

در درس سی و پنجم از آموزش رایگان یادگیری ماشین با پایتون در سایت دیتایاد می خواهیم به بحث در مورد رگرسیون سافت مکس با استفاده از Tensorflow بپردازیم.
رگرسیون Softmax
رگرسیون سافتمکس (یا رگرسیون لجستیک چندمتغیره) تعمیمی از رگرسیون لجستیک است که در مواردی که میخواهیم چندین کلاس را در ستون هدف مدیریت کنیم، به کار میرود. در رگرسیون لجستیک دودویی، برچسبها دودویی بودند، به این معنی که برای مشاهده iام:
yi ∈ {0,1}
اما سناریویی را در نظر بگیرید که در آن نیاز داریم مشاهدهای از میان سه برچسب کلاس یا تعداد بیشتر را طبقهبندی کنیم. به عنوان مثال، در طبقهبندی ارقام در اینجا، برچسبهای ممکن عبارتند از:
yi ∈ {0,1,2,3,4,5,6,7,8,9}
در چنین مواردی، میتوانیم از رگرسیون Softmax استفاده کنیم.
لایه Softmax
آموزش مدل با استفاده از ارزشهای نمره دهی دشوار است، چرا که تفکیک آنها هنگام استفاده از الگوریتم گرادیان کاهشی برای کمینهسازی تابع هزینه مشکل است. برای این منظور، به تابعی نیاز داریم که نه تنها امتیازات لاجیت را نرمالسازی کند، بلکه تفکیک آنها را نیز آسان کند. برای تبدیل ماتریس امتیاز Z به احتمالات، از تابع سافتمکس استفاده میشود. برای بردار y، تابع سافتمکس S(y) به این شکل تعریف میشود:
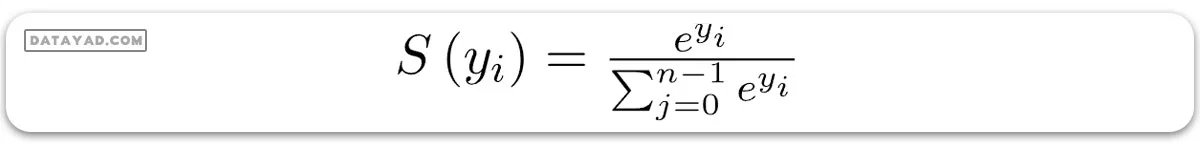
پس، تابع سافتمکس دو وظیفه را انجام میدهد:
1. تبدیل تمام امتیازات به احتمالات.
2. اطمینان از اینکه جمع تمام احتمالات برابر 1 باشد.
به خاطر داشته باشید که در رگرسیون لجستیک دودویی، از تابع سیگموئید برای همین هدف استفاده میکردیم. تابع سافتمکس در واقع گستردهای از تابع سیگموئید است. حالا، تابع سافتمکس احتمال اینکه نمونه آموزشی iام متعلق به کلاس j باشد را با توجه به بردار لاجیت Zi به این شکل محاسبه میکند:
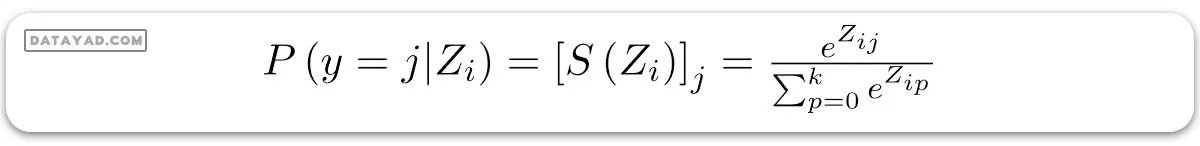
به زبان ساده، اگر Si را بردار احتمال سافتمکس برای مشاهده ith در نظر بگیریم، میتوانیم بنویسیم:
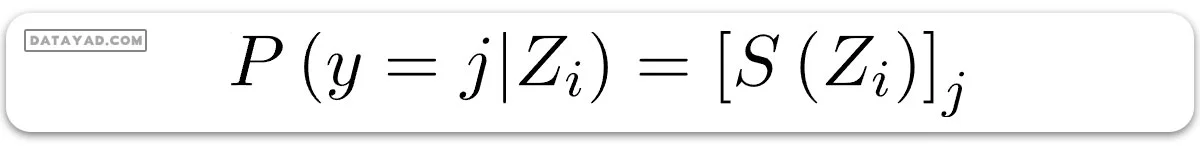
تابع هزینه
اکنون، نیاز داریم تابع هزینهای را تعریف کنیم که در آن، احتمالات بدست آمده از سافتمکس را با بردار هدف رمزگذاری شده به روش one-hot برای مشابهت مقایسه کنیم. در این راستا، از مفهوم آنتروپی متقاطع استفاده میکنیم.
آنتروپی متقاطع، که تابعی برای محاسبه فاصله است، احتمالات محاسبه شده توسط سافتمکس و ماتریس رمزگذاری شده one-hot را دریافت کرده و فاصله را محاسبه میکند. برای کلاسهای هدف صحیح، مقادیر فاصله کمتر و برای کلاسهای هدف نادرست، بیشتر خواهد بود.
آنتروپی متقاطع برای مشاهده iام با بردار احتمال سافتمکس Si و بردار هدف وانهات Ti به این صورت تعریف میشود:
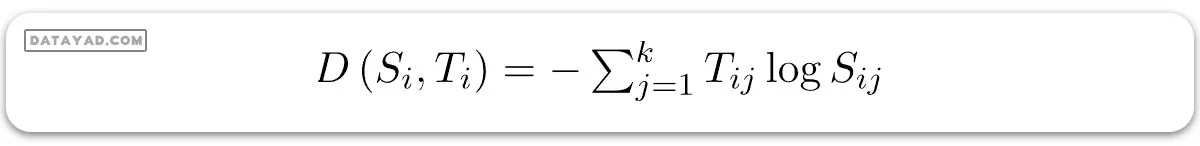
و اکنون، تابع هزینه J را میتوان به عنوان میانگین آنتروپی متقاطع تعریف کرد:
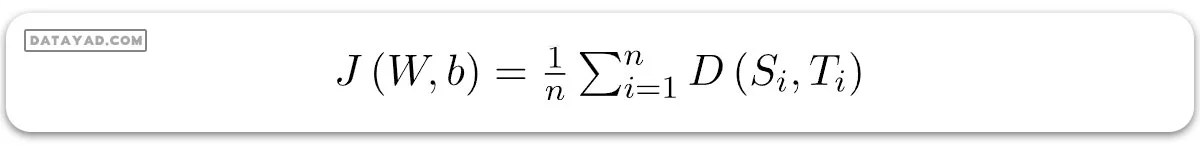
بیایید حالا به پیاده سازی رگرسیون سافت مکس با استفاده از Tensorflow روی دیتاست دیجیتهای دستنویس MNIST بپردازیم.
وارد کردن کتابخانهها و دیتاست
اول از همه، ملزومات را وارد میکنیم.
import tensorflow as tf import tensorflow.compat.v1 as tf1 import numpy as np import pandas as pd import matplotlib.pyplot as plt
TensorFlow به شما امکان میدهد تا دیتاست MNIST را به صورت خودکار دانلود و بخوانید. به کد زیر توجه کنید. این کد دیتاست MNIST را دانلود کرده و آن را به متغیرهای مورد نظر مانند آنچه در زیر انجام شده است اختصاص میدهد.
(X_train, Y_train),\
(X_val, Y_val) = tf.keras.datasets.mnist.load_data()
print("Shape of feature matrix:", X_train.shape)
print("Shape of target matrix:", Y_train.shape)
خروجی:
Shape of feature matrix: (60000, 28, 28) Shape of target matrix: (60000,)
اکنون، ما سعی میکنیم ساختار دیتاست را درک کنیم. دیتاست MNIST به دو بخش تقسیم شده است: ۶۰,۰۰۰ نقطه داده برای آموزش، و ۱۰,۰۰۰ نقطه داده برای اعتبارسنجی. هر تصویر ۲۸ پیکسل در ۲۸ پیکسل است. تعداد برچسبهای کلاس ۱۰ است.
# visualize data by plotting images fig, ax = plt.subplots(10, 10) for i in range(10): for j in range(10): k = np.random.randint(0,X_train.shape[0]) ax[i][j].imshow(X_train[k].reshape(28, 28), aspect='auto') plt.show()

حالا بیایید برخی از هایپرپارامترها را در اینجا تعریف کنیم تا بتوانیم آنها را در تمام notebook فقط از اینجا کنترل کنیم. همچنین، باید دادهها را تغییر شکل دهیم و آنها را به روش وانهات رمزگذاری کنیم تا نتایج مورد نظر خود را به دست آوریم.
num_features = 784 num_labels = 10 learning_rate = 0.05 batch_size = 128 num_steps = 5001 # input data train_dataset = X_train.reshape(-1, 784) train_labels = pd.get_dummies(Y_train).values valid_dataset = X_val.reshape(-1, 784) valid_labels = pd.get_dummies(Y_val).values
گراف محاسباتی
اکنون، ما یک گراف محاسباتی ایجاد میکنیم. تعریف یک گراف محاسباتی به ما کمک میکند تا قابلیتهای EagerTensor که توسط TensorFlow ارائه شده است را به دست آوریم.
# initialize a tensorflow graph graph = tf.Graph() with graph.as_default(): # Inputs tf_train_dataset = tf1.placeholder(tf.float32, shape=(batch_size, num_features)) tf_train_labels = tf1.placeholder(tf.float32, shape=(batch_size, num_labels)) tf_valid_dataset = tf.constant(valid_dataset) # Variables. weights = tf.Variable( tf.random.truncated_normal([num_features, num_labels])) biases = tf.Variable(tf.zeros([num_labels])) # Training computation. logits = tf.matmul(tf_train_dataset, weights) + biases loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( labels=tf_train_labels, logits=logits)) # Optimizer. optimizer = tf1.train.GradientDescentOptimizer( learning_rate).minimize(loss) # Predictions for the training, validation, and test data. train_prediction = tf.nn.softmax(logits) tf_valid_dataset = tf.cast(tf_valid_dataset, tf.float32) valid_prediction = tf.nn.softmax( tf.matmul(tf_valid_dataset, weights) + biases)
اجرای گراف محاسباتی
از آنجایی که ما قبلاً گراف محاسباتی را ساختهایم، حالا زمان آن رسیده که آن را از طریق یک جلسه (session) اجرا کنیم.
# utility function to calculate accuracy def accuracy(predictions, labels): correctly_predicted = np.sum( np.argmax(predictions, 1) == np.argmax(labels, 1)) acc = (100.0 * correctly_predicted) / predictions.shape[0] return acc
ما از تابع کمکی بالا برای محاسبه دقت مدل همزمان با پیشرفت آموزش استفاده خواهیم کرد.
with tf1.Session(graph=graph) as session:
# initialize weights and biases
tf1.global_variables_initializer().run()
print("Initialized")
for step in range(num_steps):
# pick a randomized offset
offset = np.random.randint(0, train_labels.shape[0] - batch_size - 1)
# Generate a minibatch.
batch_data = train_dataset[offset:(offset + batch_size), :]
batch_labels = train_labels[offset:(offset + batch_size), :]
# Prepare the feed dict
feed_dict = {tf_train_dataset: batch_data,
tf_train_labels: batch_labels}
# run one step of computation
_, l, predictions = session.run([optimizer, loss, train_prediction],
feed_dict=feed_dict)
if (step % 500 == 0):
print("Minibatch loss at step {0}: {1}".format(step, l))
print("Minibatch accuracy: {:.1f}%".format(
accuracy(predictions, batch_labels)))
print("Validation accuracy: {:.1f}%".format(
accuracy(valid_prediction.eval(), valid_labels)))
خروجی:
Initialized Minibatch loss at step 0: 3185.3974609375 Minibatch accuracy: 7.0% Validation accuracy: 21.1% Minibatch loss at step 500: 619.6030883789062 Minibatch accuracy: 86.7% Validation accuracy: 89.0% Minibatch loss at step 1000: 247.22283935546875 Minibatch accuracy: 93.8% Validation accuracy: 85.7% Minibatch loss at step 1500: 2945.78662109375 Minibatch accuracy: 78.9% Validation accuracy: 83.6% Minibatch loss at step 2000: 337.13922119140625 Minibatch accuracy: 94.5% Validation accuracy: 89.0% Minibatch loss at step 2500: 409.4652404785156 Minibatch accuracy: 89.8% Validation accuracy: 90.6% Minibatch loss at step 3000: 1077.618408203125 Minibatch accuracy: 84.4% Validation accuracy: 90.3% Minibatch loss at step 3500: 986.0247802734375 Minibatch accuracy: 80.5% Validation accuracy: 85.9% Minibatch loss at step 4000: 467.134521484375 Minibatch accuracy: 89.8% Validation accuracy: 85.1% Minibatch loss at step 4500: 1007.259033203125 Minibatch accuracy: 87.5% Validation accuracy: 87.5% Minibatch loss at step 5000: 342.13690185546875 Minibatch accuracy: 94.5% Validation accuracy: 89.6%
نکات مهمی که باید به خاطر داشت:
– در هر تکرار، یک دسته کوچک (minibatch) با انتخاب یک مقدار افست تصادفی با استفاده از روش np.random.randint انتخاب میشود.
– برای تغذیه متغیرهای جایگزین (placeholders) tf_train_dataset و tf_train_labels، ما یک feed_dict به این شکل ایجاد میکنیم:
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
هرچند بسیاری از قابلیتهایی که ما در اینجا از ابتدا پیادهسازی کردهایم به صورت خودکار توسط TensorFlow ارائه میشوند، اما آنها را برای درک بهتر فرمولهای ریاضی که در کلاسیفایر رگرسیون سافتمکس استفاده میشوند، از ابتدا پیادهسازی کردهایم.





