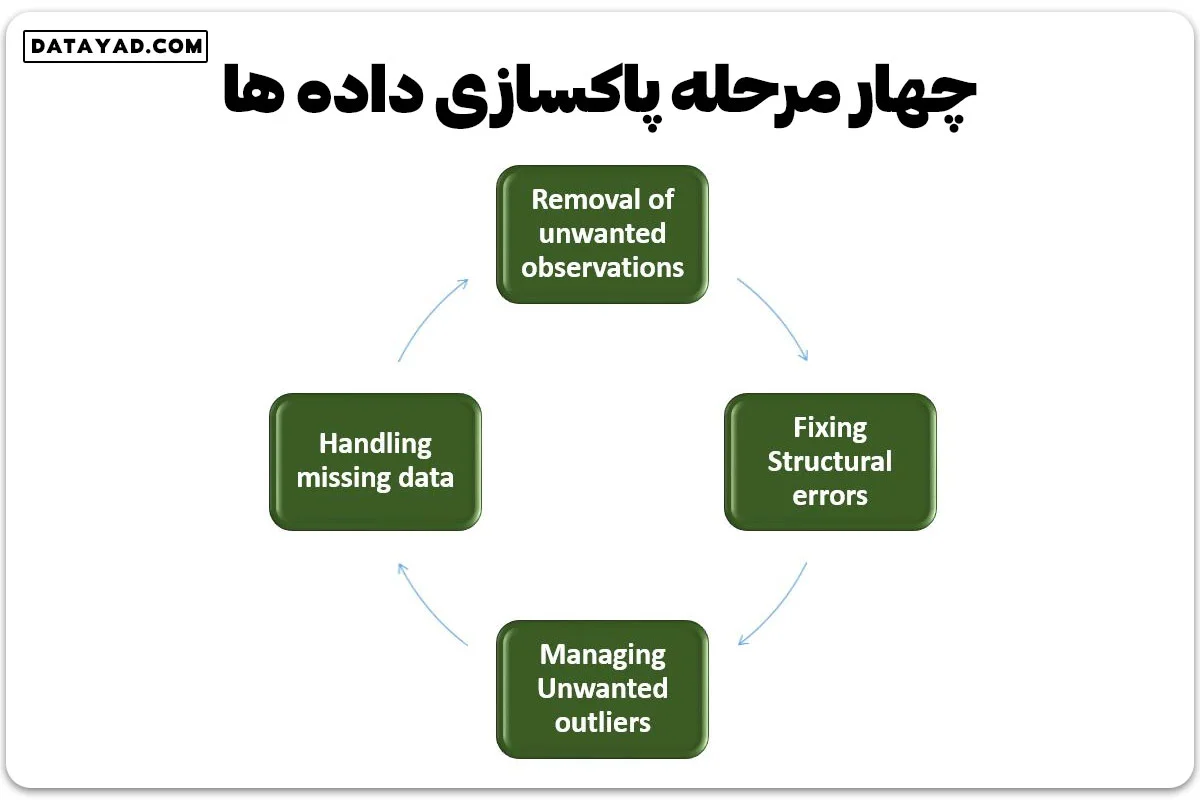
مراحل پاکسازی داده ها
پاکسازی داده ها یک مرحله حیاتی در فرایند یادگیری ماشین است. در این مرحله، دادههای گمشده، تکراری یا غیرمرتبط شناسایی و حذف میشوند. هدف از این فرآیند اطمینان از دقت و سازگاری دادهها و عدم وجود خطا در آنهاست؛ چرا که دادههای غلط یا نامناسب میتوانند عملکرد مدل یادگیری ماشین را به خطر بیاندازند.
در این قدم، خطاها و ناهمگونیهای داده شناسایی و اصلاح میشوند تا کیفیت و کارایی داده افزایش یابد. این کار حیاتی است، زیرا دادههای خام معمولاً ناقص، نامنسجم و همراه با نویز هستند و این موارد میتواند بر دقت و معتبر بودن نتایج به دست آمده تأثیر بگذارد.
در زیر مراحل رایج پاکسازی داده ها (data cleaning) آورده شده است:
✔️ وارد کردن کتابخانههای لازم
✔️ بارگذاری مجموعه داده
✔️ بررسی اطلاعات داده با استفاده از ()df.info
import pandas as pd
import numpy as np
# Load the dataset
df = pd.read_csv('train.csv')
df.head()
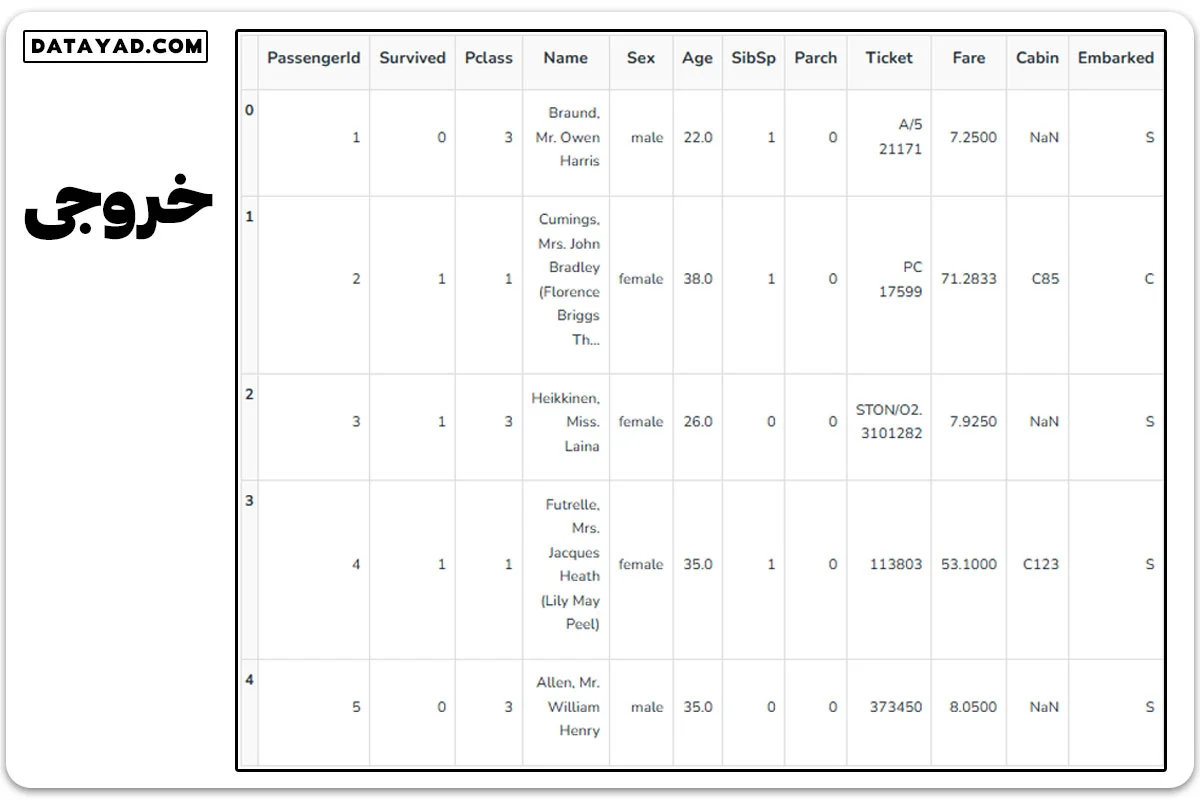
1- بررسی و کاوش در دادهها
این مرحله به بررسی داده و فهمیدن ساختار آن میپردازد، به ویژه شناسایی مقادیر گمشده، خارج از محدوده و ناهمگونیها.
- سطرهای تکراری را مورد بررسی قرار دهید.
df.duplicated()

با استفاده از ()df.info اطلاعات داده را بررسی کنید.
df.info()
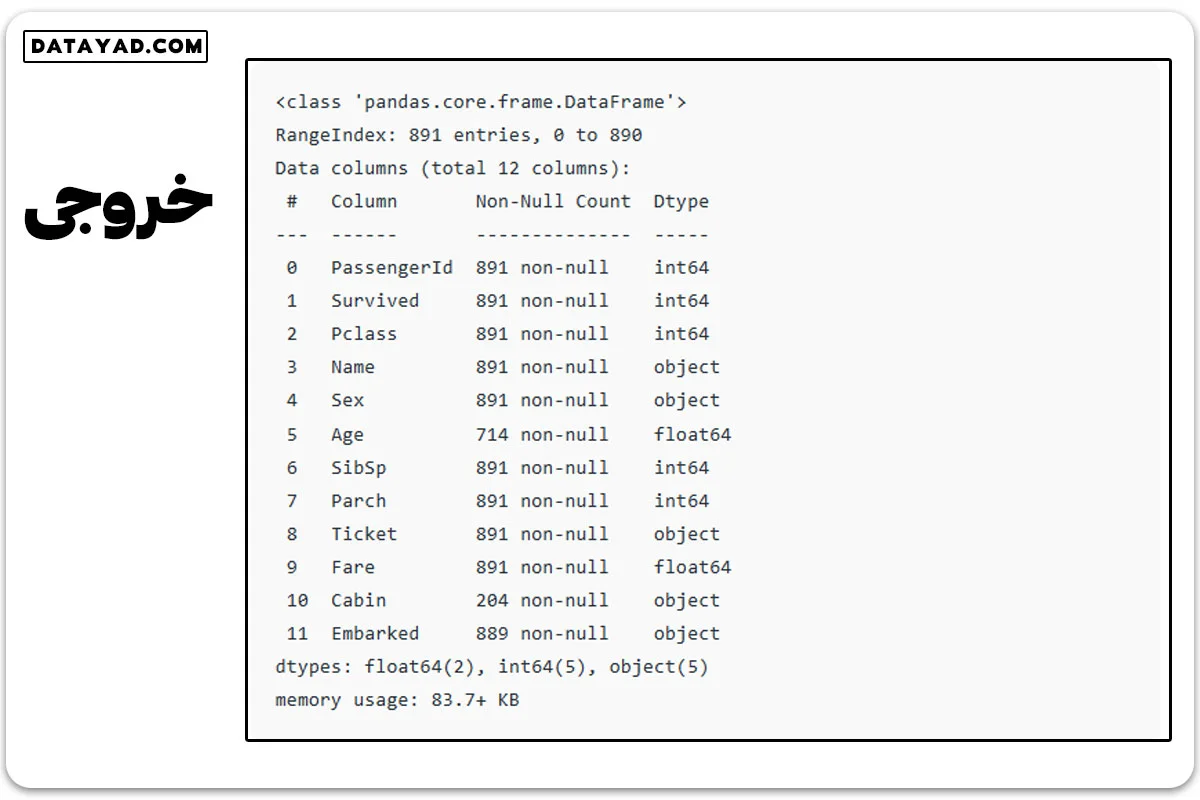
از این اطلاعات، مشاهده میشود که ستونهای “سن” و “کابین” تعداد متفاوتی دارند. همچنین، برخی ستونها دستهبندی شده و نوع داده آنها شیء است، در حالی که برخی دیگر مقادیر عددی یا اعشاری دارند.
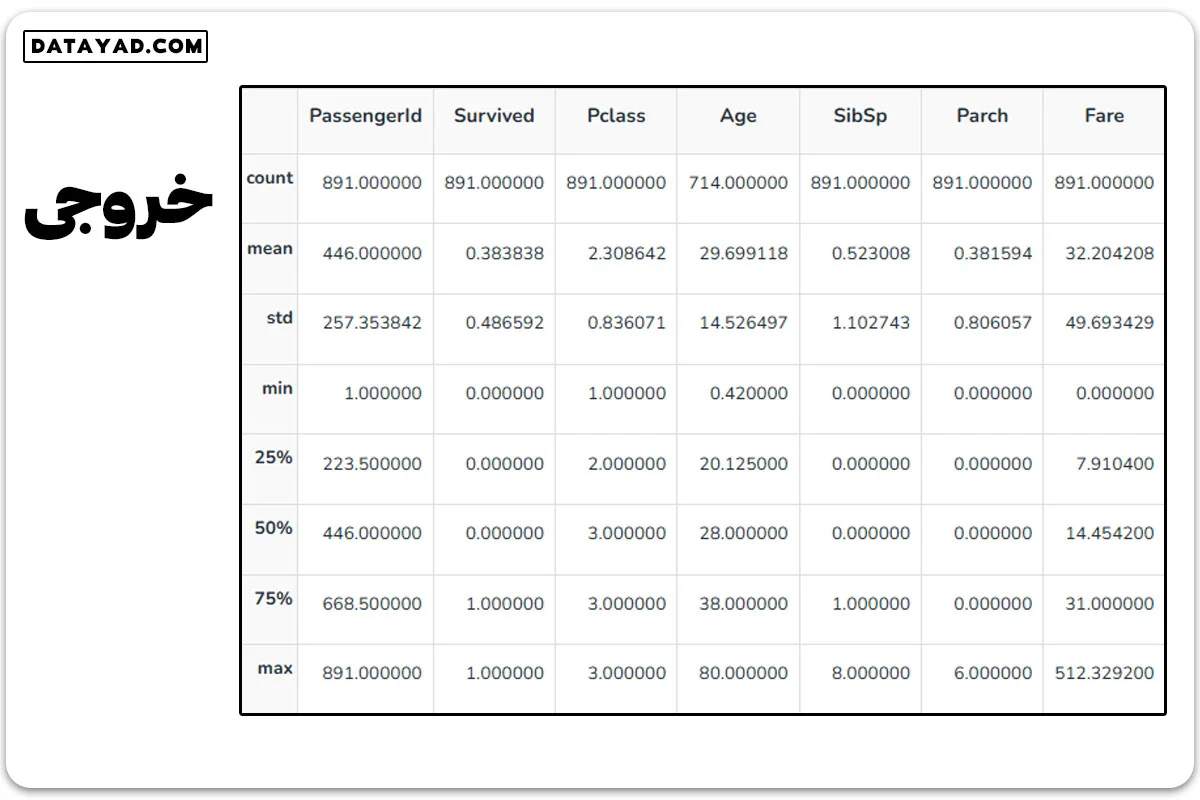
برای دیدن ساختار داده، از ()df.describe استفاده میکنیم.
df.describe()
ستونهای دستهبندی و عددی را مورد بررسی قرار دهید.
# Categorical columns
cat_col = [col for col in df.columns if df[col].dtype == 'object']
print('Categorical columns :',cat_col)
# Numerical columns
num_col = [col for col in df.columns if df[col].dtype != 'object']
print('Numerical columns :',num_col)
تعداد کلی مقادیر منحصر به فرد در ستونهای دستهبندی را بررسی کنید.
df[cat_col].nunique()

2- حذف مشاهدات غیرضروری
این مرحله به حذف موارد تکراری یا غیرضروری از دادهها میپردازد. موارد تکراری معمولاً در هنگام جمعآوری داده به وجود میآیند و موارد غیرضروری آنهایی هستند که مستقیماً به موضوع مورد بررسی ما مرتبط نیستند.
- موارد تکراری میتوانند به کارایی تحلیل ما آسیب بزنند، چرا که این موارد چه به نفع یا علیه تحلیل ما باشند، ممکن است نتایج را وارونه کنند.
- موارد غیرضروری دادههایی هستند که برای ما ارزشی ندارند و میتوانیم آنها را بلافاصله حذف کنیم.
حالا باید بر اساس موضوع تحلیل تصمیم بگیریم. میدانیم دستگاهها به خوبی با دادههای متنی کنار نمیآیند. باید یا مقادیر دستهبندی را به مقادیر عددی تبدیل کنیم یا آنها را حذف کنیم. مثلاً در اینجا، ستون “نام” را حذف میکنیم، چرا که نامها همیشه منحصر به فرد هستند و تأثیر زیادی بر هدف ندارند. در مورد “بلیت”، اول 50 بلیت منحصر به فرد را مرور میکنیم.
df['Ticket'].unique()[:50]

از مرور بلیتها مشخص است که ترکیبهای مختلفی دارند، مثل “A/5 21171”. این یک موقعیت برای مهندسی ویژگی است، جایی که میتوانیم ویژگیهای جدیدی از ستونها استخراج کنیم. در این حالت، ستونهای “نام” و “بلیت” را حذف میکنیم.
ستونهای نام و بلیت را حذف کنید.
df1 = df.drop(columns=['Name','Ticket']) df1.shape
خروجی: (891, 10)
3- مواجهه با داده های گم شده
دادههای گمشده یکی از چالشهای رایج در دادههای واقعی است. این مشکل میتواند به علت خطاهای انسانی، مشکلات در جمعآوری داده یا نقص سیستمی پیش آید. چندین راهبرد برای مقابله با این موضوع وجود دارد، از جمله جایگزینی، حذف یا تغییر دادهها.
با استفاده از ()df.isnull میتوانیم میزان دادههای گمشده در هر ستون را بررسی کنیم.
round((df1.isnull().sum()/df1.shape[0])*100,2)
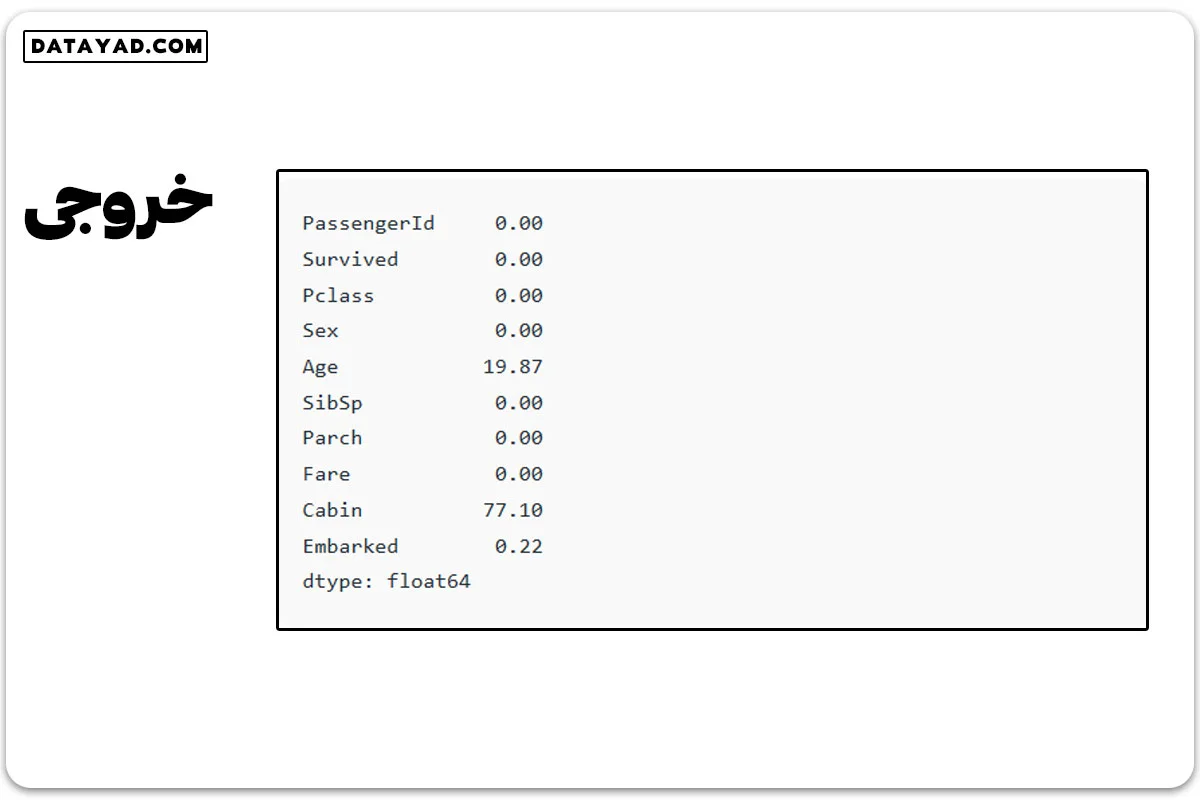
این دادههای گمشده نباید نادیده گرفته شوند؛ زیرا ممکن است این گمشدگیها نشاندهنده اطلاعاتی مهم باشند.
به عنوان مثال، گمشدن مقادیر در ستونهای خاص ممکن است مربوط به ویژگیهای مهمی باشد که نباید از دست بروند.
برخی از روشهای رایج برای کنار آمدن با دادههای گمشده عبارتاند از:
✔️ حذف موارد با دادههای گمشده
✔️ جایگزینی آنها با میانگین یا میانه.
df2 = df1.drop(columns='Cabin') df2.dropna(subset=['Embarked'], axis=0, inplace=True) df2.shape
خروجی: (889, 9)
با توجه به نتایج، ممکن است در برخی ستونها مقدار زیادی از دادهها گمشده باشد و در برخی دیگر کمتر. در مواردی که درصد دادههای گمشده بالا است، بهتر است آن ستون را حذف کرد. در مواردی که دادههای گمشده کم هستند، میتوان با استفاده از میانگین یا میانه آنها را جایگزین کرد.
در نهایت، همیشه باید به این نکته توجه کرد که روشهای جایگزینی ممکن است تأثیراتی روی دقت و کارایی مدلهای یادگیری ماشینی داشته باشند.
# Mean imputation df3 = df2.fillna(df2.Age.mean()) # Let's check the null values again df3.isnull().sum()

4- مدیریت نقاط پرت
نقاط پرت، مقادیر استثنایی هستند که بسیار از بقیه دادهها فاصله دارند. این مقادیر میتوانند تحلیل و کارایی مدل را مختل کنند. تکنیکهایی مثل خوشهبندی، درج یا تغییر مقیاس میتواند برای مواجهه با نقاط پرت مورد استفاده قرار گیرد.
برای شناسایی نقاط پرت، معمولاً از نمودار جعبهای استفاده میکنیم. این نمودار توزیع دادهها را به صورت گرافیکی نشان میدهد و اطلاعاتی مثل میانه، چارکها و نقاط پرت را معرفی میکند.
خط درون جعبه میانه است و جعبه خود نشاندهنده محدوده چارکها یا IQR است. سایهها به نقاطی کشیده میشوند که غیر از نقاط پرت هستند و در حدود 1.5 برابر IQR قرار دارند. نقاطی که فراتر از این سایهها هستند، نقاط پرت تلقی میشوند.
اکنون، نمودار جعبهای را برای دادههای ستون “سن” رسم میکنیم.
import matplotlib.pyplot as plt
plt.boxplot(df3['Age'], vert=False)
plt.ylabel('Variable')
plt.xlabel('Age')
plt.title('Box Plot')
plt.show()
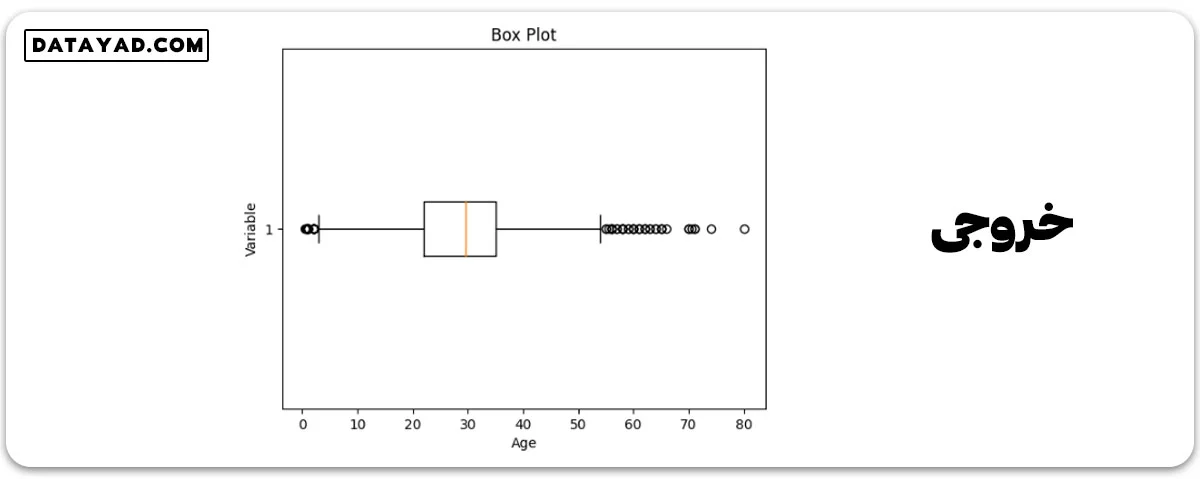
مشخص است که در نمودار جعبهای ما، دادههای ستون سن نقاط پرت دارد. مقادیری زیر 5 و بیشتر از 55 به عنوان نقاط پرت تلقی میشوند.
# calculate summary statistics
mean = df3['Age'].mean()
std = df3['Age'].std()
# Calculate the lower and upper bounds
lower_bound = mean - std*2
upper_bound = mean + std*2
print('Lower Bound :',lower_bound)
print('Upper Bound :',upper_bound)
# Drop the outliers
df4 = df3[(df3['Age'] >= lower_bound)
& (df3['Age'] <= upper_bound)]
خروجی:
Lower Bound : 3.705400107925648 Upper Bound : 55.578785285332785
به همین ترتیب، میتوانیم نقاط پرت سایر ستونها را نیز حذف کنیم.
5- تبدیل دادهها
تبدیل دادهها به تغییر شکل دادهها از یک حالت به حالت دیگر برای تحلیل بهتر اشاره دارد. میتوان از تکنیکهایی چون نرمال سازی، مقیاسبندی یا رمزگذاری برای این منظور استفاده کرد.
تصدیق و تایید دادهها
این مرحله شامل بررسی دقت و یکپارچگی دادهها با مقایسه با منابع خارجی یا دانش متخصصین است.
در زمینه یادگیری ماشین، ابتدا ویژگیهای مستقل و هدف را از هم جدا میکنیم. فقط ‘جنسیت’، ‘سن’، ‘SibSp’، ‘Parch’، ‘هزینه’ و ‘Embarked’ به عنوان ویژگیهای مستقل و ‘بقا’ را به عنوان متغیر هدف در نظر میگیریم، چرا که شناسه مسافر تأثیری بر نرخ بقا ندارد.
X = df3[['Pclass','Sex','Age', 'SibSp','Parch','Fare','Embarked']] Y = df3['Survived']
قالببندی داده
این مرحله به تبدیل داده به یک فرمت استاندارد اشاره دارد تا الگوریتمها یا مدلها بتوانند آن را به راحتی پردازش کنند. مثلاً، مقیاسبندی و نرمالسازی.
✔️ مقیاسبندی
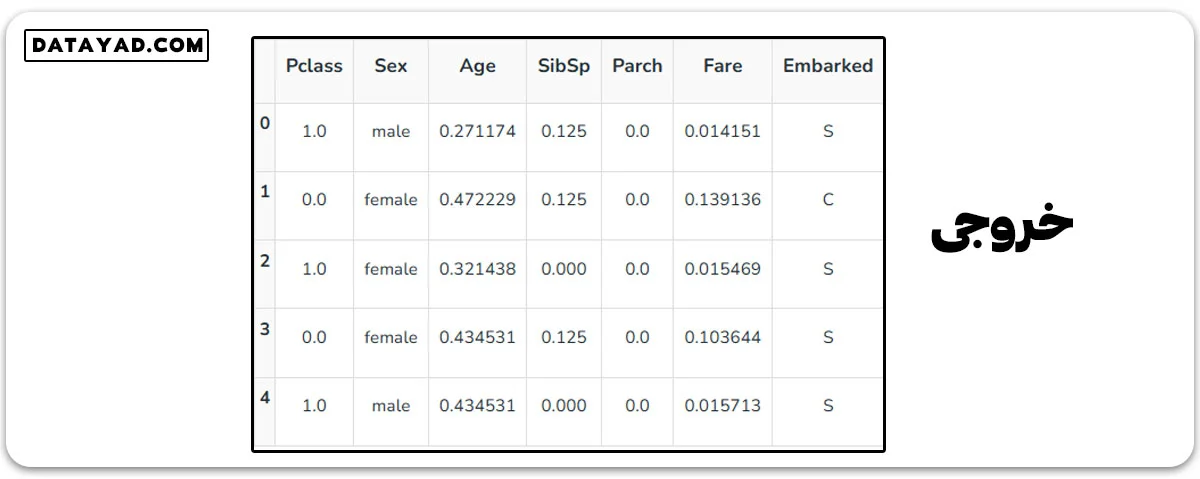
مقیاسبندی به تغییر مقادیر ویژگیها در یک محدوده خاص اشاره دارد. این فرآیند شکل اصلی توزیع را حفظ میکند. ویژهترین کاربرد آن زمانی است که ویژگیها مقیاسهای مختلفی دارند. روشهایی چون مقیاسبندی Min-Max و استانداردسازی (مقیاسبندی Z-score) معروفترین هستند.
مقیاسبندی Min-Max:
این روش مقادیر را در محدوده معینی، مثل 0 تا 1، قرار میدهد.
from sklearn.preprocessing import MinMaxScaler # initialising the MinMaxScaler scaler = MinMaxScaler(feature_range=(0, 1)) # Numerical columns num_col_ = [col for col in X.columns if X[col].dtype != 'object'] x1 = X # learning the statistical parameters for each of the data and transforming x1[num_col_] = scaler.fit_transform(x1[num_col_]) x1.head()
✔️ استانداردسازی
استانداردسازی، دادهها را به گونهای تغییر میدهد که میانگین آنها صفر و انحراف معیار آنها یک شود. این تبدیل برای الگوریتمهایی که توزیع گاوسی یا میانگین صفر و انحراف معیار یک مورد نیاز دارند، مناسب است.
Z = (X - μ) / σ
که در آن:
X = داده
μ = میانگین
σ = انحراف معیار
ابزارهای پاکسازی داده
- OpenRefine
- Trifacta Wrangler
- TIBCO Clarity
- Cloudingo
- IBM Infosphere Quality Stage
مزایای پاکسازی داده در یادگیری ماشین
- بهبود عملکرد مدل: با حذف خطاها و دادههای غیرمرتبط، مدل ماشین میتواند بهتر و با دقت بیشتری از دادهها یاد بگیرد.
- افزایش دقت: تمیزسازی داده به دقت و سازگاری بیشتری منجر میشود و در نتیجه، دقت مدل یادگیری ماشین را بالا میبرد.
- نمایش واضحتر داده: با تمیز کردن، دادهها به گونهای تغییر پیدا میکنند که روابط و الگوهای پنهان در آنها بهتر به نمایش درآید و این باعث میشود مدل به راحتی از دادهها یاد بگیرد.
- کیفیت بالاتر داده: پاکسازی، کیفیت دادهها را ارتقاء میدهد و اطمینان میدهد که مدلها بر روی دادههای باکیفیت آموزش داده شوند، که موجب پیشبینیهای دقیقتر میشود.
- تقویت امنیت داده: از طریق پاکسازی میتوان اطلاعات حساس یا خصوصی را شناسایی و حذف کرد و این به محافظت بهتر از دادهها و استفاده امنتر از آنها در یادگیری ماشین کمک میکند.
معایب پاکسازی داده در یادگیری ماشین
- زمانبر: پاکسازی دادهها، به ویژه در مورد دادههای بزرگ، میتواند خیلی طول بکشد.
- قابلیت خطا: در طی پاکسازی، خطر از دست دادن اطلاعات یا ایجاد خطاهای جدید وجود دارد.
- دید محدود به داده: پس از پاکسازی، ممکن است دادههایی که باقی میمانند، تصویر دقیقی از روابط و الگوهای اصلی ندهند.
- از دست رفتن اطلاعات: برخی از اطلاعات مهم ممکن است در طی فرآیند پاکسازی حذف شوند.
- نیاز به منابع و هزینه: پاکسازی میتواند هزینهبر باشد و منابع زیادی را مصرف کند.
- بیشبرازش: گاهی پاکسازی زیادی میتواند به مشکل بیشبرازش در مدل منجر شود، به این معنی که مدل فقط در مورد دادههای موجود به خوبی عمل میکند و در مواجهه با دادههای جدید، کارایی کمی دارد.
نتیجه گیری
ما چهار مرحله مختلف پاکسازی داده را بررسی کردیم تا دادهها را قابل اعتمادتر و مناسبتر برای تحلیل آماده کنیم. با به پایان رساندن مراحل پاکسازی داده به درستی، با یک مجموعه داده مستحکم و بدون خطرات رایج مواجه میشویم. این مرحله نباید با عجله طی شود زیرا در فرآیندهای بعدی بسیار مفید واقع میشود.
به طور خلاصه پاکسازی داده یک مرحله حیاتی در فرآیند علم داده است که شامل شناسایی و اصلاح خطاها، ناهماهنگیها و نادرستیهای موجود در دادهها است تا کیفیت و قابلیت استفاده آنها را افزایش دهد.
در این فرآیند از تکنیکهای متنوعی مانند مدیریت دادههای گمشده، کنترل ارقام پرت، تغییر شکل داده، ادغام داده، اعتبارسنجی و تایید داده و قالببندی داده استفاده میشود.
هدف از پاکسازی دادهها، آمادهسازی آنها برای تحلیل و تضمین دقت و قابلیت اعتماد نتایج حاصل از آن است.











