در درس پنجم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم با 9تا از بهترین کتابخانه های پایتون برای یادگیری ماشین آشنا شویم. یادگیری ماشین، همانطور که از اسمش پیداست، علمی است که به کامپیوترها این امکان را میدهد تا از انواع مختلف دادهها یاد بگیرند. تعریف کلیتری که توسط آرتور ساموئل ارائه شده است این است:
“یادگیری ماشین، زمینهای است که به کامپیوترها امکان یادگیری بدون نیاز به برنامهنویسی صریح را میدهد.”
معمولاً از این تکنولوژی برای حل مسائل متنوع زندگی استفاده میشود.
در گذشته، مردم برای انجام وظایف یادگیری ماشین با کدنویسی دستی، تمامی الگوریتمها و فرمولهای ریاضی و آماری را پیادهسازی میکردند. این کار باعث میشد که این پروسه، زمانبر، خستهکننده و کمکارایی باشد. اما در دوران مدرن، این فرآیند نسبت به گذشته، با استفاده از کتابخانهها، چارچوبها و ماژولهای مختلف پایتون، بسیار سادهتر و بهینهتر شده است.
امروزه، زبان برنامه نویسی پایتون یکی از محبوبترین زبانهای برنامهنویسی در این زمینه است. یکی از دلایل این محبوبیت، مجموعه گستردهای از کتابخانههای پایتون است که در یادگیری ماشین بهکار میروند. این کتابخانهها عبارتند از:
✔️ Numpy
✔️ Scipy
✔️ Scikit-learn
✔️ Theano
✔️ TensorFlow
✔️ Keras
✔️ PyTorch
✔️ Pandas
✔️ Matplotlib

خلاصه کتابخانه های پایتون به صورت فهرست
در دنیای برنامهنویسی، یک کتابخانه مجموعهای از کدهای آماده است که میتوان از آنها در یک برنامه برای انجام عملیات خاص و مشخص استفاده کرد. یک کتابخانه علاوه بر کدهای آماده، میتواند شامل مستندات، دادههای پیکربندی، الگوهای پیام، کلاسها و مقادیر باشد.
یکی از مفاهیم کلیدی در پایتون، دیکشنریها هستند. دیکشنری در پایتون یک نوع دادهای کلیدی-مقداری است که به ما اجازه میدهد دادهها را به صورت جفتهای کلید و مقدار ذخیره کنیم. این ساختار داده برای دسترسی سریع به مقادیر با استفاده از کلیدهای منحصربهفرد بسیار مفید است. در بسیاری از کتابخانههای پایتون مانند Pandas و Scikit-learn، دیکشنریها برای ذخیره و مدیریت دادهها استفاده میشوند.
کتابخانههای مجموعهای در پایتون به ماژولهای مرتبط هستند. این کتابخانهها شامل بستههای کدی میباشند که میتوانند به طور مکرر در برنامههای مختلف استفاده شوند. این موضوع باعث میشود برنامهنویسی با پایتون برای برنامهنویسان سادهتر و راحتتر باشد، زیرا نیازی به نوشتن مجدد کد مشابه برای برنامههای مختلف نیست. کتابخانههای پایتون نقش بسیار مهمی در زمینههایی مانند یادگیری ماشین، علم داده و تجسم دادهها ایفا میکنند. برای مثال، در علم داده، NumPy و Pandas ابزارهای اساسی برای کار با آرایهها و دادههای جدولی هستند، در حالی که Matplotlib و Seaborn برای مصورسازی دادهها استفاده میشوند.
عملکرد کتابخانههای پایتون به این صورت است که این کتابخانهها مجموعهای از کدها یا ماژولها را ارائه میدهند که میتوانیم در یک برنامه برای عملیات خاص از آنها استفاده کنیم. وقتی که یک کتابخانه را با برنامه خود لینک کرده و آن را اجرا میکنیم، لینککننده به طور خودکار به دنبال آن کتابخانه میگردد. سپس قابلیتهای آن کتابخانه را استخراج کرده و برنامه را بر اساس آن تفسیر میکند. اینگونه است که ما از متدهای یک کتابخانه در برنامه خود استفاده میکنیم. کتابخانههای پایتون حوزهها و کاربردهای وسیعی را پوشش میدهند که عبارتند از:
- تجزیه و تحلیل و دستکاری دادهها: کتابخانههایی مانند Pandas امکان سازماندهی، دستکاری و تجزیه و تحلیل دادهها را به صورت ساختارهای دادهای مانند DataFrame و Series فراهم میکنند و برای کارهایی مانند پاکسازی دادهها، ادغام مجموعه دادهها و محاسبه آمار توصیفی مفید هستند.
- محاسبات علمی: SciPy یک کتابخانه قدرتمند در پایتون است که ابزارهای پیشرفتهای برای بهینهسازی، یکپارچهسازی، درونیابی، جبر خطی و آمار ارائه میدهد.
- یادگیری ماشین و هوش مصنوعی: کتابخانههایی مانند Scikit-learn تقریبا همه الگوریتمهای ماشین لرنینگ را دارد و در NumPy و SciPy درونیابی صورت میگیرد.
- مصورسازی دادهها: این کتابخانه پایتون امکاناتی برای ایجاد تجسمهای ثابت، متحرک و تعاملی با قابلیتهای شخصیسازی گسترده فراهم میکند.
- توسعه وب: اغلب Flask و Django برای ایجاد برنامههای وب و API کاربرد دارند.
- پردازش زبان طبیعی: NLTK و spaCy دارای ابزارهایی برای کار با دادههای متنی زبان انسان هستند.
- توسعه بازی: Pygame ابزارهایی برای ایجاد بازیها و برنامههای کاربردی دارد.
- شبکه و خدمات وب: با Requests میتوانید با درخواستهای HTTP و API کار کرده و ارتباط شبکه را سادهتر میکند.
- پایگاههای داده: کتابخانههایی مانند SQLAlchemy و psycopg موجب تعامل با پایگاههای داده با استفاده از پایتون میشوند.
- تست و ضمانت کیفیت: برای نگارش و ارزیابی انواع کد، میتوانید از ابزارهای unittest و pytest بهره ببرید.
- مدلسازی و تحلیل آماری: Statsmodels ابزارهایی را برای کاوش، مدلسازی و استنتاج دادهها فراهم کرده و امکان پیادهسازی مدلهای آماری پیچیده را میدهد.
برخی از بهترین کتابخانههای پایتون عبارتند از:
- NumPy
- Pandas
- Matplotlib
- Scikit-Learn
- TensorFlow
- SciPy
- Seaborn
- Requests
- Flask
- PyTorch
- BeautifulSoup
- OpenCV
- Scarpy
- NetworkX
- Pil
سایر کتابخانه های پایتون:
- Pygame
- Asyncio
- Tkinter
- Six
- aiohttp
- Kivy
- Bokeh
- Theano
- Keras
- PyCaret
- LightGBM
- MoviePy
- Peewee
- کتابخانه OS
- PyFlux
- Zappa
- Arrow
- IPython
✔️ Numpy

NumPy یک کتابخانه بسیار محبوب در زبان برنامهنویسی پایتون است که برای پردازش آرایهها و ماتریسهای چند بعدی با استفاده از یک مجموعه وسیع از توابع ریاضی سطح بالا طراحی شده است.
این کتابخانه برای محاسبات علمی اساسی در حوزه یادگیری ماشین بسیار کارآمد است و به ویژه برای جبر خطی، تبدیل فوریه و توانمندیهای ایجاد اعداد تصادفی بسیار مفید است. کتابخانههای پیشرفته مانند TensorFlow از NumPy بهطور داخلی برای انجام عملیات بر روی تنسورها استفاده میکنند.
# Python program using NumPy # for some basic mathematical # operations import numpy as np # Creating two arrays of rank 2 x = np.array([[1, 2], [3, 4]]) y = np.array([[5, 6], [7, 8]]) # Creating two arrays of rank 1 v = np.array([9, 10]) w = np.array([11, 12]) # Inner product of vectors print(np.dot(v, w), "\n") # Matrix and Vector product print(np.dot(x, v), "\n") # Matrix and matrix product print(np.dot(x, y))
خروجی:
219
[29 67]
[[19 22]
[43 50]]
کتابخانه نامپای یک کتابخانه مهم و کاربردی برای محاسبات علمی و ریاضی در پایتون میباشد. این کتابخانه به کاربران امکان تعریف و مدیریت آرایهها را میدهد و به طور خاص برای کار با آرایههای چند بعدی و انجام عملیات ریاضی و آماری بهینه شده است. همچنین NumPy به عنوان یک ابزار قدرتمند در تجزیه و تحلیل دادهها، ماشین لرنینگ و هوش مصنوعی شناخته میشود و به طور گستردهای در این زمینهها مورد استفاده قرار میگیرد. این کتابخانه با فراهم کردن ساختارهای داده آرایهای و توابع از پیش نوشته شده، کار با دادههای بزرگ و پیچیده را تسهیل میکند. نامپای به دلیل سرعت بالا و کارایی در انجام محاسبات، به بخش مهم بسیاری از کتابخانهها و بستههای مرتبط با علوم داده و هوش مصنوعی تبدیل شده است. NumPy میتواند به راحتی با بقیه کتابخانههای پایتون مانند SciPy، Matplotlib و پانداس یکی شده و امکانات زیادی را برای تجزیه و تحلیل و تجسم دادهها فراهم میکند.
مزایای کتابخانه NumPy:
- سرعت بالا: از آنجاییکه NumPy از بهترین توابع و اجرای بخشهایی از کد به زبانهای C و C++ استفاده میکند، سرعت پردازش بالایی دارد. این کتابخانه از فرایند Vectorization بهره میبرد که موجب کمترشدن نیاز به حلقههای پایتون شده و محاسبات را با سرعت بیشتری انجام میدهد.
- مدیریت آرایههای چندبعدی: با NumPy امکان کار با آرایههای چندبعدی (مانند ماتریسها) فراهم است و عملیات ریاضی مانند جمع، ضرب و تبدیل را بهراحتی انجام میدهد.
- توابع ریاضی پیشرفته: این کتابخانه دارای توابع مختلفی برای انجام عملیات جبر خطی، تبدیل فوریه، تولید اعداد تصادفی و محاسبات آماری است.
- یکپارچگی با سایر کتابخانهها: NumPy پایهای برای کتابخانههای دیگر مانند Pandas، SciPy و TensorFlow بوده و در حوزههایی مثل علم داده، ماشین لرنینگ و هوش مصنوعی کاربرد بسیار زیادی دارد.
- خوانایی و سادگی: استفاده از NumPy خیلی سخت نیست و کدهای نوشتهشده با آن خوانایی بسیار بالایی دارند.
معایب کتابخانه NumPy
- پیچیدگی برای مبتدیان: استفاده از برخی توابع پیشرفته NumPy نیاز به دانش ریاضی و آمار دارد که میتواند برای کاربران تازهکار کمی چالشبرانگیز باشد.
- مصرف حافظه بالا: آرایههای NumPy به دلیل ذخیرهسازی دادهها در حافظهی پیوسته، از حافظهی بیشتری نسبت به سایر کتابخانههای پایتون استفاده کنند. این موضوع در زمان کار با دادههای بسیار بزرگ مشکلاتی را به وجود میآورد.
- کمبود امکانات پیشرفته: NumPy در زمینه کار با دادههای ساختاریافته یا عملیات مرتبط با زمان دارای محدودیتهایی است و به همین دلیل باید از کتابخانههای مکمل مانند Pandas کمک گرفت.
امکانات کتابخانه NumPy
- ایجاد آرایه از لیست یا تاپل.
- ایجاد آرایه با مقادیر صفر.
- ایجاد آرایه با مقادیر یک.
- ایجاد آرایه از دنبالهی اعداد.
- محاسبه مجموع عناصر آرایه.
- محاسبه میانگین عناصر آرایه.
- محاسبه میانه.
- محاسبه انحراف معیار.
- تولید اعداد تصادفی با توزیع نرمال.
- تغییر ابعاد آرایه.
✔️ Scipy

SciPy یک کتابخانه بسیار محبوب در میان علاقهمندان به یادگیری ماشین است، زیرا شامل ماژولهای مختلف برای بهینهسازی، جبر خطی، ادغام و آمار میشود.
تفاوتی بین کتابخانه SciPy و اینکه از یک “پکیج SciPy” صحبت میشود، وجود دارد. SciPy یکی از بستههای اصلی است که به تشکیل پکیج SciPy کمک میکند. همچنین، SciPy برای کارهای مرتبط با تصاویر نیز بسیار کارآمد است.
# Python script using SciPy for image manipulation
from scipy import ndimage
import matplotlib.pyplot as plt
# Read a JPEG image into a numpy array
img = plt.imread('cat.jpg') # path of the image
print(img.dtype, img.shape)
# Tinting the image with an intensity factor
tint_intensity = 0.003 # Adjust this value to control the tinting intensity
img_tint = img * [1, 0.45, 0.3] * tint_intensity
# Scaling values to the [0, 1] range
img_tint = img_tint.clip(0, 1)
# Saving the tinted image
plt.imsave('cat_tinted.jpg', img_tint)
# Resizing the tinted image to be 300 x 300 pixels
img_tint_resize = ndimage.zoom(img_tint, (300 / img_tint.shape[0], 300 / img_tint.shape[1], 1), order=3)
# Scaling values to the [0, 1] range for resized image
img_tint_resize = img_tint_resize.clip(0, 1)
# Saving the resized tinted image
plt.imsave('cat_tinted_resized.jpg', img_tint_resize)
کتابخانه SciPy (مخفف Scientific Python) یکی از کتابخانههای مهم و پرکاربرد در پایتون است که بیشتر بر محاسبات علمی تمرکز دارد. این کتابخانه بر پایه نامپای ایجاد شده و دارای ماژولهای متعددی برای انجام عملیاتهای پیشرفته ریاضی، آماری، بهینهسازی، پردازش سیگنال، جبر خطی و محاسبات عددی است. SciPy بهعنوان یک ابزار جامع، محاسبات پیچیده را با سرعت و دقیت زیادی انجام میدهد. این کتابخانه بیشتر در مباحثی مثل فیزیک، زیستشناسی، مهندسی و علوم داده کاربرد دارد. از مهمترین ویژگیهای SciPy میتوان به توابع بهینهسازی (optimization)، انتگرالگیری عددی (integration)، حل معادلات دیفرانسیل (differential equations) و پردازش سیگنال (signal processing) اشاره کرددر کنار این مفاهیم، آشنایی با رشتهها در پایتون نیز ضروری است؛ رشتهها برای ذخیره و پردازش متن به کار میروند و یکی از پرکاربردترین نوع دادهها در این زبان محسوب میشوند.
همچنین این کتابخانه از ساختارهای دادهای پیشرفته مثل ماتریسهای خلوت (sparse matrices) پشتیبانی میکند که برای کار با دادههای حجیم بسیار کاربردی است. با توجه به انعطافپذیری و عملکرد بالای SciPy، این کتابخانه بهعنوان یکی از ابزارهای اصلی در اکوسیستم علمی پایتون شناخته میشود و به همراه کتابخانههایی مانند NumPy، Matplotlib و Pandas، یک محیط کامل برای تحلیل و پردازش دادهها ارائه میدهد. پیشنهاد میکنیم مهم ترین کاربرد های پایتون را نیز مطالعه کنید.
مزایای SciPy
- متنباز و رایگان: SciPy به صورت رایگان در دسترس همه قرار دارد و تعدا زیادی از مهندسین داده و توسعهدهنده از آن پشتیبانی میکنند.
- ادغام با NumPy: این کتابخانه میتواند با نامپای یکی شود و به همین دلیل به راحتی میتوان با آرایهها و ماتریسها کار کرد.
- ابزارهای پیشرفته: دارای توابع و الگوریتمهای پیشرفته برای بهینهسازی، انتگرالگیری، حل معادلات دیفرانسیل و پردازش سیگنال است.
- جامعه بزرگ و مستندات کامل: جامعه فعال و مستندات جامع این کتابخانه، آموزش و استفاده از SciPy را برای کاربران راحتتر میکند.
- کارایی بالا: بسیاری از توابع SciPy بهینهسازی شدهاند و از کتابخانههای سطح پایین مانند C و Fortran بهره میبرند.
- قابلیت توسعه: میتوان آن را با سایر کتابخانههای پایتون مانند Matplotlib، Pandas و Scikit-learn ترکیب کرد.
معایب SciPy
- پیچیده برای کابران غیرحرفهای: یادگیری و استفاده از SciPy برای کاربران تازهکار کمی چالشبرانگیز است.
- وابستگی به NumPy: برای استفاده از SciPy، باید NumPy را نیز یاد بگیرید که این کار کمی زمانبر است.
- محدودیتهای عملکردی: برای برخی از کاربردهای خاص خیلی مناسب نیست و باید از کتابخانههای تخصصیتر کمک بگیرید.
- حجم محاسباتی: به دلیل محدودیتهای حافظه و پردازش در دادههای خیلی بزرگ عملکرد کندی دارد.
امکانات SciPy
- SciPy شامل ماژولهای متعددی است که هر کدام برای کاربردهای خاصی طراحی شدهاند. برخی از مهمترین امکانات آن عبارتند از:
- انتگرالگیری و حل معادلات دیفرانسیل (integrate): انتگرالگیری عددی، حل معادلات دیفرانسیل معمولی (ODE).
- پردازش سیگنال (signal): فیلتر کردن سیگنالها، تحلیل طیفی.
- آمار و احتمالات (stats): توزیع و آزمونهای آماری.
- جبر خطی (linalg): عملیات ماتریسی، تجزیه ماتریسها (مانند SVD، QR).
- پردازش تصویر (ndimage): فیلتر کردن و تبدیل تصاویر.
- کار با دادههای پراکنده (scipy.sparse): مدیریت ماتریسهای پراکنده و عملیات جبر خطی روی ماتریسهای پراکنده.

✔️ Scikit-learn

Scikit-learn یکی از پرطرفدارترین کتابخانههای یادگیری ماشین برای الگوریتمهای کلاسیک یادگیری ماشین است. این کتابخانه بر پایه دو کتابخانه اصلی پایتون، یعنی NumPy و SciPy ساخته شده است.
Scikit-learn اکثر الگوریتمهای یادگیری با نظارت و بدون نظارت را پشتیبانی میکند. همچنین، میتوان از Scikit-learn برای استخراج داده و تحلیل داده نیز استفاده کرد، که این کتابخانه را به یک ابزار عالی برای کسانی که تازه با یادگیری ماشین شروع کردهاند، تبدیل کرده است.
# Python script using Scikit-learn # for Decision Tree Classifier # Sample Decision Tree Classifier from sklearn import datasets from sklearn import metrics from sklearn.tree import DecisionTreeClassifier # load the iris datasets dataset = datasets.load_iris() # fit a CART model to the data model = DecisionTreeClassifier() model.fit(dataset.data, dataset.target) print(model) # make predictions expected = dataset.target predicted = model.predict(dataset.data) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
خروجی:
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
precision recall f1-score support
0 1.00 1.00 1.00 50
1 1.00 1.00 1.00 50
2 1.00 1.00 1.00 50
micro avg 1.00 1.00 1.00 150
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150
[[50 0 0]
[ 0 50 0]
[ 0 0 50]]
Scikit-learn یک کتابخانه قدرتمند و متنباز برای ماشین لرنینگ در پایتون است که بر پایه کتابخانههای NumPy، SciPy و matplotlib توسعه یافته است. این کتابخانه دارای ابزارهای ساده و کارآمدی برای دادهکاوی و تحلیل دادهها میباشد و به دلیل سادگی در استفاده و کارایی بالا، به یکی از محبوبترین کتابخانهها در حوزه ماشین لرنینگ تبدیل شده است. Scikit-learn از الگوریتمهای متنوعی برای طبقهبندی، رگرسیون، خوشهبندی، کاهش ابعاد، انتخاب مدل و پیشپردازش دادهها پشتیبانی میکند و به کاربران این امکان را میدهد تا به سرعت مدلهای پیچیده را پیادهسازی و ارزیابی کنند.
یکی از بارزترین ویژگیهای Scikit-learn، مستندات جامع آن است که یادگیری و استفاده از آن را برای طیف گستردهای از کاربران سادهتر میکند. این کتابخانه در بسیاری از پروژههای علمی، صنعتی و آموزشی مورد استفاده قرار میگیرد و به دلیل سازگاری با سایر کتابخانههای پایتون مانند Pandas، TensorFlow، Matplotlib و Seaborn ، انعطافپذیری بالایی در توسعه پروژههای ماشین لرنینگ دارد. با مطالعه آموزش رایگان پایتون میتوانید با این کتابخانهها بیشتر آشنا شوید.
مزایای Scikit-Learn
- ادغام با دیگر کتابخانههای مهم پایتون: هماهنگ با نامپای و Pandas برای تجزیه و تحلیل و سازماندهی کارآمد دادهها.
- سادگی و سهولت استفاده: دارای رابط کاربری ساده و یکپارچه برای پیادهسازی الگوریتمهای ماشین لرنینگ.
- کارایی بالا: بهینهسازیشده برای عملکرد سریع و استفاده بهینه از منابع.
- متنباز و جامعه فعال: دارای جامعه بزرگی از توسعهدهندگان و کاربران است که به بهبود مستمر آن کمک میکنند.
- ابزارهای پیشپردازش داده: دارای ابزارهای قدرتمند برای پیشپردازش دادهها مانند نرمالسازی، استانداردسازی، مدیریت مقادیر گمشده و تبدیل دادههای کیفی.
- ارزیابی مدل: ارائه ابزارهای پیشرفته برای ارزیابی مدلهایی مثل ماتریس، گزارش طبقهبندی، منحنی ROC و غیره.
معایب Scikit-Learn
- عدم پشتیبانی از یادگیری عمیق: برای دیپ لرنینگ مناسب نیست و برای این کار باید از کتابخانههایی مانند TensorFlow یا PyTorch استفاده کرد.
- محدودیت در پردازش دادههای بزرگ: اغلب در دادههای خیلی بزرگ (Big Data) عملکرد کندی دارد، مگر اینکه از تکنیکهایی مانند نمونهگیری یا استفاده از کتابخانههایی مانند Dask استفاده شود.
- عدم پشتیبانی از پردازش روی GPU: Scikit-Learn بهطور پیشفرض از GPU پشتیبانی نمیکند و این موضوع میتواند برای دادههای بزرگ یا مدلهای پیچیده محدودیتهایی را به وجود بیاورد.
- پیادهسازیهای پایهای: برخی الگوریتمها (مانند XGBoost یا LightGBM) در Scikit-Learn بهینهسازی نشدهاند و بهتر است کاربران از کتابخانههای تخصصیتر استفاده کنند.
امکانات Scikit-Learn
- الگوریتمهای یادگیری نظارتشده: رگرسیون خطی، رگرسیون لجستیک، SVM، درخت تصمیم، جنگل تصادفی، گرادیان بوستینگ و غیره.
- الگوریتمهای یادگیری غیرنظارتشده: K-Means، DBSCAN، خوشهبندی، PCA، t-SNE و غیره.
- انتخاب مدل و ارزیابی: اعتبارسنجی متقاطع، GridSearchCV، RandomizedSearchCV، ماتریس سردرگمی و منحنی ROC.
- ابزارهای کار با متن: تبدیل متن به بردار (TF-IDF، CountVectorizer).
✔️ Theano

همه ما میدانیم که یادگیری ماشین اساساً بر پایه دانش ریاضیات و آمار است. Theano یک کتابخانه پرطرفدار در زبان برنامه نویسی پایتون است که برای تعریف، ارزیابی و بهینهسازی عبارات ریاضی مرتبط با آرایههای چند بعدی به نحوی کارآمد مورد استفاده قرار میگیرد. این کار با بهینهسازی استفاده از منابع پردازشی مرکزی (CPU) و گرافیکی (GPU) انجام میشود.
Theano به طور گسترده برای تست و اعتبارسنجی خودکار برای شناسایی و تشخیص انواع مختلف خطاها استفاده میشود. این کتابخانه یک ابزار بسیار قدرتمند است که به مدت طولانی در پروژههای علمی با محاسبات گسترده مورد استفاده قرار گرفته است، اما به اندازهای ساده و قابل دسترس است که افراد بتوانند آن را برای پروژههای شخصی خود به کار ببرند.
# Python program using Theano
# for computing a Logistic
# Function
import theano
import theano.tensor as T
x = T.dmatrix('x')
s = 1 / (1 + T.exp(-x))
logistic = theano.function([x], s)
logistic([[0, 1], [-1, -2]])
خروجی:
array([[0.5, 0.73105858],
[0.26894142, 0.11920292]])
Theano یکی از کتابخانههای مناسب برای محاسبات عددی در پایتون میباشد که به صورت ویژه برای محاسبات سریع و کارآمد روی CPU و GPU طراحی شده است. این کتابخانه در سال ۲۰۰۷ توسط گروه MILA (موسسه یادگیری ماشین مونترال) ایجاد شد و بهعنوان یکی از پیشگامان محاسبات تنسور و دیپ لرنینگ شناخته میشود. Theano امکان تعریف، بهینهسازی و ارزیابی عبارات ریاضی مثل آرایههای چندبعدی (مانند ماتریسها و تنسورها) را ارائه میدهد. این کتابخانه به صورت وسیع در تحقیقات ماشین لرننیگ و توسعه مدلهای شبکه عصبی کاربرد دارد.
یکی از مهمتری ویژگیهای Theano، قابلیت بهینه کردن خودکار محاسبات است. این کتابخانه میتواند مباحث ریاضی را به کدهای بهینهشده برای اجرا روی CPU یا GPU تبدیل کند. این ویژگی باعث میشود Theano برای اجرای مدلهای پیچیده دیپ لرنینگ که نیاز به محاسبات پیچیده دارند، مناسب باشد. علاوه بر این، Theano از مشتقگیری خودکار (Automatic Differentiation) پشتیبانی میکند. این ویژگی برای آموزش مدلهای شبکه عصبی با استفاده از الگوریتمهایی مانند گرادیان کاهشی کارایی بسیار زیادی دارد.
با وجود تمام این ویژگیها توسعه Theano در سال ۲۰۱۷ متوقف شده و آخرین نسخه آن (Theano 1.0) در سال ۲۰۱۸ منتشر شد. اگرچه این کتابخانه دیگر بهروزرسانی نمیشود، اما نقش مهمی در توسعه کتابخانههای مدرن یادگیری عمیق مانند TensorFlow و PyTorch داشته است. بسیاری از مفاهیم و قابلیتهایی که در Theano معرفی شدند، اکنون در این کتابخانهها بهصورت پیشرفتهتر وجود دارند. اگر میخواهید با این کتابخانهها کار کنید توصیه میکنیم از دوره آموزش رایگان یادگیری ماشین با پایتون و آموزش صفر تا صد پایتون کمک بگیرید.
مزایای Theano
- محاسبات کارآمد: Theano محاسبات ریاضی را بهینهسازی میکند و امکان اجرای موازی روی GPU را ارائه میدهد. این ویژگی باعث افزایش سرعت محاسبات میشود.
- پشتیبانی از CPU و GPU: Theano هم روی CPU و هم روی GPU قابل اجراست. این ویژگی موجب افزایش انعطافپذیری این کتابخانه میشود.
- یکپارچهسازی با NumPy: این کتابخانه به خوبی با NumPy سازگار است و از آرایههای چندبعدی پشتیبانی میکند.
معایب Theano
- منحنی یادگیری شیبدار: استفاده از Theano نیاز به دانش ریاضی و برنامهنویسی پیشرفته دارد.
- زمان کامپایل طولانی: زمان کامپایل برای مدلهای پیچیده طولانیتر است.
- عدم پشتیبانی از گرافهای پویا: Theano یک چارچوب مبتنی بر گرافهای ایستا است و از گرافهای پویا پشتیبانی نمیکند.
- فعالیت توسعهای کم: توسعه Theano متوقف شده است و همین امر باعث کاهش بهروزرسانیها و رفع باگها میشود.
- خوانایی پایین کد: کدهای نوشتهشده با Theano به دلیل استفاده از عبارات نمادین، خوانایی کمتری نسبت به روشهای برنامهنویسی سنتی دارند.
امکانات Theano
- پشتیبانی از شبکههای عصبی: Theano برای اجرا و بهبود مدلهای شبکههای عصبی مناسب است و میتواند سرعت اجرای مدلها را تا حد زیادی افزایش دهد.
- تشخیص ناپایداری عددی: این کتابخانه قادر است عبارات ناپایدار عددی را شناسایی و آنها را با الگوریتمهای پایدارتر جایگزین کند.
- واحد تست و اعتبارسنجی: این کتابخانه دارای ابزارهایی برای تست و اعتبارسنجی مدلها است. با این ویژگی میتوان خطاها را خیلی سریع و دقیق تشخیص داد.
✔️ TensorFlow

TensorFlow یک کتابخانه متن باز (Open-source) بسیار محبوب برای محاسبات عددی با عملکرد بالا است که توسط تیم Google Brain در گوگل توسعه یافته است.
همانطور که از نام آن پیداست، TensorFlow یک چارچوب است که شامل تعریف و اجرای محاسبات مرتبط با تنسورها میشود.
TensorFlow این قابلیت را دارد که شبکههای عصبی عمیق را آموزش داده و اجرا کند که میتواند برای توسعه انواع برنامههای هوش مصنوعی مورد استفاده قرار گیرد. TensorFlow به طور گسترده در زمینه تحقیقات و کاربردهای یادگیری عمیق استفاده میشود.
# Python program using TensorFlow # for multiplying two arrays # import `tensorflow` import tensorflow as tf tf.compat.v1.disable_eager_execution() # Initialize two constants x1 = tf.constant([1, 2, 3, 4]) x2 = tf.constant([5, 6, 7, 8]) # Multiply result = tf.multiply(x1, x2) sess = tf.compat.v1.Session() # Initialize the Session # Print the result print(sess.run(result)) # Close the session sess.close()
خروجی:
[ 5 12 21 32]
TensorFlow این کتابخانه اغلب برای ساخت و آموزش مدلهای یادگیری عمیق و شبکههای عصبی مورد استفاده قرار میگیرد. TensorFlow از یک معماری انعطافپذیر بهره میبرد و موجب میشود کاربران محاسبات را بر روی انواع مختلفی از سختافزارها، از جمله CPU، GPU و TPU، اجرا کنند. همچنین این کتابخانه از زبانهای برنامهنویسی مختلفی پشتیبانی میکند، اما پایتون زبان اصلی TensorFlow است. یکی از بارزترین ویژگیهای TensorFlow، امکان استفاده از گرافهای محاسباتی است. در این گرافها، گرهها نمایانگر محاسبات ریاضی و یالها نمایانگر دادههای چندبعدی (تنسورها) هستند که مابین این عملیاتها جریان دارند. این ساختار به TensorFlow اجازه میدهد تا محاسبات را بهتر و دقیقتر انجام دهد. علاوه بر این، TensorFlow از ابزارهایی مانند TensorBoard برای تجسم گرافهای محاسباتی و روند آموزش مدلها پشتیبانی میکند. با این مزیت کاربران میتوانند مدلهای خود را بهتر درک کرده و اشکالات آنها را از بین ببرند.
همچنین TensorFlow ماژولهای پیشساختهای دارد که فرآیند ساخت مدلهای پیچیده را سادهتر میکنند. برای مثال، Keras که بهعنوان بخشی از TensorFlow ارائه میشود، یک رابط کاربری بینظیر است که به کاربران اجازه میدهد بهسرعت مدلهای شبکه عصبی را طراحی و آموزش دهند. علاوه بر این TensorFlow Lite و TensorFlow.js به توسعهدهندگان امکان میدهند تا مدلهای خود را بهترتیب بر روی دستگاههای موبایل و مرورگرهای وب اجرا کنند. این ویژگیها باعث شده که TensorFlow یکی از محبوبترین کتابخانهها در حوزه یادگیری ماشین و هوش مصنوعی باشد.
مزایای TensorFlow
- انعطافپذیری زیاد: TensorFlow از یک معماری انعطافپذیر پشتیبانی میکند که به کاربران اجازه میدهد مدلهای یادگیری ماشین را بر روی انواع سختافزارها (مانند CPU، GPU و TPU) اجرا کنند.
- پشتیبانی از پایتون: پایتون بهعنوان زبان اصلی TensorFlow شناخته میشود و این کتابخانه از اکوسیستم گستردهی پایتون بهره میبرد.
- ابزارهای قدرتمند: TensorFlow ابزارهایی مانند TensorBoard برای تجسم دادهها و روند آموزش مدلها و TensorFlow Extended (TFX) را برای استقرار مدلها در محیطهای تولیدی ارائه میدهد.
- جامعه بزرگ و مستندات غنی: TensorFlow دارای یک جامعه فعال و مستندات جامع است که یادگیری و استفاده از آن را سادهتر میکند.
- پشتیبانی از مدلهای پیشساخته: با استفاده از Keras (که بخشی از TensorFlow است) کاربران میتوانند بهسرعت مدلهای شبکه عصبی را طراحی و آموزش دهند.
- قابلیت اجرا بر روی دستگاههای مختلف: TensorFlow Lite و js به توسعهدهندگان اجازه میدهند مدلها را هم روی دستگاههای موبایل و هم روی مرورگرهای وب اجرا کنند.
معایب TensorFlow
- پیچیدگی یادگیری: TensorFlow برای کاربران مبتدی خیلی قابل درک و فهم نیست، بهویژه در مقایسه با کتابخانههایی مانند PyTorch که رابط کاربری سادهتری دارند.
- اجرای کند روی CPU: در مقایسه با GPU، اجرای مدلها روی CPU میتواند بسیار کندتر باشد.
- اشکالزدایی دشوار: به دلیل استفاده از گرافهای محاسباتی استاتیک (در نسخههای قدیمیتر)، اغلب اشکالزدایی مدلها چالشبرانگیز است.
- حجم بالای منابع: TensorFlow به منابع سختافزاری بیشتری نسبت به سایر کتابخانههای پایتون نیاز دارد.
- تغییرات مکرر API: TensorFlow تغییرات زیادی در API خود داشته و به همین دلیل کاربران قدیمی هنگام استفاده از آن به مشکل برمیخورند.
امکانات TensorFlow
- گرافهای محاسباتی: TensorFlow از گرافهای محاسباتی برای معرفی و اجرای مدلها بهره میبرد که با آن، بهینهسازی و توزیع محاسبات سادهتر میشود.
- پشتیبانی از یادگیری عمیق و ماشین: TensorFlow از انواع مدلهای یادگیری ماشین و یادگیری عمیق، از جمله شبکههای عصبی پیچیده، پشتیبانی میکند.
- TensorFlow Lite: برای استقرار مدلها بر روی دستگاههای موبایل و اینترنت اشیا (IoT).
- js: برای اجرای مدلها در مرورگرهای وب و محیطهای جاوااسکریپت.
- پشتیبانی از TPU: TensorFlow از واحدهای پردازش تنسور (TPU) گوگل پشتیبانی میکند و به همین دلیل برای اجرای مدلهای بزرگ بسیار کارآمد هستند.
- مدلهای از پیش آموزشدیده: TensorFlow Hub و TensorFlow Model Garden مجموعهای از مدلهای از پیش آموزشدیده را ارائه میدهند که میتوانند برای کاربردهای مختلف استفاده شوند.
- پشتیبانی از توزیعشدهسازی: TensorFlow امکان آموزش و استقرار مدلها بهصورت توزیعشده بر روی چندین دستگاه یا سرور را ارائه میدهد.
✔️ Keras

این کتابخانه بسیاری از روشهای داخلی برای گروهبندی، ترکیب و فیلتر کردن دادهها را فراهم میکند. Keras یک کتابخانه بسیار محبوب برای یادگیری ماشین در زبان پایتون است.
این کتابخانه یک واسط نرمافزاری برای شبکههای عصبی سطح بالا است که قابل اجرا بر روی TensorFlow، CNTK یا Theano است و به صورت ساده بر روی هر دو CPU و GPU قابل اجرا است.
Keras به افراد مبتدی در زمینه یادگیری ماشین این امکان را میدهد که به راحتی یک شبکه عصبی را طراحی و ایجاد کنند. یکی از بهترین ویژگیهای Keras این است که اجازه ساخت نمونهها (پروتوتایپها) به سرعت و با سهولت را فراهم میکند.
Keras یکی از محبوبترین کتابخانههای دیپ لرنینگ در پایتون است و به عنوان یک ابزار قدرتمند و کاربرپسند برای ساخت و آموزش مدلهای عصبی شناخته میشود. این کتابخانه با ارائه یک رابط برنامهنویسی ساده و انعطافپذیر، فرآیند طراحی شبکههای عصبی را حتی برای مبتدیان به تجربهای لذتبخش تبدیل کرده است. Keras به عنوان یک ورژن پیشرفتهتر، برروی کتابخانههایی مانند TensorFlow، Theano و CNTK قابل اجرا بوده و به مهندسان این امکان را میدهد تا بدون نیاز به نوشتن کدهای پیچیده، مدلهای خود را در کوتاهترین زمان ممکن اجرا کنند. کاراس تمام ابزارهای لازم، از شبکههای عصبی ساده گرفته تا معماریهای پیشرفته مانند LSTM و GAN را در اختیار شما قرار میدهد تا ایدههای خود را به واقعیت تبدیل کنید.
یکی از ویژگیهای منحصربفرد Keras، تمرکز آن بر روی سرعت توسعه و آزمایش ایدههاست. با استفاده از این کتابخانه، شما میتوانید به راحتی یک مدل یادگیری عمیق ایجاد کرده و آن را روی دادههای خود آموزش دهید. Keras از انواع لایههای از پیش تعریف شده، توابع فعالسازی، بهینهسازها و تابعهای هزینه پشتیبانی میکند. با این ویژگی دیگر نیاز نیست کار را از صفر شروع کنید. علاوه بر این، این کتابخانه از قابلیتهای پیشرفتهای مثل تنظیم خودکار هیپرپارامترها، ذخیره و بارگذاری مدلها و حتی اجرای آنها روی GPU پشتیبانی میکند. اگر به دنبال کتابخانهای هستید که هم قدرت و هم سادگی را در کنار هم ارائه دهد، بی شک Keras یکی از بهترین انتخابهاست. مطالعه آموزش رایگان شبکه عصبی میتواند به شما در درک بهتر این کتابخانهها کمک کند.
مزایای Keras
- سادگی و کاربرپسندبودن: کراس به دلیل رابط برنامهنویسی سادهای که دارد یکی از بهترین انتخابها برای مبتدیان و متخصصان است. با استفاده از Keras شما میتوانید مدلهای پیچیده دیپ لرننیگ را فقط در چند خط کد پیادهسازی کنید.
- پشتیبانی از چندین بکاند: کراس میتواند روی کتابخانههای مختلفی مانند TensorFlow، Theano و CNTK اجرا شود. این ویژگی به شما امکان میدهد تا از مزایای هر بکاند بهره ببرید.
- جامعه فعال و مستندات غنی: Keras دارای جامعه بزرگی از توسعهدهندگان است که به طور مداوم در حال بهبود آن هستند. همچنین مستندات جامع و مثالهای متعدد آن، یادگیری و استفاده از کتابخانه را سادهتر میکند.
- پشتیبانی از GPU و TPU: کراس به طور خودکار از قابلیتهای سختافزاری مانند GPU و TPU بهره میبرد. این ویژگی سرعت آموزش مدلهای بزرگ را تا حد زیادی افزایش میدهد.
- ابزارهای پیشرفته: Keras ابزارهایی مانند تنظیم خودکار هیپرپارامترها، ذخیره و بارگذاری مدلها و قابلیت Fine-Tuning را ارائه میدهد.
معایب Keras
- سطح انتزاع بالا: اگرچه سادگی Keras یک مزیت برای آن است، اما برای برخی کاربران حرفهای که نیاز به کنترل دقیق روی تمام جزئیات مدل دارند، میتواند محدودکننده باشد.
- وابستگی به بکاند: کراس به تنهایی یک کتابخانه مستقل نیست و برای اجرا به کتابخانههای دیگری مانند TensorFlow وابسته است. این موضوع ممکن است در برخی موارد محدودیتهای را به وجود بیاورد.
- سرعت پایینتر نسبت به کتابخانههای سطح پایین: این کتابخانه به دلیل سطح انتزاع بالا در مقایسه با کتابخانههای سطح پایین مانند TensorFlow خالص یا PyTorch، سرعت کمتری دارد.
- محدودیت در سفارشیسازی: کراس برای برخی کاربردهای بسیار پیشرفته یا تحقیقاتی انعطافپذیری کافی ندارد و کاربران باید از کتابخانههای سطح پایین بهره ببرند.
امکانات Keras
- لایههای از پیش تعریف شده: کراس شامل انواع لایههای آماده مانند Dense، Convolutional، Pooling، Dropout و Embedding است که باعث میشود مدل به سرعت ساخته شود.
- توابع فعالسازی و بهینهسازها: این کتابخانه از توابع فعالسازی رایج مانند ReLU، Sigmoid، و Tanh و بهینهسازهایی مانند Adam، SGD و RMSprop پشتیبانی میکند.
- ابزارهای ارزیابی و مانیتورینگ: کراس امکاناتی مانند Callbackها را ارائه میدهد که شما با کمک آن میتوانید فرآیند آموزش را مانیتور کرده و اقداماتی مانند ذخیره مدل یا توقف زودهنگام را انجام دهید.
- پشتیبانی از مدلهای Sequential و Functional: شما میتوانید مدلهای خود را به دو روش Sequential (برای مدلهای خطی) و Functional API (برای مدلهای پیچیدهتر با چندین ورودی و خروجی) بسازید.
- پشتیبانی از Transfer Learning: کراس امکان استفاده از مدلهایی مثل VGG، ResNet و Inception را فراهم میکند. در این صورت میتوانید مدت زمان کمتری را صرف آموزش کنید.
- پشتیبانی از دادههای بزرگ: کراس با ابزارهایی مثل ImageDataGenerator و Sequence، امکان کار با دادههای بزرگتر را فراهم میکند.
✔️ PyTorch

PyTorch یک کتابخانه محبوب یادگیری ماشین متنباز برای زبان پایتون است که بر پایه Torch قرار دارد. Torch یک کتابخانه متنباز یادگیری ماشین است که با یک پیادهسازی در زبان C و یک wrapper در Lua ایجاد شده است.
PyTorch دارای انتخاب گستردهای از ابزارها و کتابخانههاست که از دید بینایی ماشین، پردازش زبان طبیعی (NLP) و برنامههای مختلف یادگیری ماشین پشتیبانی میکنند که به توسعهدهندگان این امکان را میدهد که محاسبات را بر روی تنسورها با استفاده از شتابدهی GPU انجام داده و همچنین در ایجاد گرافهای محاسباتی به کار گرفته میشود.
# Python program using PyTorch
# for defining tensors fit a
# two-layer network to random
# data and calculating the loss
import torch
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") Uncomment this to run on GPU
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
# Randomly initialize weights
w1 = torch.randn(D_in, H, device=device, dtype=dtype)
w2 = torch.randn(H, D_out, device=device, dtype=dtype)
learning_rate = 1e-6
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
خروجی:
0 47168344.0 1 46385584.0 2 43153576.0 ... ... ... 497 3.987660602433607e-05 498 3.945609932998195e-05 499 3.897604619851336e-05
PyTorch یک کتابخانه بسیار کاربردی برای ماشین لرنینگ و محاسبات تنسوری است که توسط فیسبوک توسعه یافته و به صورت گسترده در تحقیقات و صنعت مورد استفاده قرار میگیرد. این کتابخانه به زبان پایتون نوشته شده و قابلیتهایی مثل محاسبات تنسوری پیشرفته، شبکههای عصبی عمیق و امکان اجرا روی GPU را دارد. PyTorch به دلیل سادگی و انعطافپذیری بالا، یکی از محبوبترین ابزارها برای توسعه مدلهای دی لرنینگ میباشد. یکی از ویژگیهای بارز PyTorch، استفاده از گرافهای فعال است که به توسعهدهندگان اجازه میدهد مدلهای خود را در زمان اجرا تغییر بدهند.
PyTorch ابزارهای جامعی برای ساخت و آموزش مدلهای دیپ لرنینگ مثل ماژولهای از پیش ساختهشده برای لایههای شبکههای عصبی، توابع فعالسازی و الگوریتمهای بهینهسازی ارائه میدهد. همچنین این کتابخانه با کتابخانههای دیگری مانند نامپای سازگاری دارد و امکان تبدیل آسان بین آرایههای نامپای و تنسورهای PyTorch را فراهم میکند. PyTorch از ابزارها و کتابخانههای جانبی متنوعی مثل TorchVision (برای پردازش تصویر)، TorchText (برای پردازش زبان طبیعی) و TorchAudio (برای پردازش صوت) بهره میبرد. این ویژگیها باعث شده PyTorch انتخابی ایدهآل برای محققان و توسعهدهندگان در حوزههای مختلف یادگیری ماشین و هوش مصنوعی باشد.
مزایای PyTorch
- گراف محاسباتی فعال (Dynamic Computation Graph): امکان تغییر مدل در حین اجرا را دارد و به همین دلیل برای تحقیقات و آزمایشهای پیچیده بسیار مناسب است. این ویژگی باعث میشود کدنویسی و اشکالزدایی سادهتر شود.
- سادگی و انعطافپذیری: PyTorch از نحو (syntax) ساده و مشابه پایتون استفاده میکند و باعث میشود یادگیری و استفاده از آن راحتتر باشد. همچنین این کتابخانه به توسعهدهندگان اجازه میدهد کنترل کاملی روی مدلها و فرآیند آموزش داشته باشند.
- پشتیبانی از GPU: امکان اجرای محاسبات روی GPU را فراهم میکند و باعث میشود مدلهای بزرگ آموزشها را در کوتاهترین زمان ممکن دریافت کنند.
- جامعه بزرگ و اکوسیستم قوی: PyTorch دارای جامعهای فعال و گسترده است که منابع آموزشی، کتابخانههای جانبی و ابزارهای متعددی را ارائه میدهد. کتابخانههایی مثل TorchVision، TorchText و TorchAudio برای کاربردهای خاص توسعه یافتهاند.
- سازگاری با NumPy: تنسورهای PyTorch به راحتی به آرایههای نامپای تبدیل میشوند و به همین دلیل کاربران میتوانند خیلی راحت از آنها استفاده کنند.
معایب PyTorch
- سرعت اجرا در محیط تولید (Production): اگرچه PyTorch برای تحقیقات عالی است، اما در مقایسه با برخی فریمورکها مثل TensorFlow، میتواند در محیطهای تولیدی بهینهسازی کمتری داشته باشد (البته این مشکل با ابزارهایی مانند TorchScript و ONNX در حال بهبود است).
- مصرف حافظه بیشتر: به دلیل استفاده از گرافهای محاسباتی فعال در مقایسه با برخی فریمورکها مصرف حافظه بیشتری دارد.
- مستندات کمتر نسبت به TensorFlow: اگرچه مستندات PyTorch خوب است، اما در مقایسه با TensorFlow، منابع آموزشی و راهنماهای کمتری دارد (البته این شکاف به مرور زمان از بین میرود).
امکانات PyTorch
- محاسبات تنسوری: ارائه عملیات پیشرفته روی تنسورها با پشتیبانی از GPU و CPU.
- شبکههای عصبی عمیق: ماژولهای از پیش ساختهشده برای لایههای شبکههای عصبی (مانند لایههای خطی، کانولوشنال، RNN و غیره).
- توابع فعالسازی و Loss: دارای توابع فعالسازی مانند ReLU، Sigmoid و توابع Loss مانند CrossEntropyLoss و MSE.
- بهینهسازها (Optimizers): الگوریتمهای بهینهسازی مثل SGD، Adam و RMSprop برای آموزش مدلها.
- دارای ابزارهای جانبی: TorchVision برای پردازش تصویر و بینایی کامپیوتر، TorchText برای پردازش زبان طبیعی (NLP) و TorchAudio: برای پردازش صوت.
- پشتیبانی از Distributed Training: امکان آموزش مدلها به صورت توزیعشده روی چندین GPU یا سرور.
- تبدیل مدلها به فرمتهای تولیدی: دارای ابزارهایی مثل TorchScript و ONNX برای تبدیل مدلهای PyTorch به فرمتهای مناسب محیطهای تولیدی.
✔️ Pandas

Pandas یک کتابخانه پرطرفدار در زبان پایتون برای تحلیل دادههاست، اما به طور مستقیم به یادگیری ماشین مرتبط نیست. همانطور که میدانیم، قبل از شروع فرآیند آموزش، مجموعه داده باید آماده شود.
در این مورد، Pandas به عنوان یک ابزار مفید به کار میآید؛ زیرا به طور ویژه برای استخراج و آمادهسازی دادهها توسعه یافته است. این کتابخانه ساختارهای داده سطح بالا و ابزارهای گوناگون برای تحلیل داده را فراهم میکند. Pandas از متدهای داخلی بسیاری برای گروهبندی، ترکیب و فیلتر کردن داده پشتیبانی میکند.
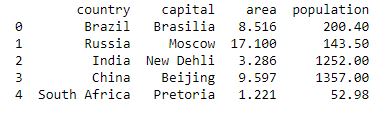
# Python program using Pandas for
# arranging a given set of data
# into a table
# importing pandas as pd
import pandas as pd
data = {"country": ["Brazil", "Russia", "India", "China", "South Africa"],
"capital": ["Brasilia", "Moscow", "New Delhi", "Beijing", "Pretoria"],
"area": [8.516, 17.10, 3.286, 9.597, 1.221],
"population": [200.4, 143.5, 1252, 1357, 52.98] }
data_table = pd.DataFrame(data)
print(data_table)
خروجی:
کتابخانه Pandas یکی از بهترین و پرکاربردترین ابزارهای پایتون برای تحلیل و پردازش دادهها است. این کتابخانه با ارائه ساختارهای دادهای کارآمد مثل DataFrame و Series، به کاربران کمک میکند بتوانند به راحتی دادههای ساختاریافته را مدیریت و تحلیل کنند. Pandas به طور ویژه برای کار با دادههای جدولی طراحی شده و ابزارهایی برای خواندن و نوشتن دادهها از فرمتهای مختلف مثل CSV، Excel، SQL و JSON ارائه میدهد. کاربران با استفاده از Pandas میتوانند کارهای پیچیده مثل فیلتر کردن، گروهبندی، تجمیع و تبدیل دادهها را خیلی راحت انجام دهند. این کتابخانه به دلیل سرعت بالا و انعطافپذیری که دارد به یکی از ابزارهای اصلی دانشمندان داده، تحلیلگران و برنامهنویسان تبدیل شده است.
یکی از ویژگیهای جذاب Pandas، سینتکس ساده و کاربرپسند آن است که یادگیری و استفاده از آن را برای افراد مبتدی و حرفهای امکانپذیر میکند. این کتابخانه با یکپارچهسازی با سایر کتابخانههای محبوب پایتون مثل NumPy، Matplotlib و Scikit-learn، امکان انجام تحلیلهای پیشرفته و بصری کردن دادهها را ارائه میدهد. برای مثال با استفاده از Pandas میتوان دادهها را در کمترین زمان ممکن پاکسازی و آماده کرد و سپس با کمک Matplotlib نمودارهای جذاب به وجود آورد. همچنین Pandas دارای قابلیتهای پیشرفته مثل ایندکسگذاری هوشمند، مدیریت دادههای گمشده و پشتیبانی از دادههای چندبعدی است. این ویژگیها باعث شده Pandas ابزاری ضروری برای هر پروژه دادهمحور در پایتون باشد.
مزایای کتابخانه Pandas
- رابط کاربری ساده و قوی: Pandas دارای یک API سطح بالا و قابل فهم است که به کاربران اجازه میدهد عملیات پیچیده را با کدنویسی ساده انجام دهند. این ویژگی باعث میشود حتی کاربران مبتدی هم خیلی راحت با آن کار کنند.
- ساختارهای دادهای قدرتمند: پانداس دو ساختار داده اصلی به نامهای DataFrame (جدول دو بعدی) و Series (آرایه یک بعدی) ارائه میدهد که برای سازماندهی و تحلیل دادهها بسیار مناسب هستند. این ساختارها امکان فیلتر کردن، گروهبندی و ادغام دادهها را فراهم میکنند.
- پشتیبانی از فرمتهای مختلف داده: Pandas میتواند دادهها را از فرمتهای مختلف مانند CSV، Excel، SQL، و JSON بخواند و بنویسد. این ویژگی آن را برای کار با منابع داده متنوع ایدهآل کرده است.
- یکپارچهسازی با کتابخانههای دیگر: این کتابخانه به خوبی با کتابخانههایی مثل NumPy، Matplotlib و Scikit-learn یکپارچه میشود.
- تحلیل سریع و کارآمد: با استفاده از عملیات برداری (vectorized operations)، Pandas میتواند دادههای بزرگ را به سرعت پردازش کند.
معایب کتابخانه Pandas
- مصرف حافظه زیاد: پانداس کل مجموعه داده را در حافظه بارگیری میکند و به همین دلیل برای دادههای بسیار بزرگ باعث بروز مشکلات عملکردی میشود.
- مقیاسپذیری محدود: این کتابخانه برای دادههایی که از حافظه سیستم فراتر میروند، گزینه مناسبی نیست و نیاز به ابزارهای تخصصیتر مانند Dask یا Apache Spark دارد.
- دارای مشکل یادگیری برای کاربران: با وجود اینکه Pandas برای کاربران مبتدی ساده است، اما برخی از ویژگیهای پیشرفته آن ممکن است برای کاربران حرفهای نیز چالشبرانگیز باشد.
- مستندات ضعیف: برخی کاربران گزارش میدهند که مستندات Pandas برای مبتدیان کافی نیست و ممکن است درک برخی ویژگیها را سخت کند.
- عدم پشتیبانی از دادههای سهبعدی: پانداس برای کار با دادههای دوبعدی (مانند جداول) طراحی شده و برای دادههای سهبعدی (مانند ماتریسهای چندبعدی) مناسب نیست.
امکانات اصلی Pandas
- تمیز کردن و پیشپردازش دادهها: ابزارهایی برای حذف دادههای تکراری، مدیریت مقادیر گمشده و تبدیل انواع دادهها دارد.
- تحلیل دادهها: امکان محاسبه آمار توصیفی (مانند میانگین، میانه، و انحراف معیار)، فیلتر کردن دادهها بر اساس شرایط خاص و گروهبندی دادهها را برای کاربران فراهم میکند.
- تحلیل سریهای زمانی: Pandas ابزارهای بسیار زیادی مثل تغییر فرکانس دادهها و محاسبه میانگین متحرک، برای کار با دادههای زمانی ارائه میدهد.
- تجسم دادهها: با وجو اینکه Pandas یک کتابخانه تجسم داده نیست، ولی با کتابخانههایی مثل Matplotlib و Seaborn یکپارچه میشود تا نمودارها و گرافهای مختلفی را به وجود بیاورد.
✔️ Matplotlib

Matplotlib یک کتابخانه بسیار محبوب در زبان پایتون برای تصویرسازی دادههاست و مانند Pandas، به یادگیری ماشین ارتباط مستقیم ندارد. این کتابخانه به طور ویژه، زمانی که یک برنامهنویس میخواهد الگوهای موجود در دادهها را تصویر کند بسیار مفید است.
Matplotlib برای ایجاد نمودارها و چارتهای دوبعدی به کار میرود. ماژول pyplot این امکان را به برنامهنویسان میدهد که به راحتی نمودارها را رسم کنند، زیرا این ابزار ویژگیهایی را برای کنترل استیل خطوط، خصوصیات فونت، قالببندی محورها و غیره فراهم میکند.
این کتابخانه انواع مختلفی از نمودارها و چارتها را برای تصویرسازی داده فراهم میکند، از جمله histogram، نمودارهای خطا، نمودارهای میلهای و غیره.
# Python program using Matplotlib # for forming a linear plot # importing the necessary packages and modules import matplotlib.pyplot as plt import numpy as np # Prepare the data x = np.linspace(0, 10, 100) # Plot the data plt.plot(x, x, label ='linear') # Add a legend plt.legend() # Show the plot plt.show()
خروجی:
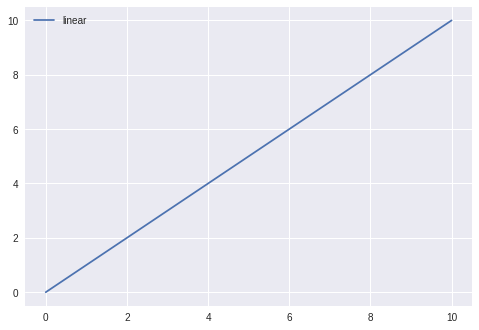
Matplotlib یک کتابخانه پرکاربرد در پایتون برای ایجاد نمودارها و تصاویر گرافیکی دو بعدی و سه بعدی است. این کتابخانه به دلیل انعطافپذیری بالا و قابلیتهای متنوع، به عنوان یکی از ابزارهای اصلی در حوزههای مختلفی مانند علوم داده، مهندسی، مالی و تحقیقات علمی مورد استفاده قرار میگیرد. Matplotlib امکان ایجاد انواع نمودارها مانند خطی، میلهای، هیستوگرام، پراکندگی و حتی نمودارهای سهبعدی را فراهم میکند. همچنین این کتابخانه قابلیت شخصیسازی زیادی دارد و به کاربران اجازه میدهد تا ظاهر نمودارها را به طور کامل کنترل کنند.
یکی از بارزترین قابلیتهای Matplotlib سازگاری آن با دیگر کتابخانههای محبوب پایتون مانند نامپای و Pandas است که باعث میشود دادهها به راحتی قابلیت تجزیه و تحلیل و نمایش داشته باشند. علاوه بر این، Matplotlib از چندین رابط کاربری (API) پشتیبانی میکند که شامل یک رابط شیگرا (Object-Oriented) و یک رابط مبتنی بر حالت (pyplot) است. این انعطافپذیری باعث میشود که هم کاربران مبتدی و هم حرفهای بتوانند از این کتابخانه به راحتی استفاده کنند. همچنین Matplotlib قابلیت ذخیرهسازی نمودارها در فرمتهای مختلف مانند PNG، PDF، SVG و سایر فرمتهای رایج را دارد و به همین دلیل که ابزاری بسیار مناسبی برای تولید گزارشها و ارائهها تبدیل است.
مزایای Matplotlib
- انعطافپذیری بالا: Matplotlib امکان ایجاد انواع مختلفی از نمودارها (خطی، میلهای، هیستوگرام، پراکندگی، سهبعدی و غیره) را ارائه میدهد.
- شخصیسازی پیشرفته: کاربران میتوانند تقریباً هر بخشی از نمودارها (مانند رنگها، فونتها، برچسبها و سبکها) را به دلخواه تغییر دهند.
- پشتیبانی از فرمتهای خروجی مختلف: با این کتابخانه نمودارها را میتوان در فرمتهای مختلفی مثل PNG، PDF، SVG و EPS ذخیره کرد.
- رابطهای کاربری متنوع: Matplotlib هم از یک رابط ساده (pyplot) برای کاربران مبتدی و هم از یک رابط شیگرا برای کاربران پیشرفته پشتیبانی میکند.
معایب Matplotlib
پیچیدگی در استفاده پیشرفته: کدنویسی آن میتواند برای ایجاد نمودارهای بسیار پیچیده یا سفارشیسازیهای پیشرفته طولانی و پیچیده شود.
عدم پشتیبانی پیشفرض از نمودارهای تعاملی: برای ایجاد نمودارهای تعاملی (مانند زوم یا کلیک)، نیاز به استفاده از کتابخانههای دیگری مثل Plotly یا Bokeh است.
ظاهر قدیمی: نمودارهای پیشفرض Matplotlib از نظر ظاهری کمی قدیمی به نظر میسند، هرچند با شخصیسازی میتوان این مشکل را از بین برد.
یادگیری دشوار: برای کاربران تازهکار، یادگیری تمام امکانات و تنظیمات Matplotlib کمی زمانبر است.
امکانات Matplotlib
- انواع نمودارها: پشتیبانی از نمودارهای خطی، میلهای، هیستوگرام، پراکندگی، دایرهای، کانتور و سهبعدی.
- شخصیسازی: امکان تغییر رنگها، خطوط، مارکرها، برچسبها، عنوانها، legend و سایر عناصر نمودار.
- پشتیبانی از LaTeX: امکان استفاده از نمادها و فرمولهای ریاضی در برچسبها و متنها.
- ذخیرهسازی نمودارها: قابلیت ذخیرهسازی نمودارها در فرمتهای مختلف تصویری و برداری.
- یکپارچهسازی با Jupyter Notebook: نمایش نمودارها بهصورت تعاملی در محیطهای Notebook.
- ابزارهای کمکی: ابزارهایی برای افزودن حاشیهنویسی (annotation)، خطوط راهنما و شبکهبندی به نمودارها.
- پشتیبانی از نمودارهای سهبعدی: امکان ایجاد نمودارهای سهبعدی با استفاده از ماژول mplot3d.
- پشتیبانی از تمها (Themes): امکان استفاده از تمهای از پیش تعریفشده برای تغییر سریع ظاهر نمودارها.

لیست دروس دوره
درس 1: شروع کار با یادگیری ماشین
درس 2: یادگیری ماشین چیست؟
درس 3: انواع یادگیری ماشین، چالش ها و کاربردهای آن
درس 4: معرفی داده در یادگیری ماشین
درس 5: بهترین کتابخانه های پایتون برای یادگیری ماشین
درس 6: جذاب ترین کاربردهای یادگیری ماشین
درس 7: تفاوت های یادگیری ماشین و هوش مصنوعی
درس 8: درک پردازش داده (Data Processing)
درس 9: تولید دادههای تست برای یادگیری ماشین
درس 10: پیش پردازش داده ها در پایتون
درس 11: پاکسازی داده ها و مراحل آن
درس 12: کدگذاری برچسب با پایتون
درس 13: روش کدبندی وان هات (One Hot Encoding)
درس 14: مقابله با دادههای نامتوازن
درس 15: یادگیری ماشین تحت نظارت
درس 16: طبقه بندی (Classification)
درس 17: انواع تکنیک های رگرسیون
درس 18: تفاوت الگوریتم های طبقه بندی و رگرسیون
درس 19: رگرسیون خطی
درس 20: پیاده سازی رگرسیون خطی در پایتون
درس 21: رگرسیون خطی تک متغیره در پایتون
درس 22: رگرسیون خطی چندگانه در پایتون
درس 23: رگرسیون خطی با کتابخانه sklearn
درس 24: رگرسیون خطی با استفاده از تنسورفلو (TensorFlow)
درس 25: رگرسیون خطی با استفاده از PyTorch
درس 26: Pyspark – رگرسیون خطی با استفاده از آپاچی MLlib
درس 27: چالش دیتاست مسکن بوستون با استفاده از رگرسیون خطی
درس 28: پیادهسازی رگرسیون چندجمله ای با پایتون از پایه
درس 29: پیاده سازی رگرسیون چندجمله ای با پایتون
درس 30: رگرسیون چندجملهای برای داده های غیرخطی
درس 31: پیاده سازی رگرسیون چندجمله ای با Turicreate
درس 32: رگرسیون لجستیک در یادگیری ماشین
درس 33: رگرسیون لجستیک با استفاده از پایتون
درس 34: رگرسیون لجستیک با استفاده از tensorflow
درس 35: رگرسیون سافت مکس (Softmax) با استفاده از Tensorflow
درس 36: رگرسیون Softmax با استفاده از Keras
درس 37: دسته بندی کننده های بیز ساده (Naive Bayes)
درس 38: پیادهسازی بیز ساده (Naive Bayes) با استفاده از پایتون
درس 39: الگوریتم مکمل بیز ساده (CNB)
درس 40: کاربرد بیز ساده چند جملهای در NLP
درس 41:الگوریتم ماشین بردار پشتیبان (SVM)
درس 42: دستهبندی دادهها با استفاده از SVMها در پایتون
درس 43: تنظیم پارامترهای SVM با استفاده از GridSearchCV
درس 44: ایجاد SVM با کرنل خطی در پایتون
درس 45: توابع کرنل اصلی در SVM
درس ۴۶: استفاده از SVM برای دستهبندی در یک مجموعه داده غیرخطی
درس 47: درخت تصمیم (Decision Tree) چیست؟
درس 48: پیادهسازی درخت تصمیم با پایتون
درس 49: استفاده از رگرسیون درخت تصمیم با استفاده از sklearn
درس 50: رگرسیون جنگل تصادفی در پایتون
درس 51: ساخت طبقهبندیکننده جنگل تصادفی با کتابخانه Scikit-Learn
آموزش پیشنهادی و مکمل: دوره جامع متخصص علم داده

سوالات متداول
1-پرکاربردترین کتابخانههای پایتون برای علم داده و یادگیری ماشین کدامند؟
بهترین کتابخانههای پایتون برای یادگیری ماشین شامل NumPy برای پردازش آرایهها و ماتریسها، Pandas برای آمادهسازی و تحلیل دادهها، Scikit-learn برای الگوریتمهای یادگیری ماشین و TensorFlow برای ساخت مدلهای هوش مصنوعی، به خصوص در یادگیری عمیق هستند. همچنین کتابخانههایی مانند Keras برای توسعه شبکههای عصبی، PyTorch برای انعطافپذیری و سرعت در یادگیری عمیق، Theano برای محاسبات عددی و بهینهسازی مدلهای ریاضی و Matplotlib برای مصورسازی دادهها نیز بسیار مفید می باشند. SciPy نیز برای محاسبات علمی و مهندسی و عملیات پیشرفتهتر مورد استفاده قرار میگیرد.
2-چه تفاوتی بین NumPy و Pandas در پردازش دادهها وجود دارد؟
NumPy و Pandas هر دو ابزارهای قدرتمند در پایتون برای کار با دادهها هستند، اما تفاوتهای کلیدی در ساختار داده و کاربرد دارند. NumPy عمدتاً برای کار با آرایههای چند بعدی و انجام محاسبات عددی سریع مناسب است. در مقابل Pandas برای تحلیل دادهها و پردازش دادههای ساختاریافته مانند جداول (DataFrames) طراحی شده و ابزارهایی برای پاکسازی، جستجو، مرتبسازی و تبدیل دادهها ارائه میدهد. به طور خلاصه NumPy برای محاسبات ریاضی و عملیات بر روی آرایهها بهینه شده، در حالی که Pandas برای تحلیل و دستکاری دادههای جدولی با انواع دادههای مختلف مناسبتر است.
3-TensorFlow و PyTorch چه تفاوتهایی دارند و کدام برای یادگیری عمیق بهتر است؟
TensorFlow و PyTorch هر دو فریمورکهای محبوب برای یادگیری عمیق هستند، اما تفاوتهای کلیدی دارند. TensorFlow، توسعهیافته توسط گوگل، به دلیل مقیاسپذیری و پشتیبانی قوی در صنعت شناخته شده است و برای پروژههای بزرگ و پیچیده مناسب است. از طرف دیگر PyTorch، توسعهیافته توسط متا (فیسبوک)، به دلیل انعطافپذیری، سادگی و گراف محاسباتی پویا، در بین محققان و برای پروژههای تحقیقاتی محبوبیت بیشتری دارد. انتخاب بین این دو بستگی به نیازهای خاص پروژه، میزان آشنایی با هر فریمورک و اهمیت سهولت استفاده و انعطافپذیری دارد57. TensorFlow از نسخه 2 به بعد بسیاری از ویژگیهای PyTorch را پذیرفته و استفاده از آن سادهتر شده است.
4-بهترین کتابخانههای پایتون برای پردازش تصویر و بینایی کامپیوتر کدامند؟
بهترین کتابخانههای پایتون برای پردازش تصویر و بینایی کامپیوتر شامل OpenCV-Python به دلیل سرعت بالا و تسهیل پیادهسازی برنامههای بینایی کامپیوتر، Scikit-Image برای ارائه الگوریتمها و ابزارهای پردازش تصویر در کاربردهای تحقیقاتی، آموزشی و صنعتی و Pillow به عنوان یک کتابخانه قدرتمند و کاربرپسند برای پردازش و دستکاری تصاویر است. Mahotas نیز برای توابع پردازش تصویر مرسوم و توابع بینایی کامپیوتر مدرن جهت محاسبه ویژگی مناسب میباشد. SimpleCV نیز به عنوان یک چارچوب منبع باز برای ایجاد برنامههای بینایی کامپیوتری با پردازش تصویر معرفی شده است.