نیچ کورس آموزش رایگان یادگیری ماشین با پایتون برای شما چه یک مبتدی باشید، چه یک حرفهای باتجربه، یک پایه و اساس قوی و محکم در اصول یادگیری ماشین با استفاده از پایتون برای شما فراهم می کند.
در این آموزش، ما موضوعات گستردهای را پوشش میدهیم، از جمله مبانی برنامهنویسی پایتون و یادگیری ماشین، پردازش داده، یادگیری تحت نظارت، یادگیری بدون نظارت و کلی موارد دیگر.
نکات مهم شروع ماشین لرنینگ
نکات مهم برای شروع یادگیری ماشین عبارتند از:
مرحله
نکات مهم
۱. تقویت پایههای ریاضی و آماری
– یادگیری جبر خطی، حسابان و احتمال.
– درک مفاهیم آماری مانند توزیعها و رگرسیون.
– آشنایی با بهینهسازی (مانند Gradient Descent).
۲. یادگیری یک زبان برنامهنویسی
– تسلط بر پایتون (زبان اصلی یادگیری ماشین).
– آشنایی با کتابخانههایی مانند NumPy, Pandas, Matplotlib, Scikit-learn.
– استفاده از ابزارهایی مانند Jupyter Notebook یا Google Colab.
۳. درک مفاهیم پایه یادگیری ماشین
– جمعآوری دادهها از منابع مختلف.
– پاکسازی و پیشپردازش دادهها.
– انجام تحلیل اکتشافی داده (EDA) با استفاده از نمودارها و آمار.
۵. شروع با پروژههای کوچک
– انجام پروژههای ساده مانند پیشبینی قیمت خانه یا طبقهبندی ایمیلها.
– استفاده از دیتاستهای آماده مانند Iris یا MNIST.
– تمرین مداوم و پیادهسازی پروژههای مختلف.
۶. آشنایی با کتابخانهها و فریمورکها
– استفاده از Scikit-learn برای الگوریتمهای کلاسیک.
– یادگیری TensorFlow و PyTorch برای یادگیری عمیق.
– آشنایی با Keras برای ساخت مدلهای سادهتر.
۷. کشف یادگیری عمیق (Deep Learning)
– یادگیری مفاهیم شبکههای عصبی (پرسپترون، لایهها، توابع فعالسازی).
– کاربردهای یادگیری عمیق در بینایی کامپیوتر و پردازش زبان طبیعی.
– انجام پروژههای پیشرفته مانند تشخیص تصاویر یا تولید متن.
۸. تعامل با جامعه یادگیری ماشین
– شرکت در مسابقات Kaggle.
– مطالعه مقالات معروف از کنفرانسهایی مانند NeurIPS و ICML.
– عضویت در گروهها و فرومهای مرتبط (مانند Reddit یا Stack Overflow).
۹. یادگیری مستمر و بهروز بودن
– دنبال کردن آخرین تحقیقات و فناوریها در حوزه یادگیری ماشین.
– تمرین مداوم و بهبود مهارتها با انجام پروژههای جدید.
یادگیری ماشین به توانایی کامپیوتر برای یادگیری بدون نیاز به برنامهریزی صریح اشاره دارد. به عبارت سادهتر:
یادگیری ماشین به معنای اتوماتیک کردن فرآیند یادگیری کامپیوترها بر اساس تجربیاتشان بدون نیاز به مداخله انسانی توصیف میشود.
یادگیری ماشین به فعالیتهای متعددی در زندگی روزمره ما میپردازد و شاید در جاهای زیادی به کار رود که انسان ممکن است حتی تصورش را هم نتواند بکند.
شروع کار با یادگیری ماشین
از برنامههای ترجمه تا وسایل نقلیه خودران، یادگیری ماشین در همه جا حضور دارد که روشی است برای حل مسائل و پاسخ به سوالات پیچیده.به طور اساسی، این فرآیند به آموزش یک نرمافزار به نام الگوریتم یا مدل برای انجام پیشبینیهای مفید از دادهها میپردازد.
در درس اول می خواهیم در مورد دستهبندی مسائل یادگیری ماشین و اصطلاحات مورد استفاده در این زمینه صحبت کنیم.
سوالی که بیشتر از همه از ما پرسیده میشود این است که “چگونه شروع کنم؟”
بهترین توصیه من برای شروع در حوزه یادگیری ماشین به یک فرآیند ۵ مرحلهای تقسیم میشود:
مرحله ۱: تغییر ذهنیت
باور داشته باشید که میتوانید یادگیری ماشین را تمرین و پیادهسازی کنید.
چه چیزی شما را از اهداف یادگیری ماشین بازمیدارد؟
چرا یادگیری ماشین نباید سخت باشد؟
چگونه به یادگیری ماشین فکر کنیم؟
جامعه یادگیری ماشین خود را پیدا کنید.
مرحله ۲: یک فرآیند سیستماتیک انتخاب کنید
از یک فرآیند سیستماتیک برای حل مسائل استفاده کنید.
فرآیند یادگیری ماشین کاربردی را دنبال کنید.
مرحله ۳: یک ابزار انتخاب کنید
ابزاری متناسب با سطح خود انتخاب کنید و آن را با فرآیندتان تطبیق دهید.
مبتدیها: از Weka Workbench استفاده کنید.
سطح متوسط: از پایتون و اکوسیستم آن استفاده کنید.
پیشرفته: از پلتفرم R استفاده کنید.
بهترین زبان برنامهنویسی برای یادگیری ماشین را بررسی کنید.
مرحله ۴: روی مجموعه دادهها تمرین کنید
مجموعه دادههایی را انتخاب کنید و روی آنها تمرین کنید.
تمرین یادگیری ماشین با مجموعه دادههای کوچک در حافظه.
آشنایی با مسائل یادگیری ماشین در دنیای واقعی.
روی مسائل یادگیری ماشین کار کنید که برای شما مهم هستند.
مرحله ۵: یک پورتفولیو بسازید
نتایج خود را جمعآوری کنید و مهارتهای خود را نمایش دهید.
یک پورتفولیو یادگیری ماشین بسازید.
با استفاده از یادگیری ماشین درآمد کسب کنید.
یادگیری ماشین برای کسب درآمد.
برای اطلاعات بیشتر درباره این رویکرد از بالا به پایین، میتوانید به موارد زیر مراجعه کنید:
روش تسلط بر یادگیری ماشین
یادگیری ماشین برای برنامهنویسان
بسیاری از کارآموزان ما از این روش استفاده کرده و در رقابتهای Kaggle موفق شدهاند یا به عنوان مهندس یادگیری ماشین و دانشمند داده مشغول به کار شدهاند.
انواع مسائل یادگیری ماشین
برای دستهبندی مسائل یادگیری ماشین روشهای مختلفی وجود دارد. در اینجا، ما به مهمترین روشها پرداختهایم.
1- بر اساس ماهیت “سیگنال” یا “بازخورد” موجود برای یک سیستم یادگیری:
یادگیری نظارت شده (Supervised Learning)
در این حالت، مدل یا الگوریتم با ورودیها و خروجیهای مورد نظر به عنوان نمونه مواجه میشود و سپس الگوها و ارتباطات بین ورودی و خروجی را پیدا میکند. فرآیند آموزش ادامه دارد تا مدل به دقت مطلوب در دادههای آموزش برسد.
مثالهای واقعی:
طبقهبندی تصویر: پس از آموزش مدل با تصاویر و برچسبهای آنها، تصویر جدیدی را وارد میکنید و انتظار دارید کامپیوتر شیء جدید را تشخیص دهد.
پیشبینی یا رگرسیون بازار: با آموزش کامپیوتر با دادههای تاریخی بازار و خواستن از کامپیوتر برای پیشبینی قیمت در آینده.
یادگیری بدون نظارت (Unsupervised Learning)
در این حالت، برای الگوریتم یادگیری هیچ برچسبی داده نمیشود و او به تنهایی سعی در یافتن ساختار در ورودیها دارد.
مثالهای واقعی:
خوشهبندی: شما از کامپیوتر میخواهید که دادههای مشابه را به خوشهها تفکیک کند، این امر در تحقیقات و علم بسیار مفید است.
تجسم ابعاد بالا: استفاده از کامپیوتر برای کمک به تجسم دادههای با ابعاد بالا.
مدلهای تولیدی: پس از اینکه یک مدل توزیع احتمال دادههای ورودی شما را فرا گیرد، قادر به تولید دادههای بیشتر خواهد بود که میتواند بسیار مفید باشد تا طبقهبندی کننده شما را قویتر کند.
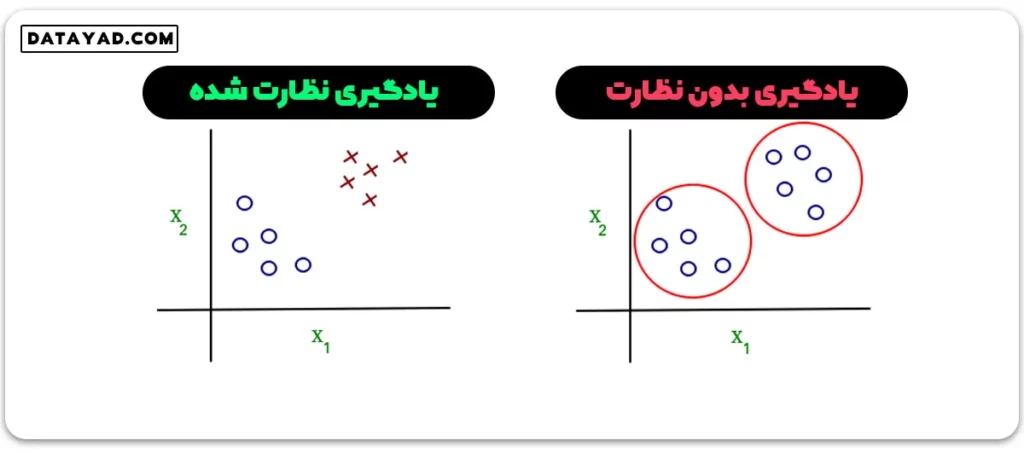
یک نمودار ساده که مفهوم یادگیری نظارت شده و بدون نظارت را واضح میکند، در زیر نمایش داده شده است:
همانطور که به وضوح مشاهده میشود، دادهها در یادگیری نظارت شده دارای برچسب هستند، در حالی که دادههای یادگیری بدون نظارت بدون برچسب هستند.
یادگیری نیمه نظارتی (Semi-supervised Learning)
مسائلی که دارای حجم زیادی از دادههای ورودی هستند و تنها برخی از این دادهها دارای برچسب هستند، به عنوان مسائل یادگیری نیمه نظارتی شناخته میشوند.
یادگیری نیمه نظارتی (Semi-Supervised Learning) یکی از روشهای یادگیری ماشین است. این نوع از یادگیری ترکیبی از یادگیری نظارتی (Supervised Learning) و یادگیری بدون نظارت (Unsupervised Learning) میباشد. در این روش از دادههای برچسبدار و بدون برچسب به صورت همزمان برای آموزش مدل استفاده میشود. اغلب حجم دادههای بدون برچسب خیلی بیشتر از دادههای برچسبدار است. در ابتدا مدل از دادههای برچسبدار برای یادگیری الگوهای اولیه استفاده میکند و سپس با بهرهگیری از دادههای بدون برچسب، این الگوها را بهبود میبخشد. این روش در مواردی مفید است که جمعآوری دادههای برچسبدار پرهزینه یا زمانبر باشد، در این حالت دسترسی به دادههای بدون برچسب آسانتر است. برای درک بهتر پردازش داده در مدلهای یادگیری توصیه میکنیم تفاوت یادگیری ماشین و یادگیری عمیق را مطالعه کنید.
یادگیری نیمه نظارتی از تکنیکهای مختلفی مثل انتشار برچسب (Label Propagation)، یادگیری مبتنی بر گراف (Graph-Based Learning) و مدلهای تولیدی (Generative Models) بهره میبرد. در روش انتشار برچسب، برچسبهای دادهها به دادههای بدون برچسب مجاور انتقال مییابند. در یادگیری مبتنی بر گراف، دادهها به صورت گراف نمایش داده میشوند و برچسبها از طریق ارتباطات بین گرهها انتشار مییابند. مدلهای تولیدی نیز سعی دارند توزیع دادهها را یاد بگیرند و از این طریق برچسبهای دادههای بدون برچسب را پیشبینی کنند. این روشها به مدل کمک میکند تا با استفاده از اطلاعات موجود در دادههای بدون برچسب، دقت و عملکرد بهتری در پیشبینیها داشته باشد.
این مسائل در واقع در میانه بین دو نوع یادگیری نظارت شده و یادگیری بدون نظارت قرار دارند. به عنوان مثال، یک آرشیو تصاویر که تنها برخی از تصاویر دارای برچسب هستند (مثلاً سگ، گربه، انسان) و اکثریت آنها بدون برچسب هستند.
یادگیری تقویتی (Reinforcement Learning)
یک برنامه کامپیوتر با یک محیط پویا تعامل میکند که در آن باید یک هدف خاص را انجام دهد (مانند رانندگی یک وسیله نقلیه یا بازی با یک حریف). این برنامه به عنوان بازخورد در طول مسیریابی در فضای مسئله خود، از طریق پاداشها و مجازاتها تغذیه میشود.
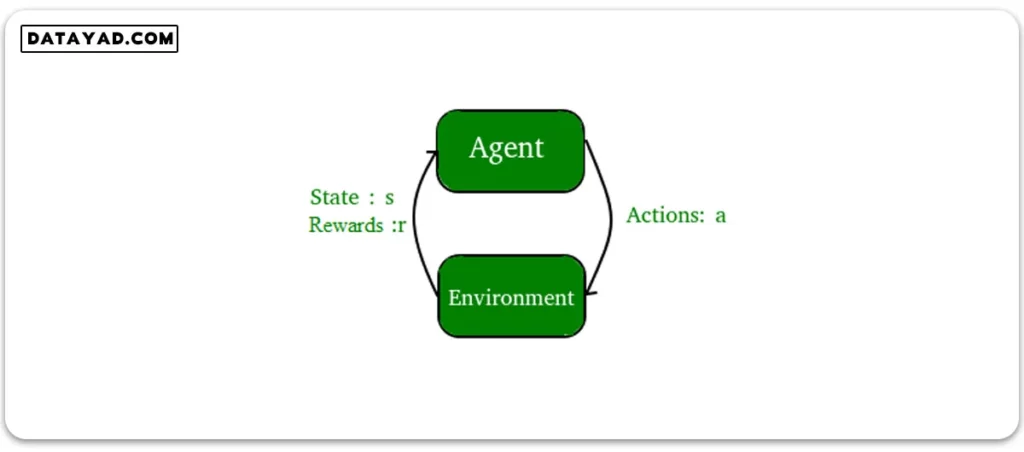
همان طور که در آموزش رایگان پایتون نیز گفتیم یادگیری تقویتی (Reinforcement Learning) یکی از اصلیترین روشهای یادگیری ماشین است که در آن یک عامل (Agent) با محیط (Environment) در ارتباط است تا به هدف مشخصی برسد. در این روش، عامل با انجام اقدامات (Actions) و دریافت بازخورد (Feedback) از محیط به شکل پاداش (Reward) یا جریمه (Penalty)، سعی میکند یک سیاست (Policy) بهینه را یاد بگیرد که حداکثر پاداش تجمعی را در طول زمان به دست آورد. برخلاف یادگیری نظارتی که در آن دادههای برچسبدار به مدل ارائه میشود، در یادگیری تقویتی عامل از طریق آزمون و خطا و تعامل مستقیم با محیط یاد میگیرد. این روش به ویژه در مسائلی مانند بازیها، رباتیک، کنترل سیستمهای پویا و تصمیمگیریهای پیچیده کاربرد دارد. اگر نیاز به یادگیری بیشتری دارید آموزش رایگان شبکه عصبی را بخوانید.
یادگیری تقویتی بر پایه مفاهیمی مانند حالت (State)، اقدام (Action)، پاداش (Reward) و سیاست (Policy) استوار است. عامل در هر گام بر اساس حالت فعلی محیط، اقداماتی را انجام میدهد و به حالت جدیدی منتقل میشود. سپس پاداش مربوط به آن اقدام را دریافت میکند. هدف عامل این است که با بهروزرسانی سیاست خود، ارزش (Value) اقدامات و حالتها را به گونهای محاسبه کند که در بلندمدت بیشترین پاداش ممکن را کسب کند. الگوریتمهای یادگیری ماشین مثل Q-Learning، Deep Q-Networks (DQN) و Policy Gradient در این حوزه استفاده میشوند. یادگیری تقویتی به دلیل توانایی در حل مسائل پیچیده و پویا، یکی از جذابترین و چالشبرانگیزترین حوزههای یادگیری ماشین محسوب میشود. برای درک بهتر مهم ترین کاربرد های پایتون را مطالعه کنید.
2- دو مورد از رایجترین موارد استفاده از یادگیری نظارت شده به شرح زیر هستند:
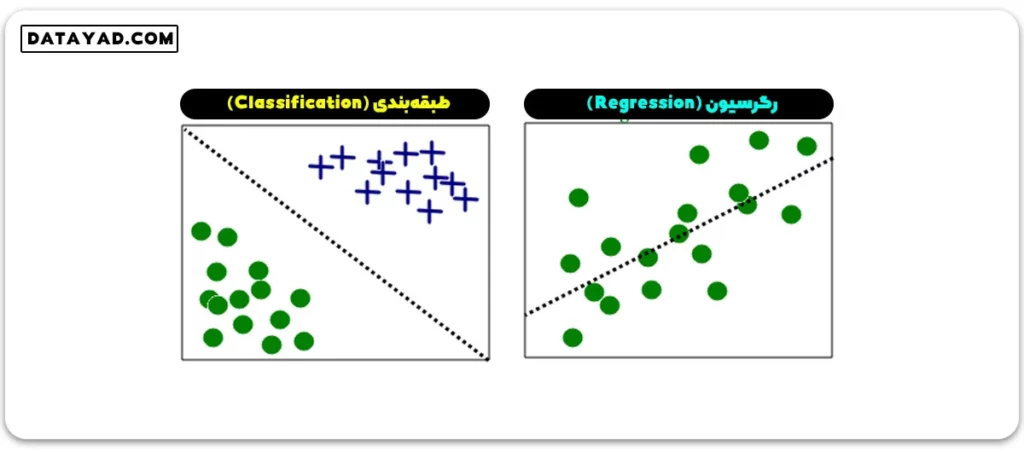
طبقهبندی (Classification)
ورودیها به دو یا چند کلاس تقسیم میشوند و یادگیرنده باید یک مدل ایجاد کند که ورودیهای ناشناخته را به یک یا چندین (طبقهبندی چندبرچسبه) از این کلاسها تخصیص دهد و پیشبینی کند که آیا چیزی به یک کلاس خاص تعلق دارد یا خیر.
معمولاً این مسئله به شکل نظارتی حل میشود. مدلهای طبقهبندی به دو دسته دودویی (Binary Classification) و چندکلاسه (Multiclass Classification) تقسیم میشوند.
به عنوان مثال، فیلتر کردن اسپم یک مثال از دستهبندی دودویی است، جایی که ورودیها پیامهای ایمیل (یا دیگر پیامها) هستند و کلاسها “اسپم” و “غیر اسپم” هستند.
رگرسیون (Regression)
یک مسئله یادگیری نظارت شده است که یک مقدار عددی را پیشبینی میکند و خروجیها پیوسته هستند. به عنوان مثال، پیشبینی قیمتهای سهام با استفاده از دادههای تاریخی.
یک مثال از طبقهبندی و رگرسیون با استفاده از دو مجموعه داده متفاوت، در شکل زیر نمایش داده شده است:
3- معمولترین موارد یادگیری بدون نظارت به شرح زیر هستند:
خوشهبندی (Clustering)
در اینجا، یک مجموعه از ورودیها باید به گروهها تقسیم شود. برخلاف طبقهبندی، گروهها از پیش شناخته نشدهاند، که این امر معمولا وظیفه یادگیری بدون نظارت است.
تخمین چگالی (Density Estimation)
کار آن در اینجا پیدا کردن توزیع ورودیها در فضا است.
کاهش ابعاد (Dimensionality Reduction)
این وظیفه با تبدیل ورودیها به یک فضای با بعد کمتر، ورودیها را سادهتر میکند. یک مسئله مرتبط، مدلسازی موضوعی است که در آن یک لیست از اسناد زبان انسان به یک برنامه داده میشود و این برنامه مسئولیت دارد تا موضوعات مشابه را بیابد.
بر اساس این مسائل و وظایف یادگیری ماشین، یک سری الگوریتم وجود دارند که برای انجام این وظایف استفاده میشوند. برخی از الگوریتمهای معمول در یادگیری ماشین شامل:
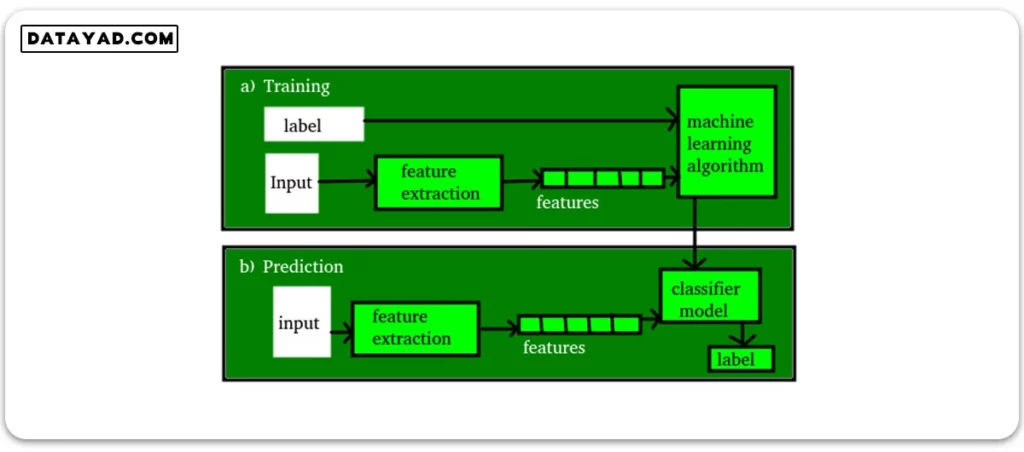
مدل (Model): مدل، نمایش خاصی است که از دادهها با استفاده از برخی الگوریتمهای یادگیری ماشین ساخته میشود. مدل گاهی به عنوان فرضیه نیز نامیده میشود.
ویژگی (Feature): ویژگی، خاصیت قابل اندازهگیری از دادهها است. مجموعهای از ویژگیهای عددی میتوانند به راحتی توسط یک بردار ویژگی توصیف شوند. بردارهای ویژگی به عنوان ورودی به مدل داده میشوند. به عنوان مثال، برای پیشبینی نوع یک میوه، ویژگیهایی مانند رنگ، بو، طعم و غیره وجود دارد. توجه: انتخاب ویژگیهای معنیدار، تمایزی و مستقل یک مرحله مهم برای الگوریتمهای موثر است. معمولا از یک استخراج کننده ویژگی برای استخراج ویژگیهای مرتبط از دادههای خام استفاده میشود.
هدف یا برچسب (Target or Label): متغیر هدف یا برچسب، مقداری است که مدل باید پیشبینی کند. به عنوان مثال، در مورد پیشبینی نوع میوه که در بخش ویژگیها بحث شده است، برچسب با هر مجموعه ورودی نام میوه مثل سیب، پرتقال، موز و غیره خواهد بود.
آموزش (Training): بناست تا مجموعهای از ورودیها (ویژگیها) و خروجیهای مورد انتظار (برچسبها) را به مدل دهیم. بنابراین پس از آموزش، مدلی (فرضیه) خواهیم داشت که سپس دادههای جدید را به یکی از دستههایی که در آموزش دیده است، مرتبط خواهد کرد.
پیشبینی (Prediction): هنگامی که مدل آماده باشد، میتواند یک مجموعه ورودی را دریافت کرده و خروجی پیشبینی شده (برچسب) را ارائه دهد. اما حتماً مطمئن شوید که اگر ماشین بر روی دادههای جدید عملکرد خوبی داشته باشد، آنگاه میتوان گفت که ماشین عملکرد خوبی دارد.
شکل زیر، مفاهیم بالا را روشن میکند:
مراحل شروع کار با یادگیری ماشین
مراحل شروع کار با یادگیری ماشین به شرح زیر است:
تعریف مسئله: مسئله مورد نظر خود را مشخص کنید و ارزیابی کنید که آیا از یادگیری ماشین می توان برای حل آن استفاده کرد یا خیر.
جمعآوری داده: دادهها را جمعآوری کنید و آنها را برای آموزش مدل خود تمیز کنید. کیفیت مدل شما به کیفیت دادههای شما بستگی دارد.
بررسی داده: از تجسم داده و روشهای آماری برای درک ساختار و روابط در دادههایتان استفاده کنید.
پیشپردازش داده: دادهها را برای مدلسازی آماده کنید، از جمله نرمالسازی، تبدیل و پاکسازی دادهها به میزان نیاز.
تقسیم داده: دادهها را به مجموعههای آموزش و آزمون تقسیم کنید تا مدل خود را اعتبارسنجی کنید.
انتخاب مدل: یک مدل یادگیری ماشین مناسب برای مسئله و دادههای جمعآوری شده انتخاب کنید.
آموزش مدل: از دادههای آموزش برای آموزش مدل استفاده کنید و پارامترهای آن را طوری تنظیم کنید تا به بالاترین دقت ممکن برسد.
ارزیابی مدل: از دادههای آزمون برای ارزیابی عملکرد مدل و تعیین دقت آن استفاده کنید.
تنظیم دقیق مدل: بر اساس نتایج ارزیابی، مدل را با تنظیم مجدد پارامترهای آن و تکرار مراحل آموزش تا دستیابی به سطح دقت مورد نظر بهبود دهید.
راهاندازی مدل: مدل را به برنامه یا سیستم خود ادغام کنید تا برای دیگران قابل استفاده باشد.
نظارت بر مدل: به صورت مداوم عملکرد مدل را نظارت کنید تا اطمینان حاصل کنید که با گذر زمان به نتایج دقیق ادامه میدهد.
فرآیند یادگیری ماشین کاربردی مزایای بسیار زیادی دارد.
مهمترین مزیت یادگیری ماشین، پیشبینیها و مدلهایی است که این پیشبینیها را انجام میدهند.
مهارت در یادگیری ماشین کاربردی به این معناست که بدانید چگونه به طور مداوم و قابل اعتماد، پیشبینیهای با کیفیت بالا را برای مسائل مختلف ارائه دهید. برای این کار باید یک فرآیند سیستماتیک را دنبال کنید.
در زیر یک فرآیند ۵ مرحلهای آورده شده است که میتوانید برای دستیابی به نتایج بهتر از حد متوسط در مسائل مدلسازی پیشبینانه از آن استفاده کنید:
مرحله ۱: مسئله خود را تعریف کنید.
چگونه مسئله یادگیری ماشین خود را تعریف کنید.
مرحله ۲: دادههای خود را آماده کنید.
چگونه دادهها را برای یادگیری ماشین آماده کنید.
چگونه دادههای پرت را شناسایی کنید.
بهبود دقت مدل با پیشپردازش دادهها.
آشنایی با مهندسی ویژگیها.
مقدمهای بر انتخاب ویژگیها.
راهکارهایی برای مقابله با کلاسهای نامتوازن در دادههای یادگیری ماشین.
نشت داده در یادگیری ماشین.
مرحله ۳: الگوریتمها را آزمایش کنید.
چگونه الگوریتمهای یادگیری ماشین را ارزیابی کنید.
چرا باید الگوریتمها را در مسائل یادگیری ماشین آزمایش کنید.
چگونه گزینههای تست مناسب را هنگام ارزیابی الگوریتمهای یادگیری ماشین انتخاب کنید.
یک رویکرد دادهمحور برای انتخاب الگوریتمهای یادگیری ماشین.
مرحله ۴: نتایج را بهبود بخشید.
چگونه نتایج یادگیری ماشین را بهبود دهید.
چکلیست بهبود عملکرد یادگیری ماشین.
چگونه عملکرد یادگیری عمیق را بهبود دهید.
مرحله ۵: نتایج را ارائه دهید.
چگونه از نتایج یادگیری ماشین استفاده کنید.
چگونه یک مدل نهایی یادگیری ماشین را آموزش دهید.
چگونه مدل پیشبینانه خود را در محیط عملیاتی مستقر کنید.
مثال ساده
در ادامه، یک مثال ساده از یادگیری ماشین با پایتون آورده شده است که نشان میدهد چگونه یک مدل را برای پیشبینی گونه گلهای آیریس بر اساس اندازهگیریهای گلبرگ و سپال (کاسبرگ) آنها آموزش دهیم:
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.datasets import load_iris
# Load the iris dataset from scikit-learn
iris = load_iris()
X = iris.data
y = iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# Create an SVM model and train it
model = SVC()
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print('Test accuracy:', accuracy)
1-برای شروع یادگیری ماشین به چه پیشنیازهایی نیاز دارم؟
برای شروع یادگیری ماشین به دانش کافی در زمینه ریاضیات (جبر خطی، آمار و حسابان)، برنامهنویسی (ترجیحاً پایتون یا R) و درک اولیه از مفاهیم دادهها و الگوریتمها نیاز دارید. همچنین آشنایی با کتابخانههایی مثل NumPy، Pandas و Scikit-Learn هم میتواند براینان مفید باشد.
2-بهترین منابع برای یادگیری ماشین برای مبتدیان کدامند؟
برای مبتدیان، دورههای آنلاین مثل “Machine Learning by Andrew Ng” در Coursera و کتابهایی مانند “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” توسط Aurélien Géron بسیار مناسب هستند. همچنین وبسایتهایی مثل Kaggle و Towards Data Science منابع عالی برای یادگیری عملی و مقالات آموزشی شناخته میشوند.
3-چه زبانهای برنامهنویسی برای یادگیری ماشین مناسبتر هستند؟
پایتون به دلیل کتابخانههای قدرتمندی مثل Scikit-Learn، TensorFlow و PyTorch که دارد بهترین زبان برای یادگیری ماشین است. R نیز برای تحلیلهای آماری و مصورسازی دادهها گزینه مناسبی است، اما پایتون انعطافپذیری و جامعه کاربری بیشتری دارد.
4-چگونه میتوان یک پروژه عملی در یادگیری ماشین ایجاد کرد؟
برای ساخت یک پروژه عملی در یادگیری ماشین، ابتدا یک مسئله واقعی را انتخاب کنید و دادههای مرتبط را جمعآوری یا از مجموعهدادههای موجود (مانند Kaggle) کمک بگیرید. سپس مراحل پیشپردازش داده، انتخاب مدل، آموزش و ارزیابی را با استفاده از ابزارهایی مثل پایتون و کتابخانههای Scikit-Learn یا TensorFlow انجام دهید.



















یک پاسخ
عالی