

رگرسیون جنگل تصادفی یک تکنیک چندمنظوره یادگیری ماشین برای پیشبینی ارقام عددی است. این تکنیک با ترکیب پیشبینیهای چند درخت تصمیم برای کاهش اورفیتینگ و بهبود دقت استفاده میشود. کتابخانههای یادگیری ماشین پایتون این امکان را فراهم کردهاند که این رویکرد را پیادهسازی و بهینهسازی کنیم.
مقایسه جنگل تصادفی با سایر الگوریتمهای یادگیری ماشین
مدل جنگل تصادفی به دلیل توانایی بالا در افزایش دقت و انعطاف پذیری، در مقایسه با بسیاری از الگوریتمهای یادگیری ماشین برتری دارد. در این بخش، این مدل را با الگوریتمهایی مانند درخت تصمیم، ماشین بردار پشتیبان (SVM) و شبکههای عصبی مقایسه میکنیم تا نقاط قوت و ضعف آن را بهتر بشناسید.
جدول مقایسهای
| ویژگیها | جنگل تصادفی (Random Forest) | درخت تصمیم (Decision Tree) | ماشین بردار پشتیبان (SVM) | شبکه عصبی (Neural Network) |
| دقت پیشبینی | بالا به دلیل ترکیب چندین درخت | متوسط، حساس به بیشبرازش | بالا در دادههای کوچک | بسیار بالا در دادههای بزرگ |
| سرعت آموزش | متوسط تا کند (بسته به تعداد درختها) | سریع | کند در دادههای بزرگ | کند، بهویژه با لایههای زیاد |
| مقاومت به بیشبرازش | بالا به دلیل بگینگ و تصادفی بودن | پایین | متوسط، وابسته به تنظیم پارامترها | پایین بدون تنظیم مناسب |
| قابلیت تفسیر | متوسط (کمتر از درخت تصمیم) | بالا | پایین | بسیار پایین |
| نیاز به پیشپردازش داده | کم | کم | زیاد (نیاز به نرمالسازی) | زیاد (نیاز به نرمالسازی و تنظیم) |
همانطور که در جدول مشاهده میکنید، مدل جنگل تصادفی در زمینههایی مانند مقاومت به بیشبرازش و افزایش دقت عملکردی برجسته دارد. این مدل بهویژه در مسائل طبقهبندی و رگرسیون که نیاز به تعادل بین دقت و پایداری دارند، انتخابی عالی است. در مقابل، SVM در دادههای کوچکتر و شبکههای عصبی در دادههای بزرگتر میتوانند بهتر عمل کنند، اما نیاز به تنظیمات پیچیدهتر و پیشپردازش بیشتری دارند.
برای مثال، در یک پروژه الگوریتم رگرسیون برای پیشبینی قیمت خانه، مدل جنگل تصادفی میتواند با حداقل تنظیمات، نتایجی دقیق و قابل اعتماد ارائه دهد، در حالی که شبکههای عصبی به دادههای بیشتر و زمان آموزش طولانیتری نیاز دارند. برای اطلاعات بیشتر، به مقاله الگوریتمهای یادگیری ماشین در دیتایاد سر بزنید.
یادگیری جمعی
یادگیری جمعی یک تکنیک یادگیری ماشین است که پیشبینیها را از چندین مدل ترکیب میکند تا یک پیشبینی دقیقتر و پایدارتر ایجاد شود. این رویکرد از هوش جمعی مدلهای مختلف برای بهبود عملکرد کلی سیستم یادگیری استفاده میکند.
انواع روشهای یادگیری جمعی
تعدادی از انواع روشهای یادگیری جمعی عبارتند از:
- بگینگ (Bootstrap Aggregating): این روش شامل آموزش چندین مدل بر روی زیرمجموعههای تصادفی از دادههای آموزش میشود. پیشبینیهای حاصل از مدلهای فردی سپس ترکیب میشوند، که معمولاً با میانگینگیری است.
- بوستینگ: این روش شامل آموزش یک دنباله از مدلهاست، جایی که مدل بعدی بر روی خطاهای مدل قبلی تمرکز میکند. پیشبینیها با استفاده از یک روش رایدهی وزندار ترکیب میشوند.
- استکینگ: این روش شامل استفاده از پیشبینیهای یک مجموعه از مدلها به عنوان ویژگیهای ورودی برای یک مدل دیگر است. پیشبینی نهایی توسط مدل مرحله دوم انجام میشود.
جنگل تصادفی
جنگل تصادفی یک روش یادگیری جمعی است که پیشبینیها را از چندین درخت تصمیم ترکیب میکند تا یک پیشبینی دقیقتر و پایدارتر ایجاد شود. این یک الگوریتم یادگیری نظارتی است که میتواند برای وظایف طبقهبندی و رگرسیون هر دو استفاده شود.
هر درخت تصمیم واریانس بالایی دارد، اما زمانی که همه آنها را به صورت موازی ترکیب میکنیم، واریانس نهایی کاهش مییابد چرا که هر درخت تصمیم به طور کامل بر روی دادههای نمونه آموزش میشود و به همین دلیل خروجی به یک درخت تصمیم وابسته نیست، بلکه به چندین درخت تصمیم بستگی دارد. در مسئله طبقهبندی، خروجی نهایی با استفاده از یک طبقهبند رایگیری اکثریت تعیین میشود. در مسئله رگرسیون، خروجی نهایی میانگین تمام خروجیهاست. این قسمت به نام انجمنبندی (Aggregation) معروف است.
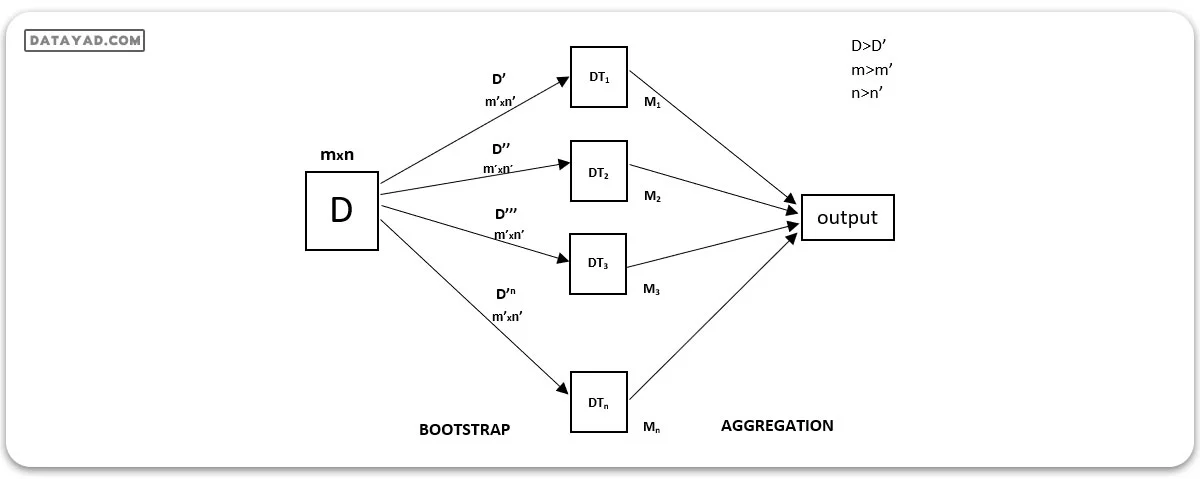
Random Forest Regression, در یادگیری ماشین، یک تکنیک جمعی است که قابلیت انجام وظایف رگرسیون و طبقهبندی را با استفاده از چندین درخت تصمیم و یک تکنیک به نام بوت استرپ و انجمنبندی (Bootstrap and Aggregation)، که به طور معمول به عنوان بگینگ شناخته میشود، دارا میباشد. ایده اصلی در پشت این تکنیک، به جای اعتماد به درختهای تصمیم فردی، ترکیب چندین درخت تصمیم در تعیین خروجی نهایی مطرح است.
در Random Forest، مدلهای اولیه چندین درخت تصمیم هستند. ما به صورت تصادفی نمونهبرداری از ردیفها و ویژگیها از مجموعه داده انجام میدهیم و برای هر مدل مجموعههای داده نمونه را شکل میدهیم. این قسمت به نام بوت استرپ است.
تقابل با تکنیک رگرسیون جنگل تصادفی نیازمند آشنایی به سایر تکنیکهای یادگیری ماشین است.
- یک سوال یا داده خاص مشخص کرده و منبع را برای تعیین داده مورد نیاز بدست آورید.
- اطمینان حاصل کنید که داده در یک فرمت قابل دسترس قرار دارد، در غیر اینصورت آن را به فرمت مورد نیاز تبدیل کنید.
- تمام نقاط نادرست و نقاط داده ای که ممکن است برای دستیابی به داده مورد نیاز لازم باشد را مشخص کنید.
- یک مدل یادگیری ماشین ایجاد کنید.
- مدل پایه را که میخواهید به آن برسید تعیین کنید.
- مدل یادگیری ماشین را آموزش دهید.
- بررسی نتایج مدل با دادههای آزمایشی ارائه دهید.
- حالا عملکرد هر دو گروه داده آزمایشی و داده پیشبینی شده از مدل را با یکدیگر مقایسه کنید.
- اگر نتایج انتظارات شما را برآورده نمیکند، میتوانید مدل خود را بهبود دهید یا دادههای خود را بهروز رسانی کنید یا از یک تکنیک دیگر در مدلسازی داده استفاده کنید.
- در این مرحله، دادههای بهدست آمده را تفسیر کرده و گزارش دهید.
در دنیای یادگیری ماشین، انتخاب الگوریتمی که هم دقیق باشد و هم در برابر پیچیدگیهای دادههای واقعی مقاوم عمل کند، از اهمیت بالایی برخوردار است. مدل جنگل تصادفی (Random Forest) یکی از قدرتمندترین و محبوبترین الگوریتمهای یادگیری ماشین است که به دلیل انعطاف پذیری و کاراییاش در حل مسائل متنوع، جایگاه ویژهای در میان متخصصان داده و هوش مصنوعی پیدا کرده است. این مدل نه تنها در طبقهبندی و رگرسیون عملکردی عالی ارائه میدهد، بلکه با افزایش دقت و کاهش خطر بیشبرازش، به ابزاری کلیدی در تحلیل دادههای بزرگ تبدیل شده است.
در ادامه، به بررسی جامع مدل جنگل تصادفی میپردازیم و شما را با مفاهیم اصلی، تفاوتهای آن با درخت تصمیم، مقایسهاش با سایر الگوریتمها، چالشها و محدودیتها، و بهترین روشهای بهینهسازی آن آشنا میکنیم. برای اطلاعات بیشتر درباره الگوریتمهای یادگیری ماشین، میتوانید به مقاله مرتبط در دیتایاد مراجعه کنید.
تفاوت جنگل تصادفی با درخت تصمیم
برای فهم بهتر مدل جنگل تصادفی، ابتدا باید با مفهوم درخت تصمیم آشنا شویم. درخت تصمیم یک الگوریتم ساده است که با طرح سوالات متوالی، دادهها را به دستههای مختلف تقسیم میکند. هر گره در این ساختار یک ویژگی را نشان میدهد، هر شاخه یک تصمیم را مشخص میکند و برگها نتیجه نهایی را ارائه میدهند. اما این الگوریتم با وجود سادگی، محدودیتهایی دارد. یکی از بزرگترین مشکلات درخت تصمیم، حساسیت آن به بیش برازش است که باعث میشود مدل بیش از حد به دادههای آموزشی وابسته شود و در دادههای جدید عملکرد ضعیفی داشته باشد.
مدل جنگل تصادفی برای غلبه بر این مشکل طراحی شده است. این مدل از رویکرد یادگیری جمعی استفاده میکند و شامل چندین درخت تصمیم است که هر کدام روی زیرمجموعهای تصادفی از دادهها و ویژگیها آموزش میبینند. پیشبینی نهایی از طریق ترکیب نتایج این درختها (مثلاً رأیگیری اکثریت در طبقهبندی یا میانگینگیری در رگرسیون) انجام میشود.
به نقل از IBM : “جنگل تصادفی با ایجاد چندین درخت تصمیم و ترکیب نتایج آنها، دقت پیشبینی را افزایش میدهد و از بیشبرازش جلوگیری میکند.”
بنابراین، تفاوت اصلی مدل جنگل تصادفی با درخت تصمیم در استفاده از چندین درخت و تصادفی بودن انتخاب دادهها و ویژگیهاست. این ویژگیها باعث میشوند مدل جنگل تصادفی در مقایسه با یک درخت تصمیم منفرد، دقت و پایداری بیشتری داشته باشد و در مسائل پیچیدهتر عملکرد بهتری از خود نشان دهد.
رگرسیون جنگل تصادفی در پایتون
در مثال زیر، از یک تکنیک نمونهبرداری مشابه استفاده خواهیم کرد. پیادهسازی نمونه گام به گام یک رگرسیون جنگل تصادفی بر روی مجموعه داده ای آورده شده است.
کتابخانههای پایتون به ما این امکان را میدهند که به راحتی با یک خط کد دادهها را کنترل کرده و وظایف عادی و پیچیده را اجرا کنیم.
– Pandas: این کتابخانه به ما کمک میکند تا یک فریم داده را در یک آرایه دوبعدی بارگیری کنیم و دارای توابع متعددی برای انجام وظایف تحلیلی در یک گام است.
– Numpy: آرایههای Numpy بسیار سریع هستند و میتوانند محاسبات بزرگ را در زمان کوتاهی انجام دهند.
– Matplotlib/Seaborn: این کتابخانه برای ترسیم نمودارها استفاده میشود.
– Sklearn: این ماژول شامل چندین کتابخانه با توابع پیشپردازش داده تا توسعه و ارزیابی مدل است.
– RandomForestRegressor: این مدل رگرسیون بر اساس مدل جنگل تصادفی یا یادگیری جمعی است که در این مقاله از کتابخانه sklearn استفاده خواهیم کرد.
– sklearn: این کتابخانه مرکزی برای یادگیری ماشین در پایتون است. این ابزارها را برای پیشپردازش، مدلسازی، ارزیابی و استقرار مدلهای یادگیری ماشین فراهم میکند.
– LabelEncoder: این کلاس برای تبدیل دادههای دستهای به مقادیر عددی استفاده میشود.
– KNNImputer: این کلاس برای تکمیل مقادیر گمشده در مجموعه داده با استفاده از رویکرد همسایههای نزدیک k استفاده میشود.
– train_test_split: این تابع برای تقسیم یک مجموعه داده به مجموعههای آموزش و آزمایش استفاده میشود.
– StandardScaler: این کلاس برای استانداردسازی ویژگیها با حذف میانگین و مقیاس داده به واریانس یکا استفاده میشود.
– f1_score: این تابع برای ارزیابی عملکرد یک مدل طبقهبندی با استفاده از امتیاز F1 استفاده میشود.
– RandomForestRegressor: این کلاس برای آموزش یک مدل رگرسیون جنگل تصادفی استفاده میشود.
– cross_val_score: این تابع برای انجام اعتبارسنجی متقاطع k-fold برای ارزیابی عملکرد یک مدل استفاده میشود.
گام ۱: وارد کردن کتابخانهها
در اینجا تمام کتابخانههای مورد نیاز وارد میشوند
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
import warnings
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import KNNImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
warnings.filterwarnings('ignore')
گام ۲: وارد کردن مجموعه داده
حالا مجموعه داده برای مدیریت بهتر داده و بهرهمندی از توابع کارآمد برای انجام وظایف پیچیده با یک بار کد بهشکل فریم داده Pandas بارگیری میشود.
df= pd.read_csv('Salaries.csv')
print(df)
خروجی:
Position Level Salary 0 Business Analyst 1 45000 1 Junior Consultant 2 50000 2 Senior Consultant 3 60000 3 Manager 4 80000 4 Country Manager 5 110000 5 Region Manager 6 150000 6 Partner 7 200000 7 Senior Partner 8 300000 8 C-level 9 500000 9 CEO 10 1000000
در اینجا متد .info() یک مرور سریع از ساختار، انواع داده و مصرف حافظه مجموعه داده را ارائه میدهد.
df.info()
خروجی:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10 entries, 0 to 9 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Position 10 non-null object 1 Level 10 non-null int64 2 Salary 10 non-null int64 dtypes: int64(2), object(1) memory usage: 372.0+ bytes
گام ۳: آمادهسازی داده
در اینجا کد دو زیرمجموعه از دادهها را از مجموعه داده استخراج کرده و در متغیرهای جداگانه ذخیره میکند.
– استخراج ویژگیها: این ویژگیها را از فریم داده استخراج کرده و در متغیری به نام X ذخیره میکند.
– استخراج متغیر هدف: این متغیر هدف را از فریم داده استخراج کرده و در یک متغیر به نام y ذخیره میکند.
# Assuming df is your DataFrame X = df.iloc[:,1:2].values#features y = df.iloc[:,2].values# Target variable
گام ۴: مدل رگرسیون جنگل تصادفی
این کد دادههای دستهای را با ترکیب آنها به صورت عددی پردازش میکند، دادههای پردازش شده را با دادههای عددی ترکیب میکند و یک مدل رگرسیون جنگل تصادفی با استفاده از داده آمادهشده آموزش میدهد.
import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import LabelEncoder Check for and handle categorical variables label_encoder = LabelEncoder() x_categorical = df.select_dtypes(include=['object']).apply(label_encoder.fit_transform) x_numerical = df.select_dtypes(exclude=['object']).values x = pd.concat([pd.DataFrame(x_numerical), x_categorical], axis=1).values # Fitting Random Forest Regression to the dataset regressor = RandomForestRegressor(n_estimators=10, random_state=0, oob_score=True) # Fit the regressor with x and y data regressor.fit(x, y)
گام ۵: انجام پیشبینی و ارزیابی
این کد مدل آموزش دیده را ارزیابی میکند:
- نمره out-of-bag (OOB) که عملکرد عمومی مدل را تخمین میزند.
- پیشبینیها را با استفاده از مدل آموزش دیده انجام میدهد و آنها را در آرایه ‘پیشبینی’ ذخیره میکند.
- عملکرد مدل را با استفاده از معیارهای میانگین مربعات خطا (MSE) و (R2) ارزیابی میکند.
نمره Out-of-Bag در RandomForest
نمره Out-of-Bag یا همان نمره OOB یک نوع تکنیک اعتبارسنجی است که به طور اصلی در الگوریتمهای بگینگ برای اعتبارسنجی استفاده میشود. در اینجا، یک بخش کوچک از دادههای اعتبارسنجی از جریان اصلی داده گرفته میشود و پیشبینیها بر روی دادههای اعتبارسنجی خاص انجام میشود و با سایر نتایج مقایسه میشود.
مزیت اصلی که نمره OOB ارائه میدهد این است که در اینجا دادههای اعتبارسنجی توسط الگوریتم بگینگ دیده نمیشوند و به همین دلیل نتایج در نمره OOB نتایج واقعی هستند که عملکرد واقعی الگوریتم بگینگ را نشان میدهند.
برای گرفتن نمره OOB از الگوریتم خاص جنگل تصادفی، نیاز است که مقدار “True” را برای پارامتر OOB_Score در الگوریتم تنظیم کنید.
# Evaluating the model
from sklearn.metrics import mean_squared_error, r2_score
# Access the OOB Score
oob_score = regressor.oob_score_
print(f'Out-of-Bag Score: {oob_score}')
# Making predictions on the same data or new data
predictions = regressor.predict(x)
# Evaluating the model
mse = mean_squared_error(y, predictions)
print(f'Mean Squared Error: {mse}')
r2 = r2_score(y, predictions)
print(f'R-squared: {r2}')
خروجی:
Out-of-Bag Score: 0.644879832593859 Mean Squared Error: 2647325000.0 R-squared: 0.9671801245316117
گام ۶: تصویرسازی
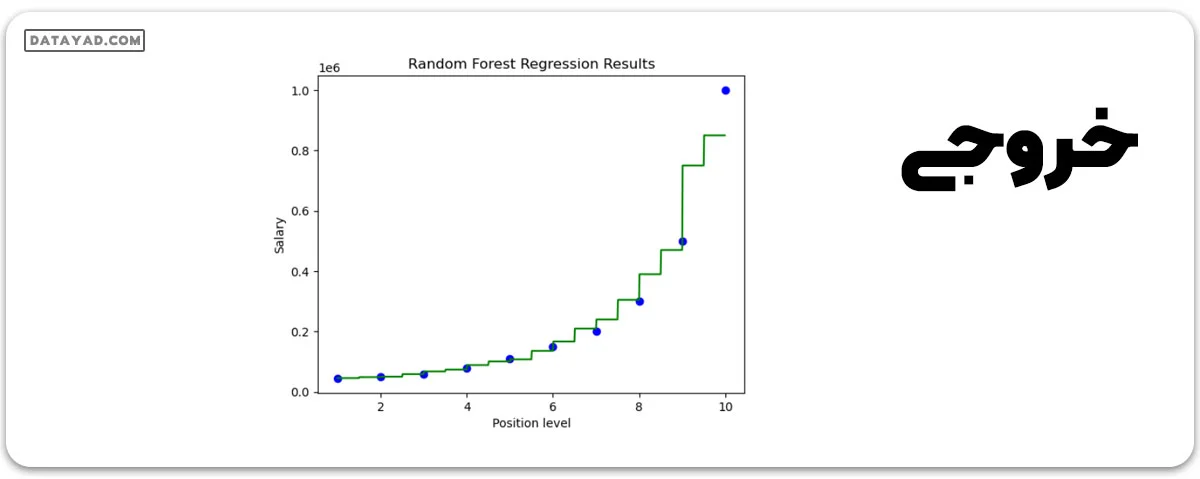
حالا نتایج به دست آمده از استفاده از مدل رگرسیون جنگل تصادفی را در مجموعه داده حقوقمان تصویرسازی میکنیم.
- شبکهای از نقاط پیشبینی ایجاد میکند که محدوده مقادیر ویژگی را پوشش میدهد.
- نقاط داده واقعی را به عنوان نقاط پراکندگی آبی نشان میدهد.
- مقادیر پیشبینی شده برای شبکه پیشبینی را به عنوان یک خط سبز نشان میدهد.
- برچسبها و عنوانی به نمودار اضافه میشود تا درک بهتری ایجاد شود.
import numpy as np
X_grid = np.arange(min(X),max(X),0.01)
X_grid = X_grid.reshape(len(X_grid),1)
plt.scatter(X,y, color='blue') #plotting real points
plt.plot(X_grid, regressor.predict(X_grid),color='green') #plotting for predict points
plt.title("Random Forest Regression Results")
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
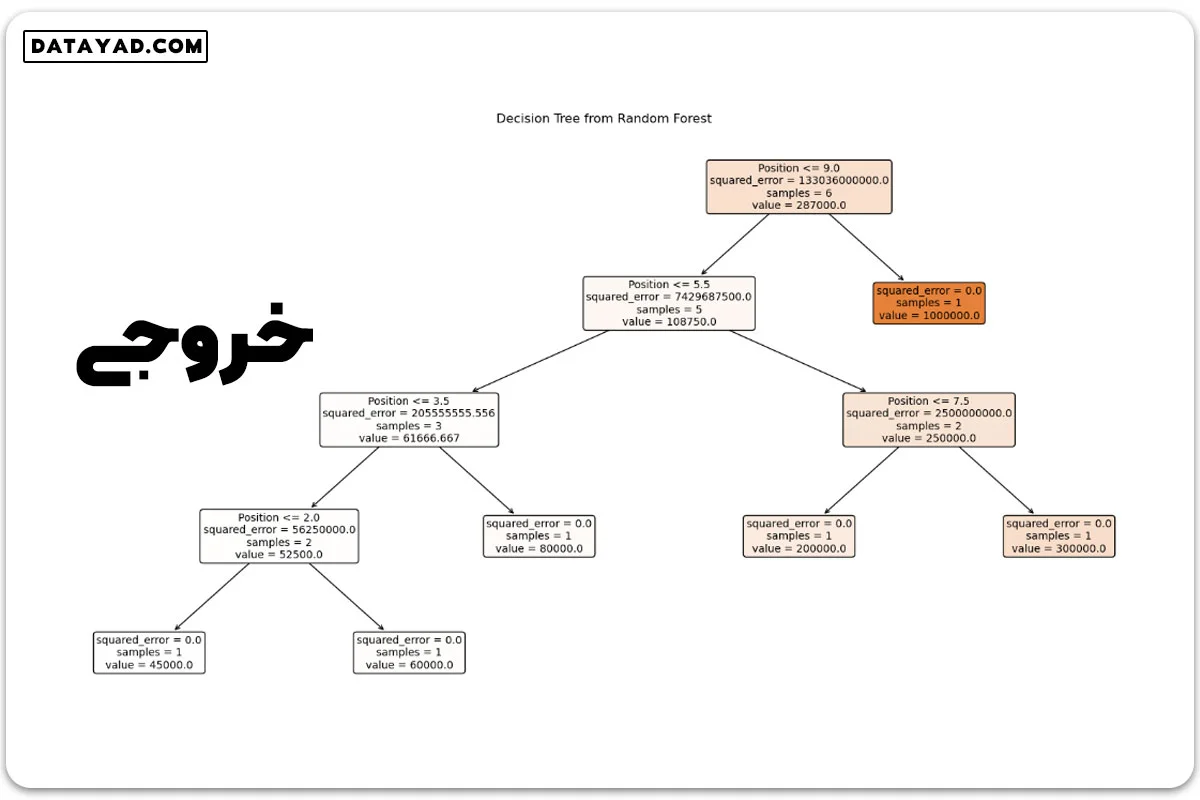
گام ۷: تصویرسازی یک درخت تصمیم از مدل جنگل تصادفی
در این مرحله، کد یکی از درختهای تصمیم آموزش دیده از مدل جنگل تصادفی را تصویرسازی میکند. این کار با ارائه یک تصویر از فرآیند تصمیمگیری در یک درخت تکی درون انجمن، برای ما تصویر زندهای از چگونگی عملکرد یک درخت در این مدل جنگل تصادفی ارائه میدهد.
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# Assuming regressor is your trained Random Forest model
# Pick one tree from the forest, e.g., the first tree (index 0)
tree_to_plot = regressor.estimators_[0]
# Plot the decision tree
plt.figure(figsize=(20, 10))
plot_tree(tree_to_plot, feature_names=df.columns.tolist(), filled=True, rounded=True, fontsize=10)
plt.title("Decision Tree from Random Forest")
plt.show()
بهترین تنظیمات برای بهینهسازی مدل جنگل تصادفی
برای دستیابی به بهترین عملکرد از مدل جنگل تصادفی، تنظیم دقیق پارامترهای آن حیاتی است. در این بخش، مهمترین پارامترها و نحوه بهینهسازی آنها را بررسی میکنیم.
- تعداد درختها (n_estimators)
تعداد درختها تأثیر مستقیمی بر دقت مدل جنگل تصادفی دارد. افزایش تعداد درختها معمولاً به افزایش دقت منجر میشود، اما پس از یک حد مشخص، تأثیر آن کاهش یافته و فقط زمان پردازش را بالا میبرد. برای اکثر پروژهها، انتخاب 100 تا 500 درخت تعادل مناسبی بین دقت و سرعت ایجاد میکند. آزمایش مقادیر مختلف میتواند به شما کمک کند تا بهترین تعداد را پیدا کنید.
- عمق درختها (max_depth)
عمق درختها تعیینکننده پیچیدگی مدل است. درختهای عمیقتر الگوهای پیچیدهتری را یاد میگیرند، اما خطر بیشبرازش را افزایش میدهند. محدود کردن عمق (مثلاً بین 10 تا 20) یا استفاده از تکنیکهای هرس کردن میتواند این مشکل را کنترل کند. در مسائل رگرسیون با دادههای پیچیده، ممکن است به عمق بیشتری نیاز باشد.
- حداقل نمونهها برای تقسیم (min_samples_split)
این پارامتر مشخص میکند که یک گره برای تقسیم به چند نمونه حداقل نیاز دارد. مقادیر بالاتر (مثلاً 5 یا 10) از بیشبرازش جلوگیری میکنند، در حالی که مقادیر پایینتر (مثلاً 2) جزئیات بیشتری را پوشش میدهند. برای دادههای پرنویز، مقادیر بالاتر توصیه میشود.
- تعداد ویژگیها در هر تقسیم (max_features)
این پارامتر تعداد ویژگیهایی را که بهصورت تصادفی در هر تقسیم انتخاب میشوند، تعیین میکند. انتخاب زیرمجموعهای از ویژگیها همبستگی بین درختها را کاهش داده و عملکرد مدل جنگل تصادفی را بهبود میبخشد. گزینههایی مانند “auto” (جذر تعداد ویژگیها) یا “log2” معمولاً مناسب هستند.
با تنظیم این پارامترها، میتوانید مدل جنگل تصادفی را برای پروژههای مختلف بهینه کنید. برای یادگیری عملی این تکنیکها، در دورههای برنامهنویسی دیتایاد شرکت کنید.
مدل جنگل تصادفی یکی از بهترین الگوریتمهای یادگیری ماشین است که در مسائل طبقهبندی و رگرسیون و به ویژه الگوریتم رگرسیون عملکردی بی نظیر دارد. این مدل با ترکیب چندین درخت تصمیم، مشکلاتی مانند بیش برازش را حل کرده و دقتی بالا ارائه میدهد. در این مقاله، تفاوتهای آن با درخت تصمیم، مقایسهاش با سایر الگوریتمها، چالشهایی مانند نیاز به قدرت پردازشی بالا، حساسیت به نویز و مشکل تفسیرپذیری و بهترین تنظیمات برای بهینه سازی را بررسی کردیم.
اگر میخواهید از مدل جنگل تصادفی در پروژههای خود استفاده کنید، با تنظیم پارامترها و پیشپردازش مناسب دادهها، میتوانید بهترین نتایج را به دست آورید. این الگوریتم با توانایی افزایش دقت، ابزاری قدرتمند برای حل مسائل پیچیده است. اگر میخواهید یادگیری ماشین را حرفهایتر دنبال کنید، در دورههای آموزشی دیتایاد شرکت کنید! برای اطلاعات بیشتر به DataYad.com مراجعه کنید.
کاربردهای رگرسیون جنگل تصادفی
رگرسیون جنگل تصادفی در حل مشکلات واقعی متنوعی نقش دارد که شامل موارد زیر میشود:
– پیشبینی مقادیر عددی مستمر: پیشبینی قیمت خانه، قیمت سهام یا ارزش عمر مشتری.
– شناسایی عوامل خطر: کشف عوامل خطر برای بیماریها، بحرانهای مالی یا سایر رویدادهای منفی.
– مدیریت دادههای با ابعاد بالا: تجزیه و تحلیل مجموعههای داده با تعداد زیادی ویژگی ورودی.
– ضبط روابط پیچیده: مدلسازی روابط پیچیده بین ویژگیهای ورودی و متغیر هدف.
مزایای رگرسیون جنگل تصادفی
– از نظر استفاده آسان و حساسیت کمتر نسبت به دادههای آموزش، با درخت تصمیم بهتر عمل میکند.
– دقت بالاتری نسبت به الگوریتم درخت تصمیم دارد.
– در مدیریت مجموعههای داده بزرگ با ویژگیهای زیاد، مؤثر است.
– قادر به مدیریت دادههای گمشده، دادههای پرت، و ویژگیهای نویزی است.
معایب رگرسیون جنگل تصادفی
– ممکن است مدل بهسختی تفسیر شود.
– این الگوریتم ممکن است نیاز به مهارتهای خاص این حوزه داشته باشد تا پارامترهای مناسب مانند تعداد درخت تصمیم، حداکثر عمق هر درخت و تعداد ویژگیهایی که در هر تقسیم مدنظر قرار گیرند، را انتخاب کنید.
– از نظر محاسباتی سنگین است، به ویژه برای مجموعههای داده بزرگ.
– ممکن است اگر مدل خیلی پیچیده یا تعداد درختها زیاد باشد، اورفیت شود.
چالشها و محدودیتهای مدل جنگل تصادفی
با وجود مزایای فراوان، مدل جنگل تصادفی نیز محدودیتهایی دارد که باید در کاربرد آن مدنظر قرار گیرند. در ادامه، سه چالش اصلی این مدل را بررسی میکنیم.
نیاز به قدرت پردازشی بالا
یکی از محدودیتهای کلیدی مدل جنگل تصادفی، نیاز به منابع پردازشی قابل توجه است. از آنجا که این مدل از تعداد زیادی درخت تصمیم تشکیل شده و هر درخت به صورت جداگانه آموزش میبیند، با افزایش تعداد درختها و حجم دادهها، زمان و قدرت پردازشی مورد نیاز به طور قابل توجهی بالا میرود. این موضوع در پروژههایی با منابع محدود یا دیتاستهای بسیار بزرگ میتواند چالش برانگیز باشد. برای مثال، اجرای یک مدل جنگل تصادفی با 500 درخت روی یک دیتاست عظیم ممکن است به سخت افزار پیشرفته یا زمان طولانی نیاز داشته باشد. با این حال، استفاده از تکنیکهای موازیسازی میتواند این مشکل را تا حدی کاهش دهد.
حساسیت به نویز در دادهها
مدل جنگل تصادفی در برخی موارد، به ویژه در مسائل الگوریتم رگرسیون، به نویز یا مقادیر پرت در دادهها حساس است. اگر دادههای آموزشی شما نویز زیادی داشته باشند، این نویز میتواند پیشبینیهای هر درخت را تحت تأثیر قرار دهد و در نهایت دقت کلی مدل را کاهش دهد. برای رفع این مشکل، پیش پردازش دادهها، حذف مقادیر پرت و تنظیم پارامترهایی مانند عمق درختها ضروری است. این اقدامات میتوانند تأثیر نویز را به حداقل برسانند و عملکرد مدل جنگل تصادفی را بهبود ببخشند.
مشکل تفسیرپذیری مدل
یکی دیگر از چالشهای مدل جنگل تصادفی، پیچیدگی در تفسیر آن است. برخلاف درخت تصمیم که به دلیل سادگی قابل فهم است، مدل جنگل تصادفی به دلیل استفاده از صدها یا هزاران درخت، درک فرآیند تصمیمگیری را دشوار میکند. این موضوع در حوزههایی مانند پزشکی یا مالی که نیاز به توضیح پذیری بالا دارند، میتواند یک ضعف محسوب شود. با این حال، تکنیکهایی مانند اهمیت ویژگیها (Feature Importance) میتوانند نقش هر متغیر در پیشبینی را مشخص کنند. برای مثال، در یک پروژه طبقه بندی برای تشخیص بیماری، این تکنیک میتواند نشان دهد کدام علائم بیشترین تأثیر را دارند. با وجود این محدودیتها، مدل جنگل تصادفی همچنان یکی از بهترین گزینهها برای مسائل پیچیده است، به ویژه زمانی که دقت و پایداری اولویت دارند.
نتیجهگیری
رگرسیون جنگل تصادفی به یک ابزار قدرتمند برای وظایف پیشبینی پیوسته تبدیل شده است که مزایایی نسبت به درختهای تصمیم سنتی دارد. قابلیت مدیریت دادههای با ابعاد بالا، ضبط روابط پیچیده و کاهش اورفیتینگ، این الگوریتم را به یک انتخاب محبوب برای مجموعه متنوعی از کاربردها تبدیل کرده است. کتابخانه scikit-learn در زبان پایتون امکان پیادهسازی، بهینهسازی و ارزیابی مدلهای رگرسیون جنگل تصادفی را فراهم میکند، بطوریکه که این تکنیک به یک روش قابل دسترس و مؤثر برای افراد متخصص یادگیری ماشین تبدیل شود.
سوالات متداول (FAQ)
1-رگرسیون جنگل تصادفی در پایتون چیست؟
رگرسیون جنگل تصادفی در پایتون یک روش یادگیری جمعی است که از چندین درخت تصمیم برای انجام پیشبینیها استفاده میکند. این الگوریتم قدرتمند و چندجانبهای است که برای وظایف رگرسیون مناسب است.
2-استفاده از رگرسیون جنگل تصادفی برای چه منظوری است؟
رگرسیون جنگل تصادفی میتواند برای پیشبینی متغیرهای هدف مختلفی از جمله قیمتها، فروش، انتقال مشتری و موارد دیگر استفاده شود. این الگوریتم یک الگوریتم قوی است که به راحتی اورفیت نمیشود و برای کاربردهای واقعی مناسب است.
3-تفاوت بین جنگل تصادفی و رگرسیون چیست؟
جنگل تصادفی یک روش یادگیری جمعی است، در حالی که رگرسیون یک الگوریتم یادگیری نظارتشده است. جنگل تصادفی از چندین درخت تصمیم برای پیشبینی استفاده میکند، در حالی که رگرسیون از یک مدل تکی برای پیشبینی استفاده میکند.
4-چگونه پارامترهای هایپر رگرسیون جنگل تصادفی را تنظیم کنیم؟
چندین روش برای تنظیم پارامترهای هایپر رگرسیون جنگل تصادفی وجود دارد، از جمله:
– جستجوی شبکه: این جستجو به طور سیستماتیک ترکیبهای مختلف مقادیر هایپرپارامترها را امتحان کرده و بهترین ترکیب را پیدا میکند.
– جستجوی تصادفی: این جستجو به طور تصادفی ترکیبهای مختلف مقادیر هایپرپارامترها امتحان میکند تا ترکیب مناسبی را پیدا کند.
5-چرا جنگل تصادفی بهتر از رگرسیون است؟
جنگل تصادفی به طور کلی دقیقتر و مقاومتر از رگرسیون است. همچنین کمتر به اورفیتینگ حساس است، به این معنا که احتمالاً به خوبی به دادههای جدید عمل میکند.








