

در درس چهارم از آموزش رایگان یادگیری ماشین با پایتون می خواهیم به معرفی داده در یادگیری ماشین بپردازیم.
معرفی داده در یادگیری ماشین
در دنیای داده در یادگیری ماشین، داده یک عنصر حیاتی و تعیین کننده است. داده یعنی مجموعه ای از مشاهدات و اندازه گیری هایی که بتوان از آن ها برای آموزش یک مدل یادگیری ماشین استفاده کرد. تعداد و کیفیت داده ای که برای آموزش و تست مدل در اختیار داریم، نقش مهمی در کارآیی مدل یادگیری ماشین ما دارد.
داده میتواند به اشکال مختلفی مانند دادههای عددی، دادههای غیر عددی یا دادههای سری زمانی باشد. همچنین میتواند از منابع مختلفی مانند پایگاههای داده، صفحههای گسترده وب یا رابطهای برنامهنویسی (API) به دست آید.
الگوریتمهای یادگیری ماشین از دادهها برای یاد گرفتن الگوها و روابط بین متغیرهای ورودی و خروجیهای هدف استفاده میکنند؛ سپس این الگوها برای وظایف پیشبینی یا طبقهبندی، قابل استفاده هستند. برای درک بهتر میتوانید آموزش رایگان پایتون را مطالعه کنید.
انواع داده
دادهها را در یادگیری ماشین می توان به دو دسته تقسیم کرد:
1- داده برچسبدار
2- داده بدون برچسب
دادههای برچسبدار شامل یک برچسب یا متغیر هدف هستند که مدل سعی در پیشبینی آن متغیر دارد، در حالی که دادههای بدون برچسب هیچ برچسب یا متغیر هدفی ندارند.
دادههای استفاده شده در یادگیری ماشین به طور معمول عددی یا غیر عددی هستند. دادههای عددی مانند سن یا درآمد، داده هایی هستند که می توان آن ها را اندازه گیری و مرتب کرد. داده های غیرعددی مانند جنسیت یا نام میوه ها، گروه یا طبقه مقادیر را نشان می دهند.
در یادگیری ماشین می توان دادهها را به دو زیرمجموعه آموزش و تست تقسیم کرد. مجموعه آموزش برای آموزش مدل و مجموعه تست برای ارزیابی عملکرد مدل استفاده میشود.
نکته مهم این است که باید داده های خود را به طور تصادفی به این دو زیرمجموعه تقسیم کنیم. همچنین داده در یادگیری ماشین موجود در هر یک از این زیرمجموعه ها، باید نمایانگر مجموعه داده ها در حوزه مورد بررسی بوده و قادر به بازتولید الگوها و روابط موجود در مجموعه داده ها باشند (representative).
پیشپردازش داده مرحلهای مهم در فرآیند یادگیری ماشین است. این مرحله میتواند شامل تمیزکردن و نرمالسازی دادهها، مدیریت مقادیر از دست رفته (missing values) و انتخاب یا مهندسی ویژگیها (feature engineering) باشد.
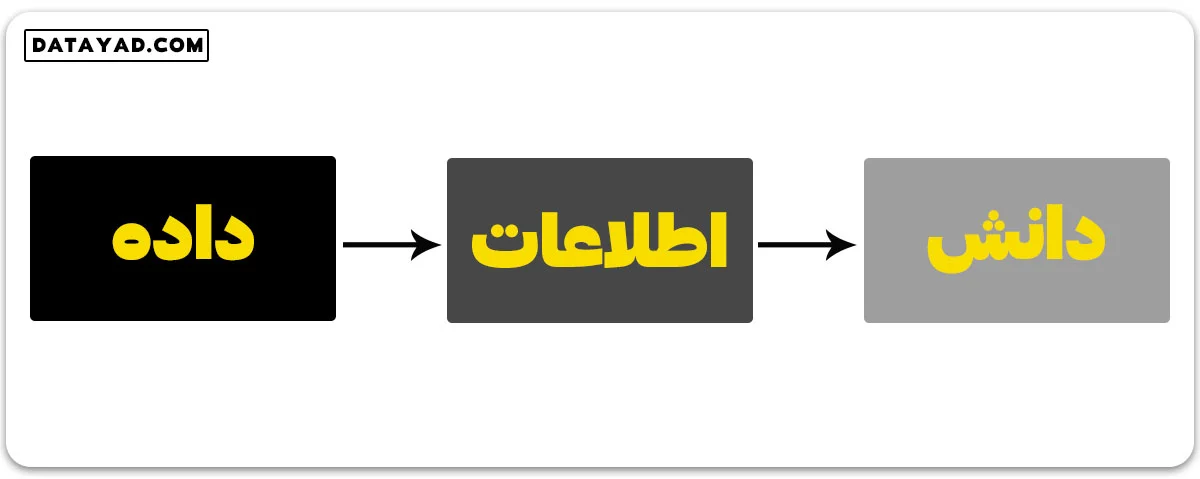
داده: میتواند هر نکته، مقدار، متن، صوت یا تصویر پردازش نشده ای باشد که هنوز تفسیر و تحلیل نشده است.
مهم ترین بخش در تجزیه و تحلیل داده، یادگیری ماشین و هوش مصنوعی داده است. بدون داده، نمیتوانیم هیچ مدلی را آموزش دهیم و تمامی پژوهشها و اتوماسیونهای مدرن بیهوده خواهند بود. شرکتهای بزرگ هزینههای زیادی را صرف جمعآوری هر چه بیشتر دادههای مطمئن میکنند. اگر به دنبال کسب اطلاعات بیشتر هستید پیشنهاد میکنیم یادگیری عمیق با پایتون را مطالعه کنید.
مثال: چرا فیسبوک واتساپ را با هزینه هنگفت 19 میلیارد دلار خریداری کرد؟
پاسخ بسیار ساده و منطقی است؛ به منظور دسترسی به اطلاعات آن دسته از کاربران واتس اپ که عضو فیس بوک نیستند. این اطلاعات ارتقای سرویس دهی را برای فیسبوک تسهیل می کند و به همین دلیل برای آن ها بسیار ارزشمند است.
اطلاعات: دادهای است که دستکاری و تفسیر شده تا برای کاربران، نتایج ملموس و معناداری داشته باشد.
دانش: ترکیبی از اطلاعات استنتاجی، تجربیات، یادگیری و بینشها است. دانش منجر به آگاهی بخشی یا ساخت مفاهیم برای یک فرد یا سازمان میشود. اگر به دنبال کسب اطلاعات بیشتر هستید آموزش رایگان یادگیری ماشین با پایتون را مطالعه کنید.

نحوه تقسیم بندی داده در یادگیری ماشین چگونه است؟
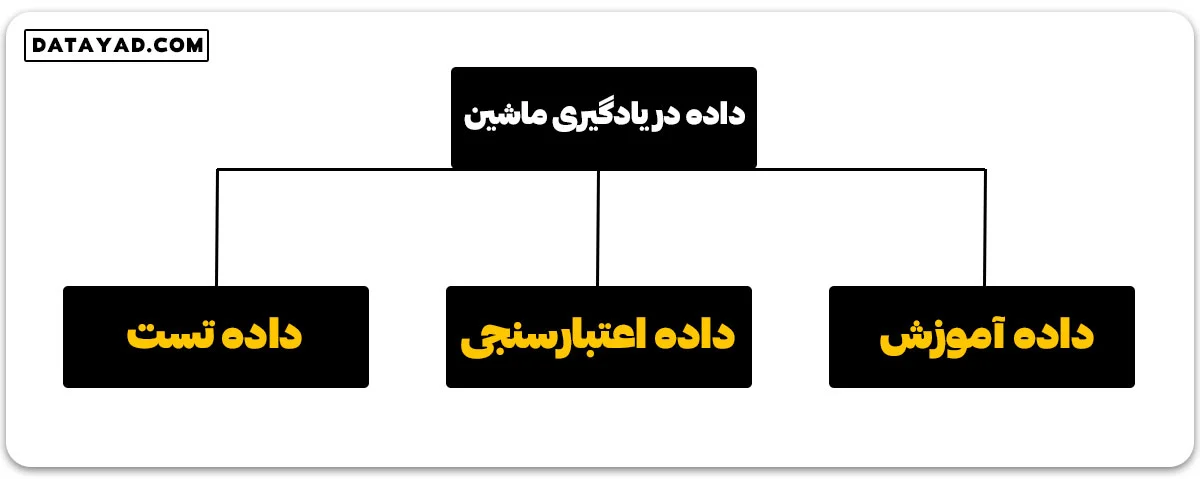
🟢 داده آموزش (training data)
بخشی از داده است که از آن برای آموزش مدل استفاده می کنیم و همان داده ایست که مدل شما در واقع میبیند (هم ورودی و هم خروجی) و از آن یاد میگیرد.
🟢 داده اعتبارسنجی (validation data)
بخشی از داده که برای ارزیابی مکرر مدل استفاده میشود و همراه با مجموعه داده آموزش می تواند هایپرپارامترها (پارامترهایی که در ابتدا و پیش از شروع یادگیری مدل تنظیم می شوند) را بهبود دهد. این داده در حین آموزش مدل ایفای نقش میکند.
🟢 داده تست (testing data)
بعد از اینکه مدل ما به طور کامل آموزش دید، دادههای تست امکان ارزیابی بیطرفانه و بدون سوگیری را فراهم میکنند. هنگامی که داده های تست را به عنوان ورودی به مدل میدهیم، مدل ما بدون دیدن خروجی واقعی مقادیری را پیشبینی میکند. سپس می توانیم پیش بینی های مدل را با خروجی واقعی موجود در داده تست مقایسه کنیم. بدین ترتیب می توانیم مدل خود را ارزیابی کرده و دریابیم چقدر از تجربیاتی که در داده آموزش و در زمان یادگیری وارد مدل کردهایم، یاد گرفته است.
به عنوان نمونه، مثال زیر را در نظر بگیرید:
صاحب یک فروشگاه طی یک نظرسنجی از مشتریان خود، لیستی بلند بالا از پرسش و پاسخهایی که مشتریان داده اند را ثبت کرده است. در این مثال، لیست پرسش و پاسخ ها “داده” است.
حالا این صاحب فروشگاه نمی تواند برای جستجوی نتیجه ای خاص و یا برنامه ریزی برای آینده کسب و کار خود، هربار سراغ این لیست انبوه برود و از بین تعداد زیادی سوال، دنبال نتیجه مورد نظر خود بگردد. زیرا این کار علاوه بر زمان بر بودن، فایده ای هم ندارد.
برای سهولت، کاهش هزینه و جلوگیری از اتلاف زمان، داده از طریق نرمافزارها، محاسبات، نمودارها و… دستکاری می شود. استنتاجی که از این دادههای تغییر یافته به دست میآید، “اطلاعات” است. بنابراین، داشتن داده برای به دست آوردن اطلاعات ضروری است.
حالا نقش “دانش”، تمایز قائل شدن بین افرادی با اطلاعات یکسان است. دانش در واقع محتوای فنی نیست، بلکه به فرآیند تفکر انسان مربوط است.توجه داشته باشید که مطالعه مهم ترین کاربرد های پایتون برای افزایش مهارتهای شما و کسب اطلاعات جدید خالی از لطف نیست.
به نقل از وب سایت geeksforgeeks:
در یادگیری ماشین، دادهها به سه دسته اصلی تقسیم میشوند:
دادههای آموزشی (Training Data): این بخش از دادهها برای آموزش مدل استفاده میشود و مدل با استفاده از این دادهها الگوها و روابط میان ورودیها و خروجیها را یاد میگیرد.
دادههای اعتبارسنجی (Validation Data): این دادهها برای ارزیابی مکرر مدل در حین آموزش به کار میروند و به بهبود هایپرپارامترها (پارامترهای اولیه مدل) کمک میکنند. این مجموعه به ما اجازه میدهد تا عملکرد مدل را در حین آموزش پایش کنیم.
دادههای تست (Testing Data): پس از اینکه مدل به طور کامل آموزش دید، دادههای تست برای ارزیابی بیطرفانه عملکرد آن استفاده میشوند. با وارد کردن ورودیهای این دادهها، مدل پیشبینیهایی انجام میدهد که سپس با خروجیهای واقعی مقایسه میشود تا کیفیت یادگیری مدل سنجیده شود.

انواع مختلف دادهها
🟢 دادههای عددی: اگر یک ویژگی نشاندهنده یک خاصیت اندازهگیری شده به صورت اعداد باشد، به آن ویژگی عددی گفته میشود.
🟢 دادههای غیر عددی: یک ویژگی کیفی است که میتواند از بین تعدادی محدود و معمولا ثابت از حالت های توصیف کننده کیفی، مقدار بگیرد.
🟢 دادههای ترتیبی: این نوع داده به متغیری نامی اشاره دارد که دستههای آن در یک لیست دارای ترتیب قرار میگیرند. سایزهای لباس مانند کوچک، متوسط و بزرگ و یا اندازهگیری رضایت مشتری در مقیاسی از “کاملا ناراضی” تا “کاملا راضی” مثال هایی از این داده ها هستند.
انواع داده ها در یادگیری ماشین (به شکل جدول)
| دستهبندی اصلی داده | زیرمجموعه | توضیحات | مثال |
| دادههای نظارتشده (Supervised Data) | برچسبدار (Labeled Data) | دادههایی که شامل ورودی و خروجی مشخص هستند و مدل رابطه بین آنها را یاد میگیرد. | تصاویر دستنویس اعداد با برچسب مقدار عددی |
| دادههای بدون نظارت (Unsupervised Data) | بدون برچسب (Unlabeled Data) | دادههایی که فقط شامل ورودی هستند و خروجی مشخصی ندارند، مدل الگوها را پیدا میکند. | مجموعهای از نظرات کاربران بدون دستهبندی |
| نوع داده (Data Type) | عددی (Numerical) | دادههایی که میتوان آنها را اندازهگیری و مرتب کرد. | دما، درآمد، سن، وزن |
| نوع داده (Data Type) | غیر عددی (Categorical) | دادههایی که گروهبندی میشوند اما مقدار عددی ندارند. | رنگ چشم، نام شهر، نوع خودرو |
| مجموعه داده (Dataset) | آموزشی (Training Set) | دادههایی که برای آموزش مدل استفاده میشود (معمولاً ۷۰٪ تا ۸۰٪ از کل دادهها). | تصاویر دستنویس برای یادگیری مدل |
| مجموعه داده (Dataset) | تست (Testing Set) | دادههایی که برای ارزیابی عملکرد مدل استفاده میشود (معمولاً ۲۰٪ تا ۳۰٪ از دادهها). | تصاویر جدید برای سنجش مدل |
| مجموعه داده (Dataset) | اعتبارسنجی (Validation Set) | دادههایی که برای تنظیم پارامترهای مدل و جلوگیری از بیشبرازش استفاده میشود. | مجموعهای جدا از دادههای تست برای تنظیم مدل |
| دادههای نیمهنظارتی (Semi-Supervised Data) | ترکیبی از برچسبدار و بدون برچسب | دادههایی که بیشتر نمونهها بدون برچسب هستند اما تعداد کمی از آنها دارای برچسباند. | مقالات علمی با برچسبگذاری محدود برای دستهبندی خودکار |
| دادههای یادگیری تقویتی (Reinforcement Data) | دادههای مربوط به پاداش و اقدام (Reward-Based Data) | دادههایی که از تعامل عامل با محیط و دریافت پاداش یا جریمه ایجاد میشوند. | اطلاعات بازیهای ویدیویی برای آموزش هوش مصنوعی |
“به نقل از وب سایت geeksforgeeks: دادهها در یادگیری ماشین بر اساس ساختار به سه نوع اصلی تقسیم میشوند:
- دادههای ساختاریافته: این نوع دادهها به صورت منظم و در قالب جدولی (سطرها و ستونها) سازماندهی و ذخیره میشوند. این دادهها معمولاً در پایگاههای داده و صفحات گسترده وجود دارند. مثالهایی از این دادهها شامل سوابق فروش، اطلاعات مشتری و معاملات مالی هستند. این نوع دادهها در وظایف یادگیری نظارتشده مانند رگرسیون و طبقهبندی مفید هستند.
- دادههای بدون ساختار: این دادهها فاقد یک فرمت تعریفشده هستند که پردازش آنها را دشوارتر میکند. مثالهایی از این نوع دادهها شامل اسناد متنی، تصاویر، ویدئوها و فایلهای صوتی هستند. این دادهها در کاربردهایی مانند شناسایی تصویر، پردازش زبان طبیعی و سیستمهای تبدیل گفتار به متن یافت میشوند.
- دادههای نیمهساختاریافته: این نوع دادهها بین دادههای ساختاریافته و بدون ساختار قرار دارند. این دادهها عناصر سازمانی دارند اما بهطور کامل در یک فرمت جدولی قرار نمیگیرند. مثالهایی از این دادهها شامل فایلهای JSON، فایلهای XML و پایگاههای داده NoSQL هستند. این نوع دادهها معمولاً در وباسکرپینگ، پاسخهای API و تحلیل رسانههای اجتماعی استفاده میشوند.”
ویژگی های داده چیست؟
1- حجم: مقیاس داده. با رشد جمعیت جهان و فناوری های در دسترس، در هر لحظه حجم بسیار زیادی داده تولید میشود.
2- تنوع: اَشکال مختلف دادهها مانند داده های حوزه بهداشت، تصاویر، فیلمها، کلیپهای صوتی و… .
3- سرعت: نرخ جریان و تولید داده.
4- ارزش: معناداری دادهها از نظر اطلاعاتی که پژوهشگران میتوانند از آن داده ها استخراج کنند.
5- صحت: قطعیت و صحت دادههایی که روی آن کار میکنیم.
6- قابلیت اجرا: قابلیت استفاده و یکپارچهسازی داده در سیستمها و فرآیندهای مختلف.
7- امنیت: تدابیری که برای محافظت از داده در برابر دسترسی یا تغییرات غیرمجاز اتخاذ میشود.
8- دسترسیپذیری: آسانی به دست آوردن و استفاده از دادهها برای اهداف تصمیمگیری.
9- تمامیت: دقت و کامل بودن داده در طول عمر آن.
10- قابلیت استفاده: سهولت استفاده و تفسیر داده برای کاربران نهایی.
حقایقی درباره داده
🟢 تا سال 2020 حدود 300 برابر یعنی 40 زتابایت (1 زتابایت = 10 به توان 21 بایت) داده نسبت به سال 2005 تولید خواهد شد.
🟢 تا سال 2011، بخش بهداشت دادههایی به میزان 161 بیلیون گیگابایت داشته است.
🟢 روزانه حدود 400 میلیون توییت توسط حدود 200 میلیون کاربر فعال ارسال میشود.
🟢 هر ماه، کاربران بیش از 4 میلیارد ساعت ویدیو استریم میکنند.
🟢 هر ماه، کاربران حدود 30 میلیارد نوع محتوا را به اشتراک میگذارند.
🟢 گزارش شده است که حدود 27٪ از دادهها به اندازه کافی دقیق نیستند و بنابراین از هر سه رهبر یا ایده پرداز در کسب و کارها، یک نفر به اطلاعاتی که بر اساس آن تصمیم می گیرد اعتماد ندارد.
این ها تنها بخشی از آمار عظیم موجود درباره داده هاست. در عمل اندازه دادههای موجود و داده های در حال تولید در هر لحظه به حدی بزرگ است که برای ما قابل تصور نیست!
به نقل از وب سایت geeksforgeeks:
تولید داده به طور تصاعدی رشد کرده و اهمیت آن را در چشمانداز دیجیتال امروزی نشان میدهد. تا سال 2020، تولید داده جهانی در مقایسه با سال 2005، 300 برابر افزایش یافته و به 40 زتابایت رسید. بخش مراقبتهای بهداشتی در سال 2011 به تنهایی 161 میلیارد گیگابایت داده جمعآوری کرد. روزانه 400 میلیون توییت توسط 200 میلیون کاربر فعال ارسال میشود و ماهانه بیش از 4 میلیارد ساعت محتوای ویدیویی استریم میشود. کاربران ماهانه 30 میلیارد محتوای منحصر به فرد را به اشتراک میگذارند. با این حال، حدود 27 درصد از دادهها نادرست هستند و در نتیجه از هر 3 رهبر کسبوکار 1 نفر به اطلاعاتی که برای تصمیمگیری به آن تکیه میکنند، اعتماد ندارند. این ارقام تنها نگاهی اجمالی به حجم و پیچیدگی عظیم دادههای تولید شده در هر لحظه ارائه میدهند. مقیاس محض دادهها امروزه فراتر از درک است و بر نقش حیاتی آن در تجزیه و تحلیل، یادگیری ماشین و هوش مصنوعی تأکید میکند.
مثال:
تصور کنید در حال کار برای یک شرکت خودروسازی هستید و میخواهید مدلی بسازید که بتواند با توجه به وزن و اندازه موتور، بهرهوری سوخت خودرو را پیشبینی کند. در این حالت، متغیر هدف (برچسب) بهرهوری سوخت است و ویژگیها (متغیرهای ورودی) وزن و اندازه موتور هستند.
برای مدلسازی این مسأله ابتدا باید از مدلهای مختلف خودرو، به همراه وزن و اندازه موتور مربوطه و بهرهوری سوخت آنها، داده جمعآوری کنید.
این دادهها باید دارای برچسب و برای هر خودرو به صورت (وزن، اندازه موتور، بهرهوری سوخت) باشند. پس از آماده شدن دادهها، آنها را به دو مجموعه آموزش و تست تقسیم می کنیم.
مجموعه آموزش برای آموزش مدل و مجموعه تست برای ارزیابی عملکرد مدل استفاده میشود. همچنین ممکن است نیاز به پیشپردازش داده داشته باشید؛ به عنوان مثال برای پر کردن مقادیر گمشده یا برطرف کردن داده های پرت که ممکن است دقت مدل را تحت تأثیر قرار دهند.
پیادهسازی:
مثال: ۱
# Example input data from sklearn.linear_model import LogisticRegression X = [[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]] y = [0, 0, 1, 1, 1] # Train a model model = LogisticRegression() model.fit(X, y) # Make a prediction prediction = model.predict([[6, 7]])[0] print(prediction)
خروجی: 1
اگر این کد را اجرا کنید، مقادیر پیشبینی شده توسط مدل را به عنوان خروجی خواهد دید. در این حالت، خروجی مربوطه بسته به پارامترهای خاصی که مدل در طول آموزش یاد گرفته است، ۰ یا ۱ خواهد بود.
به عنوان مثال، اگر مدل یاد بگیرد که در صورت بیشتر بودن ورودی دوم نسبت به ورودی اول برای یک داده خاص، برچسب خروجی با احتمال بیشتری ۱ است، برای داده ورودی [۶، ۷] برچسب ۱ را پیش بینی خواهد کرد.
مزایای استفاده از داده در یادگیری ماشین
🟢 دقت بهتر: هر چه داده های بیشتری استفاده کنیم، الگوریتمهای یادگیری ماشین میتوانند روابط پیچیدهتری بین ورودیها و خروجیها یاد بگیرند که منجر به دقت بالاتر در پیشبینی و طبقهبندی میشود.
🟢 اتوماسیون: مدلهای یادگیری ماشین میتوانند فرآیندهای تصمیمگیری را اتوماتیک کنند و وظایف تکراری را به طور موثرتر و دقیقتر از انسانها انجام دهند.
🟢 شخصیسازی: با استفاده از داده، الگوریتمهای یادگیری ماشین میتوانند تجربیات را برای هر کاربر شخصیسازی کنند که این منجر به افزایش رضایت کاربر میشود.
🟢 صرفهجویی در هزینه: اتوماسیون حاصل از یادگیری ماشین با کاهش نیاز به نیروی کار انسانی و افزایش کارایی میتواند منجر به صرفهجویی در هزینه برای کسبوکارها شود. در نتیجه کسبوکارها می توانند با استفاده از یادگیری ماشین، فرآیندهای خود را به صورت اتوماتیک و با کمترین تداخل انسانی انجام دهند.
“به نقل از وب سایت geeksforgeeks: دادهها مزایای بسیار زیادی در یادگیری ماشین دارند. حجم بالای دادهها به الگوریتمهای یادگیری ماشین کمک میکند تا روابط پیچیدهتری بین ورودیها و خروجیها یاد بگیرند و در نتیجه دقت پیشبینیها و طبقهبندیها بهبود مییابد. مدلهای یادگیری ماشین میتوانند فرآیندهای تصمیمگیری را خودکار کرده و وظایف تکراری را با کارایی و دقت بیشتری نسبت به انسانها انجام دهند. با استفاده از دادهها، الگوریتمهای یادگیری ماشین میتوانند تجربهها را برای کاربران شخصیسازی کرده و رضایت آنها را افزایش دهند. در نهایت اتوماسیون از طریق یادگیری ماشین میتواند منجر به صرفهجویی در هزینهها برای کسبوکارها شود، زیرا نیاز به نیروی کار دستی کاهش مییابد و کارایی افزایش پیدا میکند.”
معایب استفاده از داده در یادگیری ماشین
🟢 سوگیری (بایاس): دادههای استفاده شده برای آموزش مدلهای یادگیری ماشین ممکن است سوگیری داشته باشند که این منجر به سوگیری در پیشبینیها و طبقهبندیهای مدل میشود.
🟢 حریم خصوصی: جمعآوری و ذخیره داده برای یادگیری ماشین میتواند نگرانی هایی در مورد حریم خصوصی ایجاد کند و اگر داده به درستی امن نشود، می تواند مشکلات امنیتی به همراه داشته باشد.
🟢 کیفیت داده: کیفیت داده استفاده شده برای آموزش مدلهای یادگیری ماشین برای عملکرد مدل حیاتی است. کیفیت پایین داده میتواند منجر به پیشبینیها و طبقهبندیهایی با دقت پایین شوند.
🟢 تفسیر پذیری اندک: برخی مدلهای یادگیری ماشین ممکن است آن قدر پیچیده باشند که تفسیر آن ها و درک اینکه بر چه مبنایی تصمیم می گیرند، بسیار چالش برانگیز باشد.
“به نقل از وب سایت geeksforgeeks: کیفیت داده یکی از بزرگترین چالشها در استفاده از دادهها در یادگیری ماشین است، زیرا باید اطمینان حاصل شود که دادهها دقیق، کامل و نماینده حوزه مسئله هستند. دادههای با کیفیت پایین میتوانند منجر به مدلهای نادرست یا دارای سوگیری شوند. همچنین در برخی موارد ممکن است داده کافی برای آموزش یک مدل یادگیری ماشین دقیق وجود نداشته باشد، به ویژه در مسائل پیچیده که نیاز به حجم بالایی از دادهها دارند تا الگوها و روابط مرتبط به درستی شناسایی شوند. مدلهای یادگیری ماشین میتوانند سوگیری و تبعیض را تداوم بخشند اگر دادههای آموزشی دارای سوگیری یا غیرنماینده باشند، که این امر میتواند منجر به نتایج ناعادلانه برای برخی گروهها مانند اقلیتها یا زنان شود.
مشکل دیگری که وجود دارد، افزودگی بیش از حد (Overfitting) و کمبود تناسب (Underfitting) است؛ افزودگی بیش از حد زمانی رخ میدهد که مدل بسیار پیچیده باشد و به دادههای آموزشی بیش از حد نزدیک شود، در حالی که کمبود تناسب زمانی اتفاق میافتد که مدل خیلی ساده باشد و نتواند تمامی الگوهای مرتبط را در دادهها شناسایی کند. علاوه بر این نگرانیهایی درباره حریم خصوصی و امنیت نیز وجود دارد، زیرا مدلهای یادگیری ماشین ممکن است به اطلاعات حساس درباره افراد یا سازمانها دست یابند.”

کاربردهای یادگیری ماشین
یادگیری ماشین یک ابزار قدرتمند است که میتواند در کاربردهای بسیاری مورد استفاده قرار گیرد. برخی از کاربردهای رایج یادگیری ماشین عبارتند از:
☑️ مدلسازی پیشبینی کننده (predictive modeling)
یادگیری ماشین میتواند برای ساخت مدلهای پیشبینی کننده استفاده شود که بر اساس دادههای قبلی، قادر به پیشبینی نتایج آینده هستند. این مدل ها در موارد بسیاری مانند پیشبینی بازار سهام، تشخیص تقلب، پیشبینی آب و هوا و پیشبینی رفتار مشتریان استفاده میشوند.
☑️ تشخیص تصویر (image recognition)
از یادگیری ماشین می توان برای آموزش مدلهایی استفاده کرد که قادر به تشخیص اشیا، چهرهها و الگوهای دیگر در تصاویر باشند. این مدل ها در کاربردهای بسیاری مانند خودروهای خودران، سیستمهای تشخیص چهره و تجزیه و تحلیل تصاویر پزشکی استفاده میشوند.
☑️ پردازش زبان طبیعی (natural language processing)
یادگیری ماشین میتواند در تجزیه و تحلیل و درک زبان طبیعی به کار رود که در موارد بسیاری مانند چتباتها، دستیارهای صوتی و تجزیه و تحلیل احساسات کاربرد دارد.
☑️ سیستمهای توصیه گر (recommendation systems)
یادگیری ماشین میتواند برای ساخت سیستمهای توصیه گر استفاده شود. این سیستم ها بر اساس رفتار یا ترجیحات گذشته کاربران، محصولات، خدمات و یا محتوای خاصی را به آنها پیشنهاد میدهند.
☑️ آنالیز داده
یادگیری ماشین میتواند برای تجزیه و تحلیل مجموعه داده های بزرگ و شناسایی الگوها و برداشتهایی که برای انسانها سخت یا غیرممکن است، استفاده شود.
☑️ رباتیک
یادگیری ماشین را می توان برای آموزش رباتها جهت انجام وظایفی مانند ناوبری در مکان یا دستکاری اشیاء به صورت خودکار، به کار برد.
همچنین می توانید برای ساخت ربات تلگرام از Python استفاده کنید.
مشکلات استفاده از داده در یادگیری ماشین
☑️ کیفیت داده
یکی از بزرگترین مشکلات استفاده از داده در یادگیری ماشین، اطمینان از دقت و کمال داده هاست. همچنین ارزیابی این که داده ها نمایانگر خوبی برای حوزه مورد بررسی هستند یا خیر، دشوار است. دادههای بی کیفیت ممکن است باعث تولید مدل هایی با دقت پایین و یا دارای سوگیری شوند.
☑️ تعداد داده
در برخی موارد، ممکن است دادههای کافی برای آموزش یک مدل یادگیری ماشین دقیق وجود نداشته باشد. این موضوع به ویژه در مسائل پیچیده ای که در آن ها برای درک تمامی الگوها و روابط موجود نیاز به حجم بزرگی از داده باشد، دردسرساز است.
☑️ سوگیری و عدالت
در صورتی که داده های استفاده شده در فاز آموزش مدل دارای سوگیری بوده و یا نماینده خوبی برای حوزه مورد بررسی نباشند، ممکن است مدل آموزش داده شده در تصمیم گیری های خود سوگیری و تبعیض نشان دهد. این مشکل میتواند منجر به نتایج ناعادلانه برای برخی گروهها مانند اقلیتها یا زنان شود.
☑️ بیش برازش (overfitting) و کم برازش (underfitting)
بیش برازش زمانی رخ میدهد که پیچیدگی مدل نسبت به تعداد داده و مسأله پیش رو زیاد باشد و مدل بیش از حد خود را با الگوهای خاص موجود در داده آموزش تطبیق دهد. چنین مدلی در مواجهه با داده های جدید عملکرد ضعیفی داشته و تعمیم پذیر نخواهد بود. برعکس این حالت کم برازش است؛ در این حالت مدل نسبت به مسأله و تعداد داده ها آن قدر ساده است که نمی تواند الگوها و روابط موجود در داده ها را درک کند.
☑️ حریم خصوصی و امنیت
مدلهای یادگیری ماشین گاهی میتوانند اطلاعات حساس درباره افراد یا سازمانها را استنباط کنند که این منجر به ایجاد نگرانی هایی در حوزه حریم خصوصی و امنیت میشود.
☑️ تفسیرپذیری
درک و تفسیر برخی مدلهای یادگیری ماشین مانند شبکههای عصبی عمیق می تواند بسیار دشوار باشد. این موضوع باعث میشود برای توضیح دلیل تصمیم گیری ها و پیش بینی های مدل با چالش مواجه شویم.

پاکسازی داده ها
پاکسازی داده در یادگیری ماشین یک فرآیند کلیدی و بسیار مهم در تحلیل دادهها است که شامل شش مرحله اساسی میباشد. در ابتدا ارزیابی کیفیت داده انجام میشود تا نقاط ضعف و مشکلات موجود شناسایی شوند. سپس در مرحله حذف موارد تکراری یا نامناسب، دادههای تکراری و بیربط از مجموعه حذف میشوند تا دقت و کارایی افزایش یابد. در ادامه اصلاح اشتباهات ساختاری صورت میگیرد که شامل برطرف کردن ناهماهنگیها در فرمتهای مختلف دادههای ساختاریافته و غیرساختاریافته است. پس از آن اصلاح انحرافات با شناسایی و حذف مقادیر غیرمعمول انجام میشود. مرحله بعدی بررسی دادههای گمشده است که در آن دادههای ناقص شناسایی و روشهایی برای مدیریت آنها به کار گرفته میشود.
در نهایت اعتبارسنجی دادههای پاکسازی شده صورت میگیرد تا اطمینان حاصل شود که دادهها به درستی پاکسازی شدهاند و با یک دیتابیس مرجع مقایسه میشوند. این مراحل به بهبود کیفیت دادهها کمک کرده و برای تحلیلهای دقیقتر و قابل اعتمادتر ضروری هستند. برای درک بهتر میتوانید آموزش رایگان شبکه عصبی را مطالعه کنید.
لیست دروس دوره یادگیری ماشین با پایتون
درس 1: شروع کار با یادگیری ماشین
درس 2: یادگیری ماشین چیست؟
درس 3: انواع یادگیری ماشین، چالش ها و کاربردهای آن
درس 4: معرفی داده در یادگیری ماشین
درس 5: بهترین کتابخانه های پایتون برای یادگیری ماشین
درس 6: جذاب ترین کاربردهای یادگیری ماشین
درس 7: تفاوت های یادگیری ماشین و هوش مصنوعی
درس 8: درک پردازش داده (Data Processing)
درس 9: تولید دادههای تست برای یادگیری ماشین
درس 10: پیش پردازش داده ها در پایتون
درس 11: پاکسازی داده ها و مراحل آن
درس 12: کدگذاری برچسب با پایتون
درس 13: روش کدبندی وان هات (One Hot Encoding)
درس 14: مقابله با دادههای نامتوازن
درس 15: یادگیری ماشین تحت نظارت
درس 16: طبقه بندی (Classification)
درس 17: انواع تکنیک های رگرسیون
درس 18: تفاوت الگوریتم های طبقه بندی و رگرسیون
درس 19: رگرسیون خطی
درس 20: پیاده سازی رگرسیون خطی در پایتون
درس 21: رگرسیون خطی تک متغیره در پایتون
درس 22: رگرسیون خطی چندگانه در پایتون
درس 23: رگرسیون خطی با کتابخانه sklearn
درس 24: رگرسیون خطی با استفاده از تنسورفلو (TensorFlow)
درس 25: رگرسیون خطی با استفاده از PyTorch
درس 26: Pyspark – رگرسیون خطی با استفاده از آپاچی MLlib
درس 27: چالش دیتاست مسکن بوستون با استفاده از رگرسیون خطی
درس 28: پیادهسازی رگرسیون چندجمله ای با پایتون از پایه
درس 29: پیاده سازی رگرسیون چندجمله ای با پایتون
درس 30: رگرسیون چندجملهای برای داده های غیرخطی
درس 31: پیاده سازی رگرسیون چندجمله ای با Turicreate
درس 32: رگرسیون لجستیک در یادگیری ماشین
درس 33: رگرسیون لجستیک با استفاده از پایتون
درس 34: رگرسیون لجستیک با استفاده از tensorflow
درس 35: رگرسیون سافت مکس (Softmax) با استفاده از Tensorflow
درس 36: رگرسیون Softmax با استفاده از Keras
درس 37: دسته بندی کننده های بیز ساده (Naive Bayes)
درس 38: پیادهسازی بیز ساده (Naive Bayes) با استفاده از پایتون
درس 39: الگوریتم مکمل بیز ساده (CNB)
درس 40: کاربرد بیز ساده چند جملهای در NLP
درس 41:الگوریتم ماشین بردار پشتیبان (SVM)
درس 42: دستهبندی دادهها با استفاده از SVMها در پایتون
درس 43: تنظیم پارامترهای SVM با استفاده از GridSearchCV
درس 44: ایجاد SVM با کرنل خطی در پایتون
درس 45: توابع کرنل اصلی در SVM
درس ۴۶: استفاده از SVM برای دستهبندی در یک مجموعه داده غیرخطی
درس 47: درخت تصمیم (Decision Tree) چیست؟
درس 48: پیادهسازی درخت تصمیم با پایتون
درس 49: استفاده از رگرسیون درخت تصمیم با استفاده از sklearn
درس 50: رگرسیون جنگل تصادفی در پایتون
درس 51: ساخت طبقهبندیکننده جنگل تصادفی با کتابخانه Scikit-Learn
آموزش پیشنهادی و مکمل: دوره جامع متخصص علم داده

سوالات متداول
1- انواع دادههای مورد استفاده در یادگیری ماشین کدامند؟
در یادگیری ماشین، دادهها به چهار دسته اصلی تقسیم میشوند: دادههای عددی برای مقادیر قابل اندازهگیری، دادههای طبقهبندی شده برای دستهها یا گروهها، دادههای سری زمانی که بر اساس زمان مرتب شدهاند، و دادههای متنی که شامل متون مختلف هستند. هر نوع داده نیازمند روشها و الگوریتمهای خاص خود است. این دستهبندیها به درک و پردازش بهتر دادهها در مدلهای یادگیری ماشین کمک میکنند.
2- چرا پیشپردازش دادهها در یادگیری ماشین اهمیت دارد؟
مرحله پیشپردازش دادهها نقش حیاتی در موفقیت مدلهای یادگیری ماشین دارد، زیرا به تبدیل دادههای خام به فرمتهای ساختارمند و قابل استفاده کمک میکند. این فرآیند شامل تمیز کردن، نرمالسازی و انتخاب ویژگیها است که کیفیت دادهها را افزایش میدهد. در نتیجه مدلها قادر به ارائه پیشبینیهای دقیقتر و قابل اعتمادتر برای دادههای تست خواهند بود.
3- چه روشهایی برای پاکسازی دادههای یادگیری ماشین وجود دارد؟
پاکسازی دادهها در یادگیری ماشین شامل شناسایی و رفع خطاهای احتمالی، حذف دادههای نامرتبط و تکراری، و اصلاح ناهماهنگیها در فرمت دادهها است. تکنیکهایی مانند مدیریت دادههای گمشده، کنترل دادههای پرت، استانداردسازی فرمتها و حذف نمونههای اضافی به کار میروند تا کیفیت و دقت دادهها افزایش یابد. این فرآیند کمک میکند تا مدلهای یادگیری ماشین با دادههای باکیفیتتر آموزش داده شوند و پیشبینیهای دقیقتری ارائه دهند.
4- دادههای نامتوازن در یادگیری ماشین چه مشکلاتی ایجاد میکنند و چگونه میتوان آنها را مدیریت کرد؟
دادههای نامتوازن در یادگیری ماشین زمانی رخ میدهند که تعداد نمونههای یک کلاس به طور قابل توجهی کمتر یا بیشتر از کلاسهای دیگر باشد. این امر میتواند منجر به سوگیری الگوریتمها به سمت کلاس اکثریت شود و دقت پیشبینی کلاس اقلیت را کاهش دهد. برای مقابله با این مشکل میتوان از روشهایی مانند نمونهبرداری بیش از حد (Oversampling) کلاس اقلیت یا نمونهبرداری کمتر از حد (Undersampling) کلاس اکثریت، و الگوریتمهای خاص طراحی شده برای دادههای نامتوازن استفاده کرد.










